前置:https://www.cnblogs.com/luocodes/p/11827850.html
解决最后一个问题,如何将scrapy真正的打包成单文件
耗了一晚上时间,今天突然有灵感了
错误分析
不将scrapy.cfg文件与可执行文件放一起,那么就会报错---爬虫没有找到
报错的原因
1.scrapy.cfg文件放入不进可执行文件中
2.scrapy目录读取不到scrapy.cfg文件
问题1
pyinstaller是将可执行文件解压到系统的临时文件中,在进行运行的
所以我们只需要在可执行文件中找到它的目录就能了解我们打包的文件中到底包含了什么
这里还有一个问题,每当可执行文件运行完毕后,它产生的temp文件将会被删除,所以我们在start.py中加一下输入
这样一来程序不退出,临时文件也随之保留了下来,方便我们查看
# -*- coding: utf-8 -*- from scrapy.cmdline import execute from scrapy.utils.python import garbage_collect from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings # import robotparser import os import sys import scrapy.spiderloader import scrapy.statscollectors import scrapy.logformatter import scrapy.dupefilters import scrapy.squeues import scrapy.extensions.spiderstate import scrapy.extensions.corestats import scrapy.extensions.telnet import scrapy.extensions.logstats import scrapy.extensions.memusage import scrapy.extensions.memdebug import scrapy.extensions.feedexport import scrapy.extensions.closespider import scrapy.extensions.debug import scrapy.extensions.httpcache import scrapy.extensions.statsmailer import scrapy.extensions.throttle import scrapy.core.scheduler import scrapy.core.engine import scrapy.core.scraper import scrapy.core.spidermw import scrapy.core.downloader import scrapy.downloadermiddlewares.stats import scrapy.downloadermiddlewares.httpcache import scrapy.downloadermiddlewares.cookies import scrapy.downloadermiddlewares.useragent import scrapy.downloadermiddlewares.httpproxy import scrapy.downloadermiddlewares.ajaxcrawl import scrapy.downloadermiddlewares.chunked import scrapy.downloadermiddlewares.decompression import scrapy.downloadermiddlewares.defaultheaders import scrapy.downloadermiddlewares.downloadtimeout import scrapy.downloadermiddlewares.httpauth import scrapy.downloadermiddlewares.httpcompression import scrapy.downloadermiddlewares.redirect import scrapy.downloadermiddlewares.retry import scrapy.downloadermiddlewares.robotstxt import scrapy.spidermiddlewares.depth import scrapy.spidermiddlewares.httperror import scrapy.spidermiddlewares.offsite import scrapy.spidermiddlewares.referer import scrapy.spidermiddlewares.urllength import scrapy.pipelines import scrapy.core.downloader.handlers.http import scrapy.core.downloader.contextfactory import scrapy.core.downloader.handlers.file import scrapy.core.downloader.handlers.ftp import scrapy.core.downloader.handlers.datauri import scrapy.core.downloader.handlers.s3 print(sys.path[0]) print(sys.argv[0]) print(os.path.dirname(os.path.realpath(sys.executable))) print(os.path.dirname(os.path.realpath(sys.argv[0]))) cfg=os.path.join(os.path.split(sys.path[0])[0],"scrapy.cfg") print(cfg) input() process = CrawlerProcess(get_project_settings()) process.crawl('biqubao_spider',domain='biqubao.com') process.start() # the script will block here until the crawling is finished
经过尝试只有sys.path这个函数是获取到temp文件的位置.
cfg这个变量就是我后来得出的scrapy.cfg在temp目录下的位置
产生的temp文件如下:
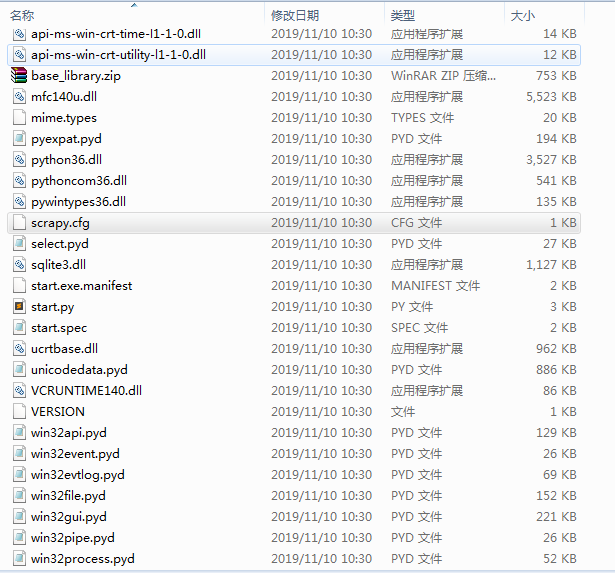
temp文件中包含了cfg,我们继续测试一下,在temp文件中运行start.py文件,发现这里是可以正常运行的
那么问题所在就是scrapy读取不到cfg文件所产生的
问题2
如何让scrapy读取到cfg文件呢?
经过调试,我找到了一个scrapy读取cfg文件路径的函数
#scrapyutilsconf.py
def get_sources(use_closest=True): xdg_config_home = os.environ.get('XDG_CONFIG_HOME') or os.path.expanduser('~/.config') sources = ['/etc/scrapy.cfg', r'c:scrapyscrapy.cfg', xdg_config_home + '/scrapy.cfg', os.path.expanduser('~/.scrapy.cfg')] if use_closest: sources.append(closest_scrapy_cfg()) return sources
函数的sources 是一个cfg文件路径的数组
经过问题1的测试,那么我们这时候会想到了我们执行了单文件,导致了scrapy读取的是单文件路径下的cfg,而不是temp文件中的cfg
那么这时候只要在sources中添加单文件执行后产生的temp文件就能正确的读取到cfg文件了
def get_sources(use_closest=True): xdg_config_home = os.environ.get('XDG_CONFIG_HOME') or os.path.expanduser('~/.config') sources = ['/etc/scrapy.cfg', r'c:scrapyscrapy.cfg', xdg_config_home + '/scrapy.cfg', os.path.expanduser('~/.scrapy.cfg'),os.path.join(os.path.split(sys.path[0])[0],"scrapy.cfg")] if use_closest: sources.append(closest_scrapy_cfg()) return sources
重新打包,发现移动单个的可执行文件也不会报错了!