1.什么是Hadoop?
Hadoop是一种分布式数据和计算的框架。
它很擅长存储大量的半结构化的数据集。
数据可以随机存放,所以一个磁盘的失败并不会带来数据丢失。
Hadoop也非常擅长分布式计算——快速地跨多台机器处理大型数据集合。
Hadoop 是最受欢迎的在 Internet 上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。
Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;
而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
2.Hadoop的框架最核心的设计就是:
HDFS: HDFS为海量的数据提供了存储
MapReduce: MapReduce则为海量的数据提供了计算
3.Hadoop的优点:
【高可靠性】:假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
【高扩展性】:能够处理 PB 级数据,在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。。
【低成本】:开源的,依赖社区服务,成本低。
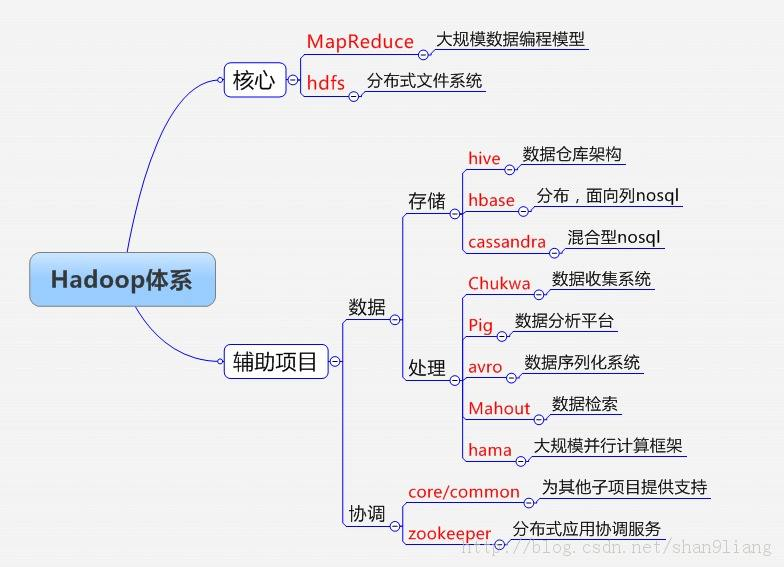
4.结构分支图:
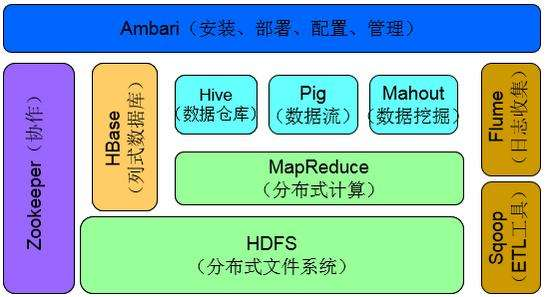
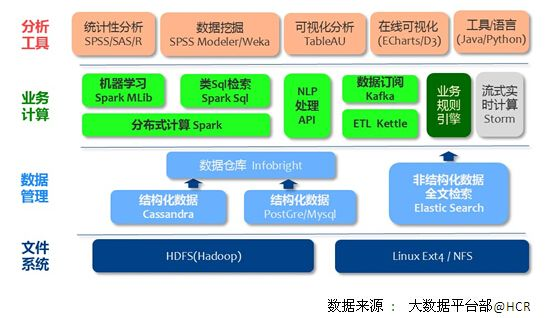
5.企业应用架构图: