一、引子
坚持到底就是胜利,终于我们⼀起来到了专栏的最后一个主题。让我一起带你来看一看,CPU到底能有多快。在接下来的两讲里,我会带你一起来看一个开源项目Disruptor。
看看我们怎么利用CPU和高速缓存的硬件特性,来设计一个对于性能有极限追求的系统。
不知道你还记不记得,在第37讲里,为了优化4毫秒专用铺设光纤的故事。实际上,最在意极限性能的并不是互联网公司,而是高频交易公司。我们今天讲解的Disruptor就是由一家专门
做高频交易的公司LMAX开源出来的。
有意思的是,Disruptor的开发语言,并不是很多人心目中最容易做到性能极限的C/C++,而是性能受限于JVM的Java。这到底是怎么意回事呢?那通过这意讲,
你就能体会到,其实只要通晓硬件层面的原理,即使是像Java这样的高级语言,也能够把CPU的性能发挥到极限。
二、PaddingCache Line,体验高速缓存的威力
我们先来看看Disruptor里面一段神奇的代码。这段代码里,Disruptor在RingBufferPad这个类里面定义了p1,p2一直到p7这样7个long类型的变量。
abstract class RingBufferPad
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
1、缓存行填充
我在看到这段代码的第一反应是,变量名取得不规范,p1-p7这样的变量名没有明确的意义啊。不过,当我深入了解了Disruptor的设计和源代码,才发现这些变量名取得恰如其分。因为这些变量就是没有实际意
义,只是帮助我们进行缓存行填充(Padding Cache Line),使得我们能够尽可能地用上CPU高速缓存(CPU Cache)。那么缓存存填充这个黑科技到底是什么样的呢?我们接着往下看。
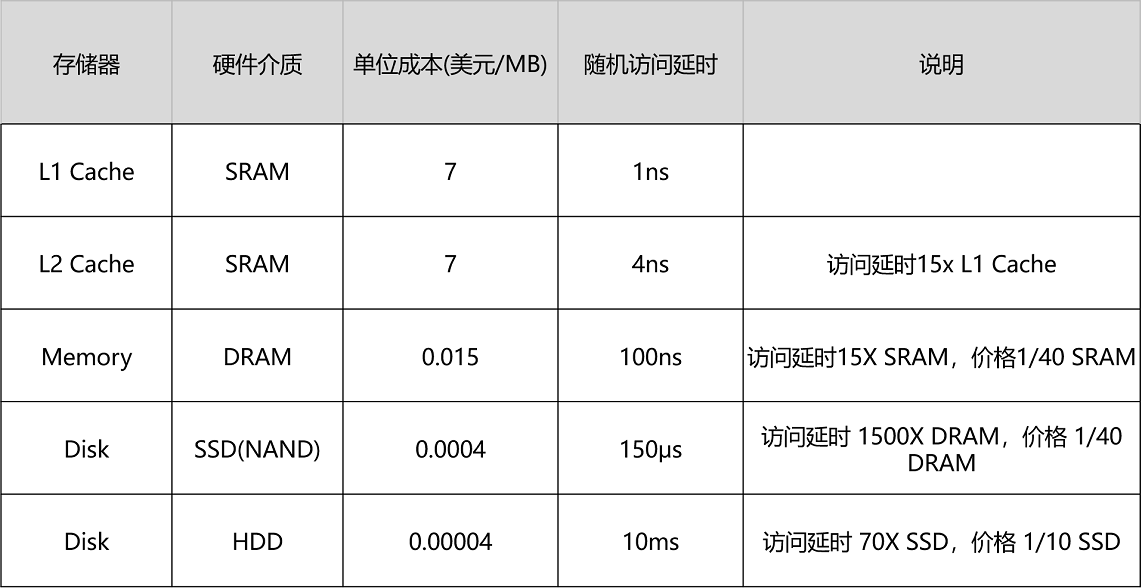
不知道你还记不记得,我们在35讲里面的这个表格。如果访问内置在CPU里的L1 Cache或者L2 Cache,访问延时是内存的1/15乃至1/100。而内存的访问速度,其实是远远慢于CPU的。
想要追求极限性能,需要我们尽可能地多从CPU Cache里面拿数据,而不是从内存里面拿数据。
2、CPU从内存加载数据到CPU Cache里面的时候,不是一个变量一个变量加载的,而是加载固定长度的CacheLine
CPU Cache装载内存里面的数据,不是一个一个字段加载的,而是加载一整个缓存存。举个例子,如果我们定义了一个长度为64的long类型的数组。那么数据从内存加载到CPU Cache里面的时候,
不是一个一个数组元素加载的,而是一次性加载固定长度的一个缓存行。
我们现在的64位Intel CPU的计算机,缓存行通常是64个字节(Bytes)。一个long类型的数据需要8个字节,所以我们一下子会加载8个long类型的数据。也就是说,一次加载数组里面连续的8个数值。
这样的加载方式使得我们遍历数组元素的时候会很快。因为后面连续7次的数据访问都会命中缓存,不需要重新从内存里面去读取数据。这个性能层面的好处,我在第37讲的第一个例子里面为你演示过,印象不深的话,可以返回去看看。
3、对于类里面定义的单独的变量,就不容易享受到CPU Cache红利了
但是,在我们不是使用数组,而是使用单独的变量的时候,这里就会出现问题了。在Disruptor的RingBuffer(环形缓冲区)的代码里面,定义了一个单独的long类型的变量。
这个变量叫作INITIAL_CURSOR_VALUE,用来存放RingBuffer起始的元素位置。
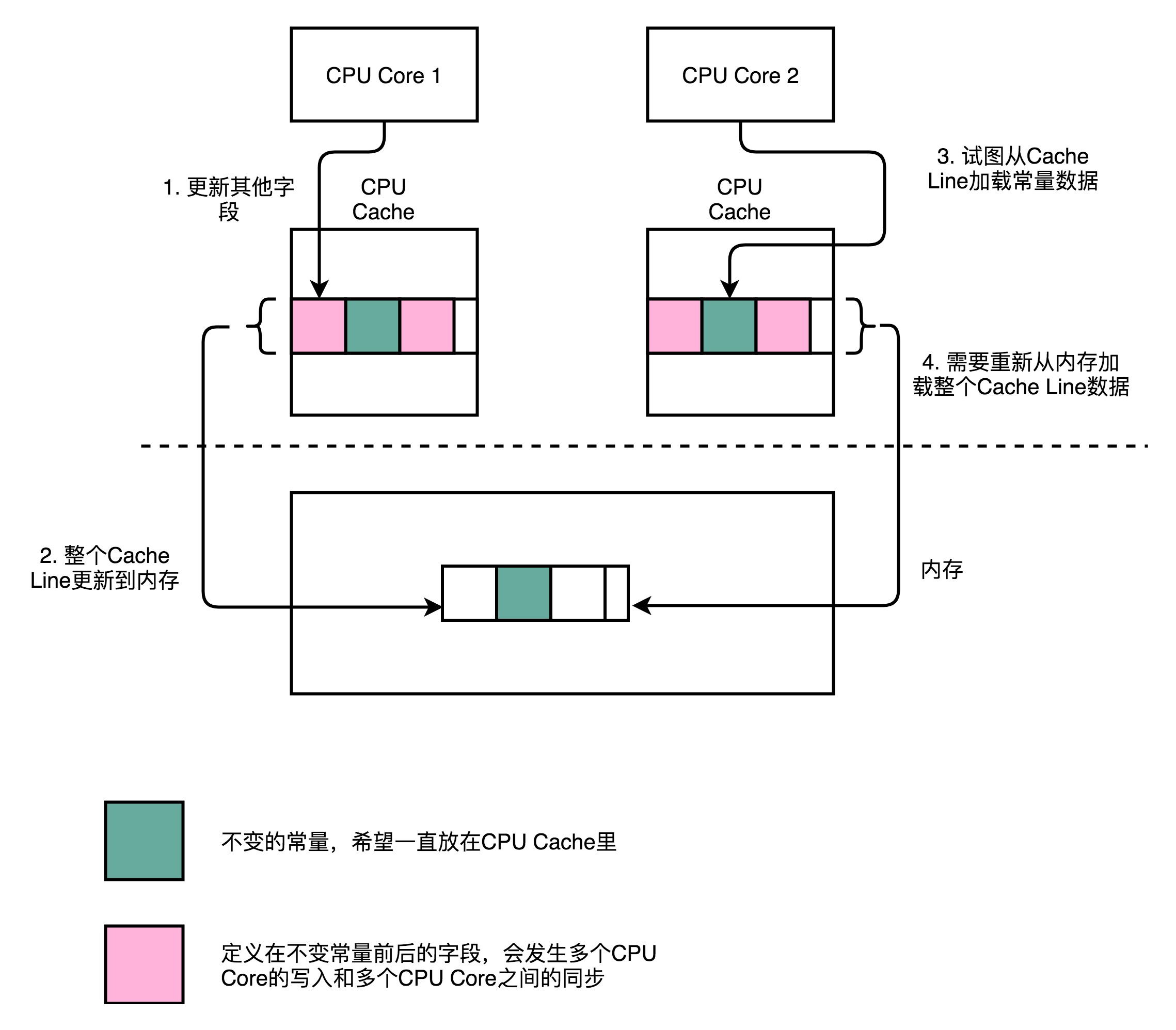
CPU在加载数据的时候,自然也会把这个数据从内存加载到高速缓存里面来。不过,这个时候,高速缓存里面除了这个数据,还会加载这个数据前后定义的其他变量。这个时候,问题就来了。
Disruptor是一个多线程的服务器框架,在这个数据前后定义的其他变量,可能会被多个不同的线程去更新数据、读取数据。这些
写入以及读取的请求,会来自于不同的CPU Core。于是,为了保证数据的同步更新,我们不得不把CPUCache里面的数据,重新写回到内存里面去或者重新从内存里面加载数据。
而我们刚刚说过,这些CPU Cache的写回和加载,都不是以一个变量作为单位的。这些动作都是以整个Cache Line作为单位的。所以,当INITIAL_CURSOR_VALUE前后的那些变量被写回到内存的时候,
这个字段自己也写回到了内存,这个常量的缓存也就失效了。当我们要再次读取这个值的时候,要再重新从内存读取。这也就意味着,读取速度大大变慢了。
......
abstract class RingBufferPad
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad
{
......
}
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E>
{
public static final long INITIAL_CURSOR_VALUE = Sequence.INITIAL_VALUE;
protected long p1, p2, p3, p4, p5, p6, p7;
......
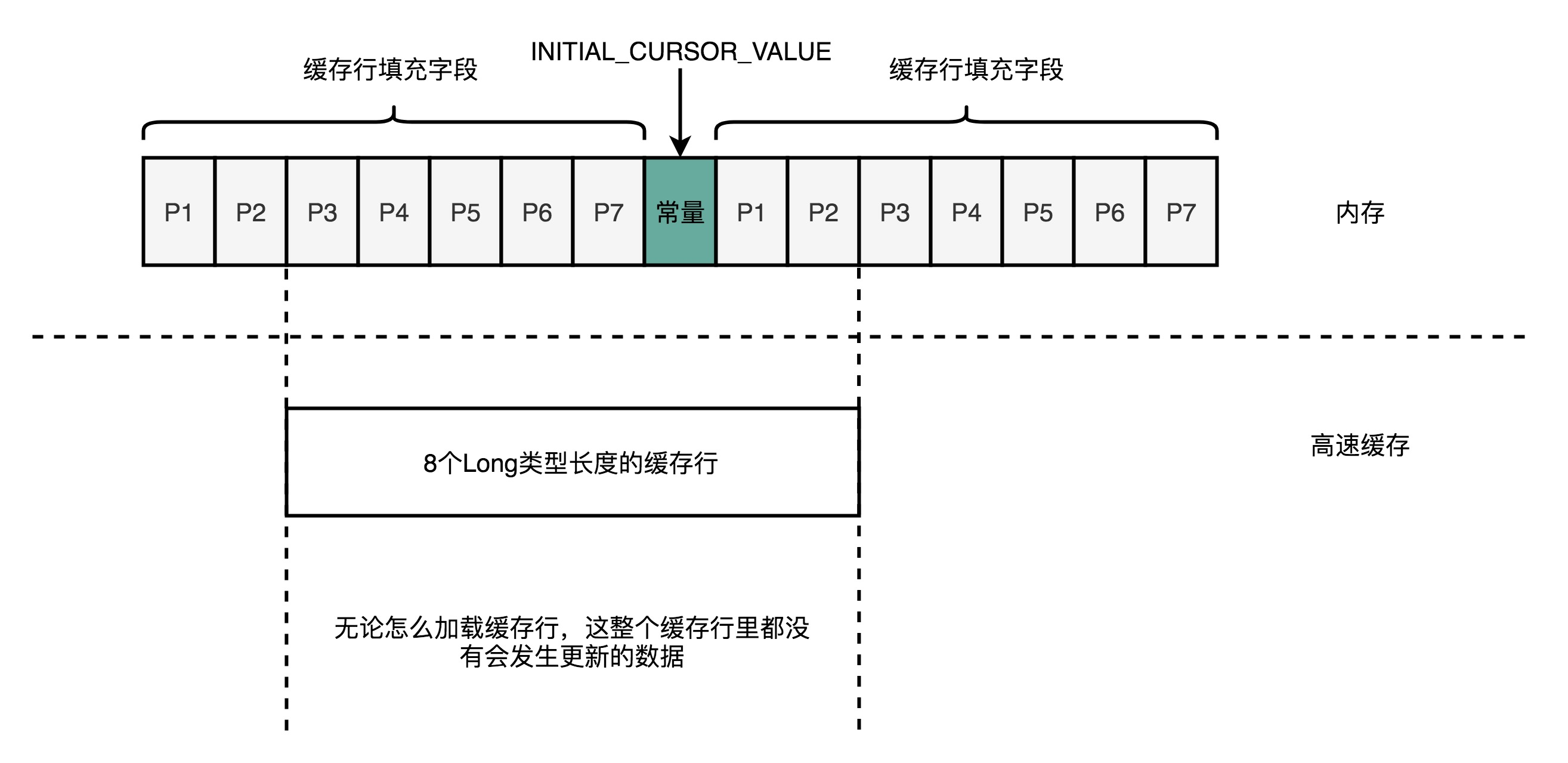
面临这样一个情况,Disruptor里发明了一个神奇的代码技巧,这个技巧就是缓存行填充。Disruptor在INITIAL_CURSOR_VALUE的前后,分别定义了7个long类型的变量。前面的7个来自继承的RingBufferPad
类,后面的7个则是直接定义在RingBuffer类里面。这14个变量没有任何实际的用途。我们既不会去读他们,也不会去写他们。
而INITIAL_CURSOR_VALUE又是一个常量,也不会进行修改。所以,一旦它被加载到CPU Cache之后,只要被频繁地读取访问,就不会再被换出Cache了。这也就意味着,对于这个值的读取速度,
会是一直是CPUCache的访问速度,而不是内存的访问速度。
三、使用RingBuffer,利用缓存和分支预测
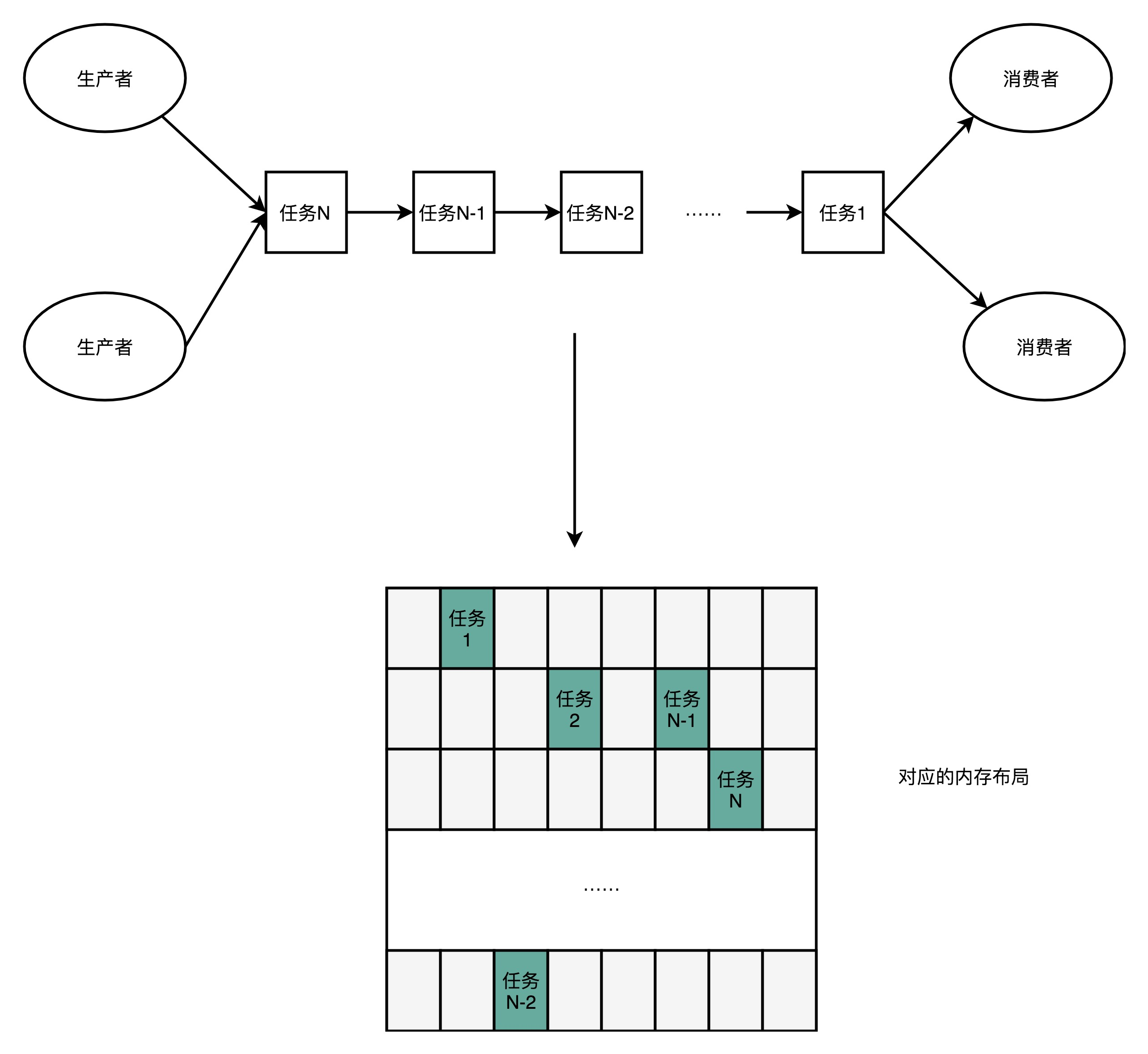
其实这个利用CPU Cache的性能的思路,贯穿了整个Disruptor。Disruptor整个框架,其实就是一个高速的生产者-消费者模型(Producer-Consumer)下的队列。
生产者不停地往队列里面生产新的需要处理的任务,而消费者不停地从队列里面处理掉这些任务。
1、要实现一个队列,最合适的数据结构应该是链表
如果你熟悉算法和数据结构,那你应该非常清楚,如果要实现一个队列,最合适的数据结构应该是链表。我们只要维护好链表的头和尾,就能很容易实现一个队列。
生产者只要不断地往链表的尾部不断插入新的节点,而消费者只需要不断从头部取出最老的节点进行处理就好了。我们可以很容易实现生产者-消费者模型。实际上,
Java自己的基础库里面就有LinkedBlockingQueue这样的队列库,可以直接用在生产者-消费者模式上。
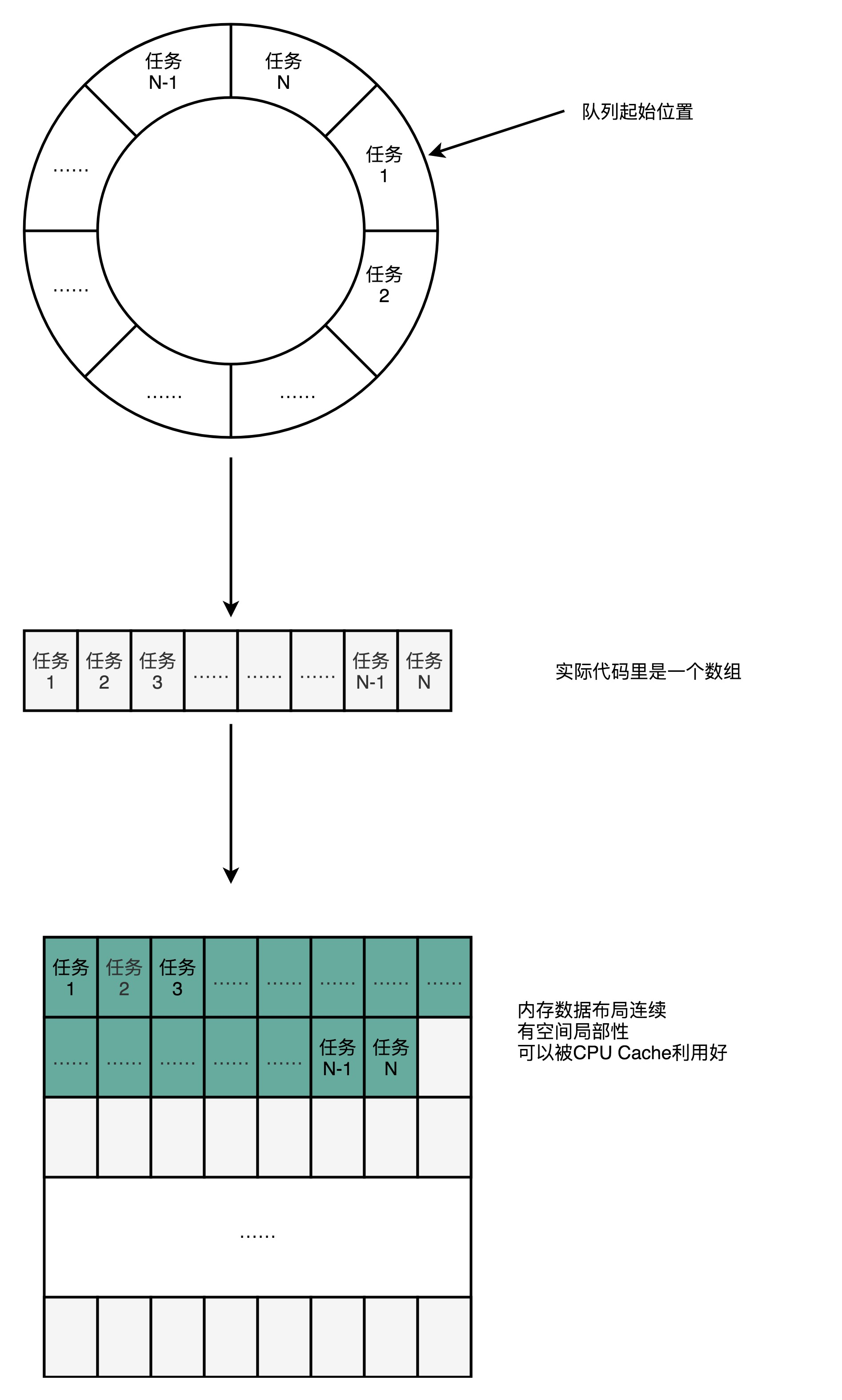
2、Disruptor里面并没有用LinkedBlockingQueue,而是使用了一个RingBuffer这样的数据结构
不过,Disruptor里面并没有用LinkedBlockingQueue,而是使用了一个RingBuffer这样的数据结构,这个RingBuffer的底层实现则是一个固定长度的数组。比起链表形式的实现,
数组的数据在内存里面会存在空间局部性。
就像上面我们看到的,数组的连续多个元素会一并加载到CPU Cache里面来,所以访问遍历的速度会更快。而链表里面各个节点的数据,多半不会出现在相邻的内存空间,
自然也就享受不到整个Cache Line加载后数据连续从高速缓存存里被访问到的优势。
除此之外,数据的遍历访问还有一个很大的优势,就是CPU层面的分支预测会很准确。这可以使得我们更有这一部分的原理如果你已经不太记得了,
可以回过头去复习一下第25讲关于分支预测的内容。
四、总结延伸
好了,不知道讲完这些,你有没有体会到Disruptor这个框架的神奇之处呢?
CPU从内存加载数据到CPU Cache里面的时候,不是一个变量一个变量加载的,而是加载固定长度的CacheLine。如果是加载数组里面的数据,那么CPU就会加载到数组里面连续的多个数据。
所以,数组的遍历很容易享受到CPU Cache那风驰电掣的速度带来的红利。
对于类里面定义的单独的变量,就不容易享受到CPU Cache红利了。因为这些字段虽然在内存层面会分配到一起,但是实际应用的时候往往没有什么关联。于是,就会出现多个CPU Core访问的情况下,
数据频繁在CPU Cache和内存里面来来回回的情况。而Disruptor很取巧地在需要频繁高速访问的常量
INITIAL_CURSOR_VALUE 前后,各定义了7个没有任何作⽤和读写请求的long类型的变量。
这样,无论在内存的什么位置上,这个INITIAL_CURSOR_VALUE所在的CacheLine都不会有任何写更新的请求。我们就可以始终在Cache Line里面读到它的值,而不需要从内存里面去读取数据,
也就大大加速了Disruptor的性能。
这样的思路,其实渗透在Disruptor这个开源框架的方方面面。作为一个生产者-消费者模型,Disruptor并没有选择使用链表来实现一个队列,而是使用了RingBuffer。
RingBuffer底层的数据结构则是一个固定长度的数组。这个数组不仅让我们更容易用好CPU Cache,对CPU执行过程中的分支预测也非常有利。更准确的分支预测,
可以使得我们更好地利用好CPU的流水线,让代码跑得更快。