一、背景
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。

Apache hadoop官方网址http://hadoop.apache.org/
官方提供的包有两种:
一:source包,也就是源码包要求自已编译安装的包
二:binary包,32位编译后的包,可以直接使用的包。
注意:官方只提供32位环境编译的包,只能运行在32位机器上.生产环境一般是64位操作系统,要求自已编译源码包进行安装。
另外下载所有版本网址:http://archive.apache.org/dist/hadoop/
其中http://archive.apache.org/dist这部分是apache开源的所有项目地址,而http://archive.apache.org/dist/hadoop/ 是hadoop项目的地址。
Cloudera
使用下载最多的版本,稳定,有商业支持,在Apache的基础上打上了一些patch。推荐使用。
二、环境搭建
1、linux环境准备
环境:Windows10 , VMware Workstation12, CentOS6
配置VMWare虚拟软件网卡,保证Windows机器能和虚拟机linux正常通信
点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip 设置网段:192.168.101.0 子网掩码:255.255.255.0 -> apply -> ok
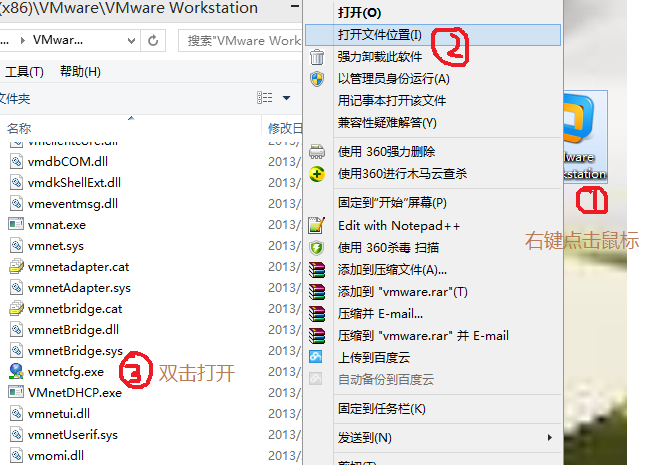

回到windows --> 打开网络和共享中心 -> 更改适配器设置 -> 右键VMnet1 -> 属性 -> 双击IPv4 -> 设置windows的IP:192.168.0.100 子网掩码:255.255.255.0 -> 点击确定
在虚拟软件上 --My Computer -> 选中虚拟机 -> 右键 -> settings -> network adapter -> host only -> ok
修改主机名
vim /etc/sysconfig/network

NETWORKING=yes
HOSTNAME=hadoop01

修改配置文件
vim /etc/sysconfig/network-scripts/ifcfg-eth0


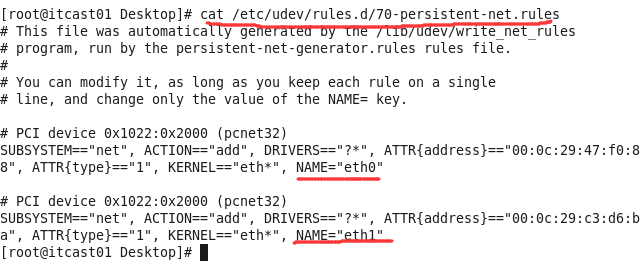
说明:如果ifconfig时,显示的网卡驱动名字不是默认的eth0,如下图

则可以通过修改该机器下的文件etc/udev/rules.d/70-persistent-net.rules的内容即可解决
即把下面的Name为ETH1的配置信息删除即可。
修改主机名和IP的映射关系
vim /etc/hosts
192.168.0.2 hadoop01
关闭防火墙
#关闭防火墙
service iptables stop
#关闭防火墙开机启动
chkconfig iptables off
重启
接着在windows系统下C:WindowsSystem32driversetc,修改文件权限后修改该文件,增加 自己的主机名和IP,接着在dos界面测试,ping 配置好的虚拟机 主机名,连接成功即结束。
----上述是单个主机的配置,集群则是按照上述的方法给每个主机进行配置或是直接copy虚拟机,需要注意的则是 主机名和IP不同,每个虚拟机中都要有全部的主机名和IP的映射关系。
2、JDK环境准备
通过VMware Tools 或者 FileZilla 将 windows下的 jdk-7u79-linux-i586.tar.gz copy到 linux系统中
解压jdk,并把java添加到环境变量中(文件 /etc/profile)
在终端中,输入命令 jave -version 即可知道是否成功
3、Hadoop环境准备
通过VMware Tools 或者 FileZilla 将 windows下的 hadoop-2.5.0-cdh5.3.6.tar.gz copy到 linux系统中
解压jdk,并把hadoop添加到环境变量中(文件 /etc/profile)
配置hadoop文件,配置完毕之后,远程拷贝到其他节点即可。(需要ssh免密码登录)
配置(在hadoop目录下查找文件),配置目录在官方文档中
* hdfs
* hadoop-env.sh
* core-site.xml
* hdfs-site.xml
* slaves
* yarn
* yarn-env.sh
* yarn-site.xml
* slaves
* mapredue
* mapred-env.sh
* mapred-site.xml
hadoop-env.sh
在 # The java implementation to use. 下
export JAVA_HOME=/opt/modules/jdk1.7.0_79
core-site.xml
最下方 添加
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cdh1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/app/hadoop-2.5.0-cdh5.3.6/data/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>420</value>
</property>
</configuration>
hdfs-site.xml
最下方 添加
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>cdh3:50090</value>
</property>
</configuration>
slaves
cdh1
cdh2
cdh3
yarn-env.sh
在 # some Java parameters 下
export JAVA_HOME=/opt/modules/jdk1.7.0_79
yarn-site.xml
最下方 添加
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>cdh2</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>420</value>
</property>
</configuration>
mapred-env.sh
注释区下方 添加
export JAVA_HOME=/opt/modules/jdk1.7.0_79
mapred-site.xml
最下方 添加
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>cdh1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cdh1:19888</value>
</property>
</configuration>
4、配置ssh免密码登录以及集群时间同步
ssh免密码登录
每台服务器都生成公钥,合并到authorized_keys后,分发到集群内各节点 。
[ root@cdh1 .ssh]# cd /root
[ root@cdh1 .ssh]# cd .ssh
[ root@cdh1 .ssh]# ssh-keygen -t rsa
[ root@cdh1 .ssh]# ssh-copy-id cdh1
[ root@cdh1 .ssh]# ssh-copy-id cdh2
[ root@cdh1 .ssh]# ssh-copy-id cdh3
接着就可以拷贝配置文件到远程节点中了
[ root@cdh1 app]# scp -r hadoop-2.5.0-cdh5.3.6/ root@cdh2:/opt/app/
[ root@cdh1 app]# scp -r hadoop-2.5.0-cdh5.3.6/ root@cdh3:/ opt/app/
时间同步
[ root@cdh1 ]# rpm -qa|grep ntp
[ root@cdh1 ]# vi /etc/ntp.conf
打开是这样的,然后我们要修改--

[ root@cdh1 ]# vi /etc/sysconfig/ntpd
Drop root to id 'ntp:ntp' by default.
SYNC_HWCLOCK=yes
OPTIONS="-u ntp:ntp -p /var/run/ntpd.pid -g"
[ root@cdh1 ]# service ntpd status
[ root@cdh1 ]# service ntpd start
[ root@cdh1 ]# chkconfig ntpd on
[ root@cdh2 ]# crontab -e
0-59/10 * * * * /usr/sbin/ntpdate cdh1
[ root@cdh2 ]# /usr/sbin/ntpdate cdh1

5、集群测试与应用
格式化namenode(是对namenode进行初始化)
[ root@cdh1 hadoop-2.5.0-cdh5.3.6]# hdfs namenode -format
启动hadoop
先启动HDFS
[ root@cdh1 hadoop-2.5.0-cdh5.3.6]# sbin/start-dfs.sh
再启动YARN –-注意不是同一台主机
[ root@cdh1 hadoop-2.5.0-cdh5.3.6]# sbin/start-yarn.sh
验证是否启动成功
jps或者浏览器查看(cdh1 上 https://IP:50070 HDFS管理界面,cdh2上 https://IP:8088 MR管理界面)
cdh1
NodeManager
NameNode
DataNode
cdh2
NodeManager
DataNode
ResourceManager
cdh3
NodeManager
SecondaryNameNode
DataNode
>>>>>>>>>>>>>>>>>>>>到此配置完成