1, 替换字段内容REPLACE
语法:
|
1
|
REPLACE <str1> WITH <str2> INTO <c> [LENGTH <l>].
|
ABAP/4 搜索字段 <c> 中模式 <str1> 前 <l> 个位置第一 次出现的地 方。如果未 指定长度, 按全长度搜 索模式 <str1>。 然后,语句 将模式 <str1> 在字段 <c> 中第一次出 现的位置用 字符串 <str2> 替换。如果 指定长度<l>, 则只替换模 式的相关部 分。 如果将系统 字段 SY-SUBRC 的返回代码 设置为0, 则说明在 <c> 中找到 <str1> 且已用<str2> 替换。非 0 的返回代码 值意味着未 替换。
<str1>、 <str2> 和 <len> 可为变量。
代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
DATA: T(10) VALUE 'abcdefghij',
STRING LIKE T,
STR1(4) VALUE 'cdef',
STR2(4) VALUE 'klmn',
STR3(2) VALUE 'kl',
STR4(6) VALUE 'klmnop',
LEN TYPE I VALUE 2.
STRING = T.
WRITE STRING.
REPLACE STR1 WITH STR2 INTO STRING.
WRITE / STRING.
STRING = T.
REPLACE STR1 WITH STR2 INTO STRING LENGTH LEN.
WRITE / STRING.
STRING = T.
REPLACE STR1 WITH STR3 INTO STRING.
WRITE / STRING.
STRING = T.
REPLACE STR1 WITH STR4 INTO STRING.
WRITE / STRING.
|
结果显示:
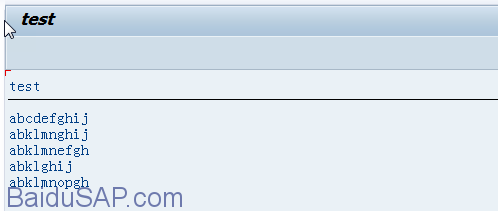
请注意,在最后一行中字段 STRING 是如何在右 边截断的。长度为 4 的搜索模式 ‘cdef’ 用长度为6的 ‘klmnop’ 替换。然后 ,填充字段 STRING 的剩余部分直到字段结尾。
2, 转换大/小写并替换字符TRANSLATE
可以将字母 转换大/小 写或使用替 换规则。 要转换大/小 写,请使用 TRANSLATE 语句,用法 如下:
语法
|
1
|
TRANSLATE <c> TO UPPER CASE. TRANSLATE <c> TO LOWER CASE.
|
这些语句将 字段 <c> 中的所有小 写字母转换 成大写或反 之。
使用替换规 则时,请使 用以下语法 :
语法
|
1
|
TRANSLATE <c> USING <r>.
|
该语句根据 字段 <r> 中存储的替 换规则替换 字段 <c> 的所有字符 。<r> 包含成对字 母,其中每 对的第一个 字母用第二 个字母替换 。<r> 可为变量。 有关包含更 复杂替换规 则的 TRANSLATE 语句的更多 变体,参见 关键字文档 。
代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
DATA: T(10) VALUE 'AbCdEfGhIj',
STRING LIKE T,
RULE(20) VALUE 'AxbXCydYEzfZ'.
STRING = T.
WRITE STRING.
TRANSLATE STRING TO UPPER CASE.
WRITE / STRING.
STRING = T.
TRANSLATE STRING TO LOWER CASE.
WRITE / STRING.
STRING = T.
TRANSLATE STRING USING RULE.
WRITE / STRING.
|
显示结果:
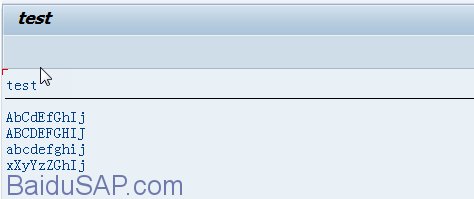
3, 转换为可排序格式CONVERT TEXT
可以将字符 字段转换为 可按字母顺 序排列的格 式:
语法:
|
1
|
CONVERT TEXT <c> INTO SORTABLE CODE <sc>.
|
该语句为字 符字段 <c> 填充可排序 目标字段 <sc>。 字段 <c> 必须是类型 C且字段 <sc> 必须是类型 X ,最小长度 为 <c> 长度的16倍 。 该语句目的 是为字符字 段 <c>
创建相关字 段 <sc>, 作为 <c> 的按字母顺 序排列的排 序关键字。
如果对未转 换的字符字 段进行排序 ,则系统创 建与各字母 的特定平台 内部编码相 对应的顺序 。在对目标 字段进行排 序之后,转 换 CONVERT TEXT 按这样的方 式创建目标
字段,相应 的字符字段 顺序按字母 排序。例如 ,在德语中 ,顺序为‘ Miller、 Moller、 M?ller、 Muller’ ,而不是‘ Miller、 Moller、 Muller、 M?ller’ 。
转换方法依 赖于运行 ABAP/4 程序的文本 环境。文本 环境在用户 主记录中定 义。例外的 是可以使用 如下语句, 在程序中设 置文本环境 :
语法
|
1
|
SET LOCALE LANGUAGE <lg> [COUNTRY <cy>] [MODIFIER <m>].
|
该语句根据 语言 <lg> 设置文本环 境。对于选 项 COUNTRY, 只要特定国 家语言不同 ,就可以在
语言以外指 定国家。对 于选项 MODIFIER, 只要一个国 家内语言不 同,就可以 指定另一个 标识符,例 如,排序顺 序在电话簿 和词典之间 不同。 字段 <lg>、 <cy> 和
<m> 必须是类型 C 且长度必须 与表 TCP0C 的关键字段 长度相等。 表 TCP0C 是一个表格 ,从中进行 平台相关的 文本环境维 护。在语句 SET LOCALE 期间,系统 根据
TCP0C中 的条目设置 文本环境。 除了内部传 送的平台特 性之外,用 SET 语句指定表 关键字。如 果 <lg> 等于 SPACE ,则系统根 据用户主记 录设置文本 环境。如果 对于指
定的 关键字在表 中无条目, 则系统将产 生运行错误 。
文本环境影 响 ABAP/4 中依赖于字 符集的所有 操作。
4, 移动字段内容SHIFT
按给定位置 数移动字段串
要按给定位 置数移动字 段内容,请 使用 SHIFT 语句,用法 如下:
语法
|
1
|
SHIFT <c> [BY <n> PLACES] [<mode>].
|
该语句将字 段 <c> 移动 <n> 个位置。如 果省略 BY <n> PLACES, 则将 <n> 解释为一个 位置。如果 <n> 是 0 或负值,则 <c> 保持不变。 如果 <n> 超过 <c> 长度,则 <c> 用空格填充 。<n> 可为变量。 对不同(<mode>) 选项,可以 按以下方式 移动字段 <c>:
- LEFT:向左移动 <n> 位置,右边 用 <n> 个空格填充 (默认设置 )。
- RIGHT:向右移动 <n> 位置,左边 用 <n> 个空格填充 。
- CIRCULAR:向左移动 <n> 位置,以便 左边 <n> 个字符出现 在右边。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
DATA: T(10) VALUE 'abcdefghij',
STRING LIKE T.
STRING = T.
WRITE STRING.
SHIFT STRING.
WRITE / STRING.
STRING = T.
SHIFT STRING BY 3 PLACES LEFT.
WRITE / STRING.
STRING = T.
SHIFT STRING BY 3 PLACES RIGHT.
WRITE / STRING.
STRING = T.
SHIFT STRING BY 3 PLACES CIRCULAR.
WRITE / STRING.
|
显示结果:
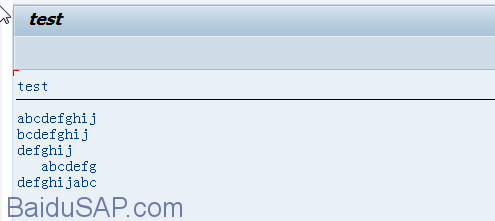
移动字段串 到给定串
要移动字段 内容以到给 定串,则使 用 SHIFT 语句,
语法:
|
1
|
SHIFT <c> UP TO <str> <mode>.
|
ABAP/4 查找 <c> 字段内容直 到找到字符 串 <str> 并将字段 <c> 移动到字段 边缘。 <mode> 选项与按给定位置数移动字段串中所 述相同。<str> 可为变量。 如果 <c> 中找不到 <str>, 则将 SY-SUBRC 设置为 4 并且不移动 <c>。否 则,将 SY-SUBRC 设置为0。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
DATA: T(10) VALUE 'abcdefghij',
STRING LIKE T,
STR(2) VALUE 'ef'.
STRING = T.
WRITE STRING.
SHIFT STRING UP TO STR.
WRITE / STRING.
STRING = T.
SHIFT STRING UP TO STR LEFT.
WRITE / STRING.
STRING = T.
SHIFT STRING UP TO STR RIGHT.
WRITE / STRING.
STRING = T.
SHIFT STRING UP TO STR CIRCULAR.
WRITE / STRING.
|
根据第一个或最后一个 字符移动字段串
假设第一个或最后一个 字符符合一定条件,则 可用 SHIFT 语句将字段 向左或向右 移动。为此 ,请使用以 下语法:
语法
|
1
2
3
|
SHIFT <c> LEFT DELETING LEADING <str>.
SHIFT <c> RIGHT DELETING TRAILING <str>.
|
假设左边的 第一个字符 或右边的最 后一个字符 出现在 <str> 中,该语句 将字段 <c> 向左或向右 移动。字段 右边或左边 用空格填充 。<str> 可为变量。
代码:
|
1
2
3
4
5
6
7
8
9
10
|
DATA: T(14) VALUE ' abcdefghij',
STRING LIKE T,
STR(6) VALUE 'ghijkl'.
STRING = T.
WRITE STRING.
SHIFT STRING LEFT DELETING LEADING SPACE.
WRITE / STRING.
STRING = T.
SHIFT STRING RIGHT DELETING TRAILING STR.
WRITE / STRING.
|
显示结果:
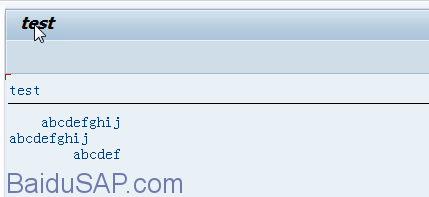
5, MOVE TO 分配字符串部分
MOVE 语句的以下 变体只使用 类型 C 字段:
语法:
|
1
|
MOVE <c1> TO <c2> PERCENTAGE <p> [RIGHT].
|
将字符字段 <c1> 的左边,百分比 <p>的部分复制到 <c2>,结果为左对齐。 ( 如果用 RIGHT 选项指定, 则为右对齐 )。<p> 值可为 0 和 100 之间的任何数。将要从 <C1> 复制的长度 取整为下一个整数。 如果语句中 某一参数不是类型 C,则忽略参数 PERCENTAGE。
|
1
2
3
4
5
6
|
DATA: c1(10) TYPE c VALUE 'ABCDEFGHIJ',
c2(10) TYPE c.
MOVE c1 TO c2 PERCENTAGE 40.
WRITE c2.
MOVE c1 TO c2 PERCENTAGE 40 RIGHT.
WRITE / c2.
|
6, 比较字符串
要比较字符 串(类型 C)和数字 文本(类型 N),可以 在逻辑表达 式中使用下 列运算符。
<运算符> 含 义
CO 仅包含
CN 不仅包含
CA 包含任何
NA 不包含任何
CS 包含字符串
NS 不包含字符串
CP 包含模式
NP 不包含模式
因为除类型 N 和 C 外,系统不 能执行任何 其它类型转 换,所以, 在进行包含 这些运算之 一的比较时 ,操作数应 该是类型 N 或 C。 运算符的功 能如下:
CO (仅包含)
如果 <f1> 仅包含 <f2> 中的字符, 则逻辑表达 式 <f1> CO <f2> 为真。该比 较区分大小 写,并包括 尾部空格。 如果比较结 果为真,则 系统字段 SY-FDPOS 包括 <f1> 的长度。如 果为假,则 SY-FDPOS 包含 <f1> 中第一个未 在 <f2> 内出现的字 符的偏移量 。
CN (不仅包含 )
如果 <f1> 还包含 <f2> 之外的其他 字符,则逻 辑表达式 <f1> CN <f2> 为真。该比 较区分大小 写,并包括 尾部空格。 如果比较结 果为真,则 系统字段 SY-FDPOS 包含 <f1> 中第一个未 同时在 <f2> 中出现的字 符的偏移量 。如果为假 ,SY-FDPOS 包含 <f1> 的长度。
CA (包含任何 )
如果 <f1> 至少包含 <f2> 的一个字符 ,则逻辑表 达式 <f1> CA <f2> 为真。该比 较区分大小 写。如果比 较结果为真 ,则系统字 段 SY-FDPOS 包含 <f1> 中第一个也 在 <f2> 中出现的字 符的偏移量 。如果为假 ,SY-FDPOS 包含 <f1> 的长度。
NA (不包含任 何)
如果 <f1> 不包含 <f2> 的任何字符 ,则逻辑表 达式 <f1> NA <f2> 为真。该比 较区分大小 写。如果比 较结果为真 ,则系统字 段 SY-FDPOS 包含 <f1>的 长度。如果 为假,则 SY-FDPOS 包含 <f1> 中在 <f2> 内出现的第 一个字符的 偏移量。
CS (包含字符 串)
如果 <f1> 包含字符串 <f2>, 则逻辑表达 式 <f1> CS <f2> 为真。忽略 尾部空格并 且比较不区 分大小写。 如果比较结 果为真,则 系统字段 SY-FDPOS 包含 <f2> 在 <f1> 中的偏移量 。如果为假 ,SY-FDPOS 包含 <f1> 的长度。
NS (不包含字 符串)
如果 <f1> 不包含字符 串 <f2>, 则逻辑表达 式 <f1> NS <f2> 为真。忽略 尾部空格且 比较不区分 大小写。如 果比较为真 ,系统字段 SY-FDPOS 包含 <f1> 的长度。如 果为假,系 统字段 SY-FDPOS 包含 <f2> 在 <f1> 中的偏移量 。
CP (包含模式 )
如果 <f1> 包含模式 <f2>, 则逻辑表达 式 <f1> CP <f2> 为真。如果 <f2> 属于类型 C,则可以 在 <f2> 中使用下列 通配符:
- * 用于任何字 符串
- + 用于任何单 个字符
忽略尾部空 格且比较不 区分大小写 。如果比较 结果为真, 系统字段 SY-FDPOS 包含 <f2> 在 <f1> 中的偏移量 。如果为假 ,SY-FDPOS 包含 <f1> 的长度。 如果要对 <f2> 中的特殊字 符进行比较 ,请将换码 字符 # 放到其前面 。可以使用 换码字符 # 指定
- 大小写字 符
- 通配符 "*"(输 入 #*)
- 通配符 "+" (输入 #+)
- 换码符号 本身 (输入 ##)
- 字符串结 尾的空格 (输入 #___)
NP (不包含模 式)
如果 <f1> 不包含模式 <f2>, 则逻辑表达 式 <f1> NP <f2> 为真。在<f2>中 ,可以使用 与 CP 相同的通配 符和换码字 符。 忽略尾部空 格且比较不 区分大小写 。如果比较 结果为真, 则系统字段 SY-FDPOS 包含 <f1>. 的长度,如 果为假,SY-FDPOS 包含 <f2> 在 <f1> 中的偏移量 。
例子:
下表列出该 程序的执行 结果,取决 于所用的运 算符和 F1 / F2 字段。
<f1> <operator> <f2> Result SY-FDPOS
'BD ' CO 'ABCD ' 真 5
'BD ' CO 'ABCDE' 假 2
'ABC12' CN 'ABCD ' 真 3
'ABABC' CN 'ABCD ' 假 5
'ABcde' CA 'Bd ' 真 1
'ABcde' CA 'bD ' 假 5
'ABAB ' NA 'AB ' 假 0
'ababa' NA 'AB ' 真 5
'ABcde' CS 'bC ' 真 1
'ABcde' CS 'ce ' 假 5
'ABcde' NS 'bC ' 假 1
'ABcde' NS 'ce ' 真 5
'ABcde' CP '*b*' 真 1
'ABcde' CP '*#b*' 假 5
'ABcde' NP '*b*' 假 1
'ABcde' NP '*#b*' 真 5
以上。