1. 小数据池
1.1 前提条件
- 只针对int,str,bool
1.1.1 int 的范围 -5~256 ,cmd 终端验证
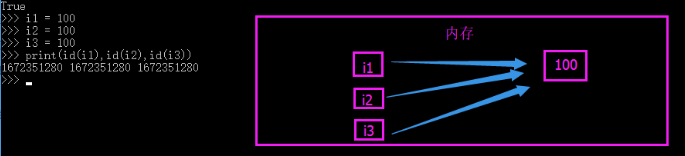
- 赋值:判断两边的值是否相等
a = 100
b = 100
print(id(a),id(b)) #id相同
print(a == b) #结果:True
- 下边将介绍大于256其实id也相同,属于代码块定义
1.1.2 str: 字符串从以下几个方面介绍
- is 是基于内存地址进行判断的
- 字符串长度为0或者1,默认都采用了驻留机制(小数据池)
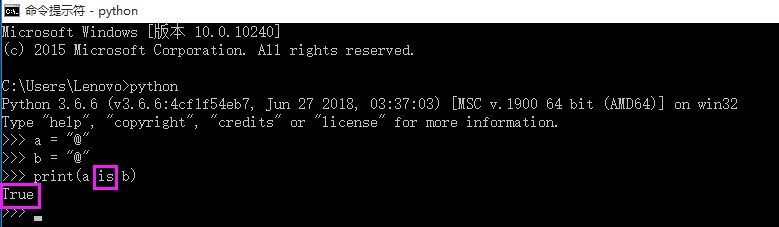
- 字符串长度>1,且只含有大小写字母,数字,下划线时,默认驻留
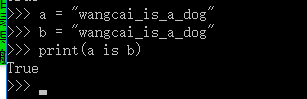
-
用乘法得到的字符串,分两种情况
-
乘数小于1时
- 仅含大小写字母,数字,下划线,默认驻留
- 含其他字符,长度<=1,默认驻留
-
乘数>=2时,
-
仅含大小写字母,数字,下划线,总长度<=20,默认驻留
-
a = "www.python.com" * 3 b = "www.python.com" * 3 print(a is b) #结果:False print(id(a),id(b)) #867652581584 867652581968
-
-
以上为True,其他为False
-
1.2 练习
a = "wusir你好" *1 # 1或0
b = "wusir你好" *1
print(id(a)) #257789114576
print(id(b)) #257789114576
print(a is b) #True
a = "wusir你好" *2
b = "wusir你好" *2
print(id(a)) #438334254696
print(id(b)) #438334940328
print(a is b) #False
2.深浅拷贝
2.1 浅拷贝
2.1.11.赋值 使用的是同一个内存空间,没有开辟新的
lst = ["太白","wusir","大黑",["刘备","关羽","张飞"]]
lst1 = lst
print(lst) #['太白', 'wusir', '大黑', ['刘备', '关羽', '张飞']]
print(lst1) #['太白', 'wusir', '大黑', ['刘备', '关羽', '张飞']]
lst.remove("wusir")
print(lst) #['太白', '大黑', ['刘备', '关羽', '张飞']]
print(lst1) #['太白', '大黑', ['刘备', '关羽', '张飞']]
lst[-1].remove("刘备")
print(lst) #['太白', 'wusir', '大黑', ['关羽', '张飞']]
print(lst1) ##['太白', 'wusir', '大黑', ['关羽', '张飞']]
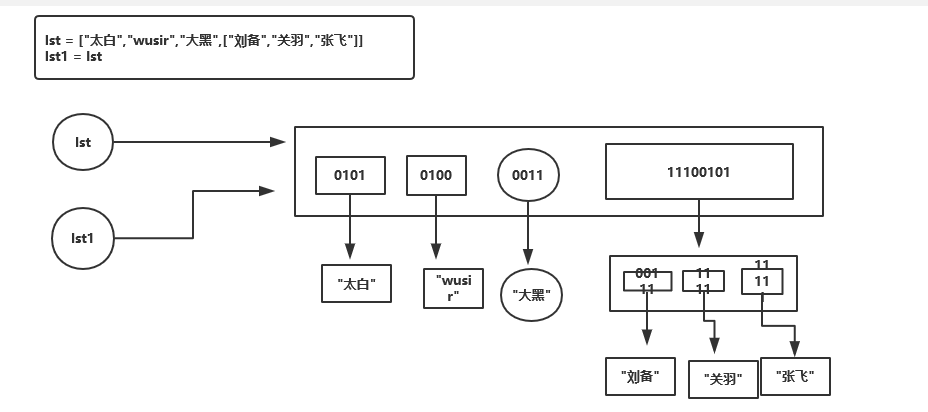
2.1.2 浅拷贝 浅拷贝的时候,只会开辟一个新的容器列表,其他元素使用的都是源列表中的元素
lst = ["太白","wusir","大黑",["刘备","关羽","张飞"]]
lst1 = lst.copy()
print(id(lst)) #453267241096
print(id(lst1)) #453268052936 #id 不同
print(id(lst[1])) #112526459880
print(id(lst1[1])) #112526459880 ##id 相同
print(id(lst[-1])) #957977868168
print(id(lst1[-1])) #957977868168 #id 相同
lst[-1].append(666)
#lst1[-1].append(666)
print(lst)
print(lst1)
结果 #都改变
['太白', 'wusir', '大黑', ['刘备', '关羽', '张飞', 666]]
['太白', 'wusir', '大黑', ['刘备', '关羽', '张飞', 666]]
lst.append(666)
lst[1] = 666
print(lst)
print(lst1) #结果都在lst上改变,lst1不变
lst1.append(666)
lst1[1] = 666
print(lst)
print(lst1) #结果都在lst1上改变,lst不变

# 浅拷贝的时候只拷贝第一层元素
# 浅拷贝在修改第一层元素(不可变数据类型)的时候,拷贝出来的新列表不进行改变
# 浅拷贝在替换第一层元素(可变数据类型)的时候,拷贝出来的新列表不进行改变
# 浅拷贝在修改第一层元素中的元素(第二层)的时候,拷贝出来的新列表进行改变
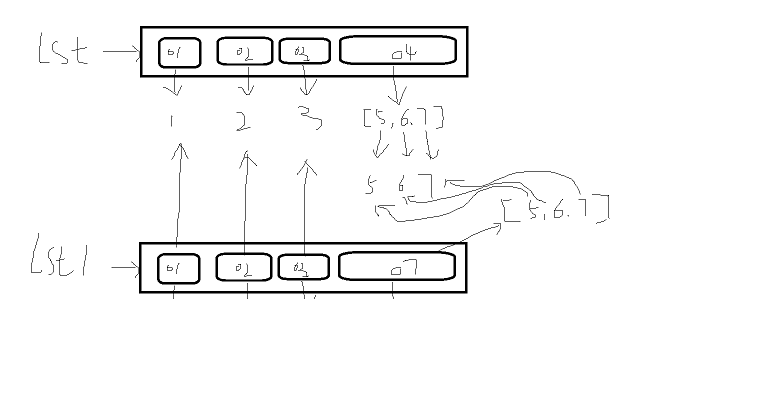
2.2 深拷贝
lst = ["太白","wusir","大黑",["刘备","关羽","张飞"]]
import copy
lst1 = copy.deepcopy(lst)
print(id(lst)) #1022631491464
print(id(lst1)) #1022633789128 #id 不相同
print(id(lst[1])) #174734607336
print(id(lst1[1])) #174734607336 ##id 相同
print(id(lst[-1])) #1092954896456
print(id(lst1[-1])) #1092957194120 #id 不相同
无论lst还是lst1都再互不影响
# 深拷贝开辟一个容器空间(列表),不可变数据公用,可变数据数据类型(再次开辟一个新的空间),空间里的值是不可变的数据进行共用的,可变的数据类型再次开辟空间
3. 集合 (set)
3.1 没有值得字典 ,无序,不支持索引
3.2 特性:天然去重,即没有重复的元素
s = {1,"alex","北京",(1,2,3),12,1,4,"北京"}
print(s)
#结果
#{1, 4, 12, '北京', (1, 2, 3), 'alex'} 无序且没有重复的
3.4 面试题
lst = [1,2,1,2,4,2,45,3,2,45,2345]
print(set(lst)) #{1, 2, 3, 4, 2345, 45}
print(list(set(lst))) #[1, 2, 3, 4, 2345, 45]
s = set(lst)
lst1 = list(s)
print(lst1)
扩展
s = set(lst)
lst1 = list(s)
print(lst1)
lst1 = [1, 2, 3, 4, 2345, 45]
lst1.sort() #升序
print(lst1) #[1, 2, 3, 4, 45, 2345]
lst1.sort(reverse=True) #倒序
print(lst1) #[2345, 45, 4, 3, 2, 1]
lst = lst1 #重新赋值
print(lst) #[2345, 45, 4, 3, 2, 1]
3.5 集合的增删改查
# 增:
# s.add("67") #只能添加一个
# print(s)
# s.update("今天") # 迭代添加
# print(s)
# 删:
# print(s.pop()) # pop有返回值
# print(s)
# s.remove(3) # 指定元素删除
# print(s)
# s.clear() # 清空 -- set() 空集合
# print(s)
# 改:
# 先删在加
# 查:
# for i in {1,2,3}:
# print(i)
# 其他操作:
# s1 = {1,2,3,4,5,6,7}
# s2 = {5,6,7,1}
# print(s1 & s2) # 交集
# print(s1 | s2) # 并集
# print(s1 - s2) # 差集
# print(s1 ^ s2) # 反交集
# print(s1 > s2) # 父集(超集)
# print(s1 < s2) # 子集
# print(frozenset(s1)) # 冻结集合 更不常用
# dic = {frozenset(s1):1}
# print(dic)