易错点
建立方式中name不定义,进程是 类名-1 线程是 Thread-1
enumerate() 用法 用于正在运行指线程启动后、结束前,不包括启动前和终止后的线程,返回一个进程对象的列表
lock_A = lock_B = RLock 引入的是RLock模块,且必须这样写
lock_A = Lock
lock_B = Lock 这两个引入的是Lock模块
1.理论部分
- 什么是进程?
- 在内存中开启一个进程空间,然后将主进程的所有的资源数据复制一份,然后调用线程去执行代码
- 什么是线程?
- 在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程
- 线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程
- 什么是多线程?
- 多线程(即多个控制线程)的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源
- 线程vs进程
- 进程是资源单位, 线程是执行单位
- 开启进程的开销非常大,比开启线程的开销大很多
- 开启线程的速度非常快.要快几十倍到上百倍
- 线程线程之间可以共享数据,进程与进程之间需借助队列等方法实现通信
- 线程vs进程的代码对比
- 线程开启速度快
- 线程之间的pid(这个进程的)相同,进程与进程之间的pid不同
- 同一个进程内线程共享数据
- 主线程子线程没有地位之分,但是,一个进程谁在干活?一个主线程在干活,当干完活了,你得等待其他线程干完活之后,才能结束本进程
2. 开启线程的两种方式
1.函数方式
from threading import Thread
import time
def task(name):
print(f'{name} is running') #反应很快,第一个
time.sleep(1)
print(f'{name} is done') #不睡是与主不分前后
if __name__ == '__main__':
t = Thread(target=task,args=("alex",))
t.start()
print('==主线程') #上边不睡的话不确定前后
2.面向对象方式
from threading import Thread
import time
class MyThread(Thread): #必须继承
# def __init__(self,name,age):
# super(MyThread, self).__init__()
# self.name = name
def run(self): # 必须是run方法
print(f'{self.name} is running')
time.sleep(1)
print(f'{self.name} is done')
if __name__ == '__main__':
t = MyThread() #不写init方法,name默认Thread-1
# t = MyThread("alex",19)
t.start()
print('==主线程')
3. 多线程与多进程开启速度区别
1.进程(无其他阻塞,理论先执行主进程)
from multiprocessing import Process
def work():
print("==子进程") #第二
if __name__ == '__main__':
p = Process(target=work)
p.start()
print("==主进程") #第一
2. 线程(无其他阻塞,理论先执行子线程第一行,其他子线程与主线程顺序不稳定)
from threading import Thread
def work():
print("==子线程") #第一
if __name__ == '__main__':
t = Thread(target=work)
t.start()
print("==主线程") # 第二 # 线程是没有主次之分的
4.线程和进程的pid
1.进程之间的pid
主进程pid是同一个,子进程pid各不相同
from multiprocessing import Process
import os
def task(name):
print(f'子进程:{name}:{os.getpid()}')
print(f'主进程:{name}:{os.getppid()}')
if __name__ == '__main__':
p1 = Process(target=task,args=('alex',)) # 创建一个进程对象
p2 = Process(target=task,args=("taibai",)) # 创建一个进程对象
p1.start()
p2.start()
print(f'==主:{os.getpid()}')
2.线程之间的pid(线程是没有pid的,pid只是其所在的进程的pid)
三个pid都是相同的,因为属于一个进程,相同的内存空间
from threading import Thread
import os
def work(name):
print(f'子线程:{name}:{os.getpid()}')
if __name__ == '__main__':
t1 = Thread(target=work,args=('alex',))
t2 = Thread(target=work,args=("taibai",))
t1.start()
t2.start()
print(f'==主线程{os.getpid()}')
5. 同一进程内线程是数据共享的
同一进程内的资源数据对于这个进程的多个线程来说是共享的
1.我自己传值
from threading import Thread
x = 3
def task(x):
print(x) #子线程自己的 #100
if __name__ == '__main__':
t1 = Thread(target=task,args=(100,))
t1.start()
print(f"==主{x}") #==主3
from multiprocessing import Process
x = 3
def task(x):
print(x) #子进程自己的 #100
if __name__ == '__main__':
t1 = Process(target=task,args=(100,))
t1.start()
print(f"==主{x}") #==主3
2.进程之间数据是空间隔离的
from multiprocessing import Process
x = 3
def task():
global x
x += 100 #103
print(x) #子进程自己的
if __name__ == '__main__':
t1 = Process(target=task)
t1.start()
print(f"==主{x}") #==主3
3.同一进程内的线程之间数据共享
from threading import Thread
x = 3
def task():
global x
x += 100
print(x) # 103
if __name__ == '__main__':
t1 = Thread(target=task)
t1.start()
print(f"==主{x}") # ==主103 (注意有没有阻塞,看看子线程是否已修改了数据)
6. 线程的其他方法
-
isAlive() 或者 is_alive() #判断线程是否活着(对对象的操作)
from threading import Thread
import time
x = 3
def task():
print(666)
if __name__ == '__main__':
t1 = Thread(target=task)
t1.start()
time.sleep(1) #让线程运行完,不然时间不好断
print(t1.isAlive()) #判断线程是否活着
print(t1.is_alive()) #判断线程是否活着
print(f"==主{x}")
-
getName 返回线程名 (对对象的操作)
from threading import Thread
x = 3
def task():
print(666)
if __name__ == '__main__':
t1 = Thread(target=task)
t1.start()
print(t1.getName()) #获得线程名 默认Thread-1
print(f"==主{x}")
3.setName 设置线程名 (对对象的操作) 两种方式 获得线程名 两种方式
from threading import Thread
x = 3
def task():
print(666)
if __name__ == '__main__':
t1 = Thread(target=task) #此处也可以设置名称 name = "自定义名称"
t1.start()
t1.setName("自定义名称") #设置线程名
print(t1.getName()) # 获得线程名 自定义名称
#print(t1.name) # 获得线程名 自定义名称
print(f"==主{x}")
4. 获取当前线程对象,再根据对象获取线程名称
from threading import currentThread
from threading import Thread
x = 3
def task():
print(currentThread()) #获取当前线程对象
print(currentThread().name) #获取当前线程名称
if __name__ == '__main__':
t1 = Thread(target=task)
t1.start()
print(currentThread()) #获取当前线程对象
print(currentThread().name) #获取当前线程名称
print(f"==主{x}")
"""
<Thread(Thread-1, started 9132)>
<_MainThread(MainThread, started 632)>
Thread-1
MainThread
==主3
"""
5. enumerate() 用法 用于正在运行指线程启动后、结束前,不包括启动前和终止后的线程,返回一个进程对象的列表
import threading
print(threading.enumerate()) 与下边的enumerate()用法相同
from threading import enumerate
from threading import Thread
import time
def task():
time.sleep(1) #注意enumerate()用法,一个进程开启后,结束前
print(666)
if __name__ == '__main__':
t1 = Thread(target=task,name="线程1")
t2 = Thread(target=task,name="线程2")
t1.start()
t2.start()
print(enumerate()) #返回一个列表
print("==主")
6. activeCount() 返回正在运行的线程数量
from threading import Thread
from threading import activeCount
import time
def task():
time.sleep(1) #注意activeCount()用法,一个进程开启后,结束前
print(666)
if __name__ == '__main__':
t1 = Thread(target=task,name="线程1")
t2 = Thread(target=task,name="线程2")
t1.start()
t2.start()
print(activeCount()) #返回正在运行的进程的个数
print("==主")
7. join 阻塞与守护线程
8.互斥锁

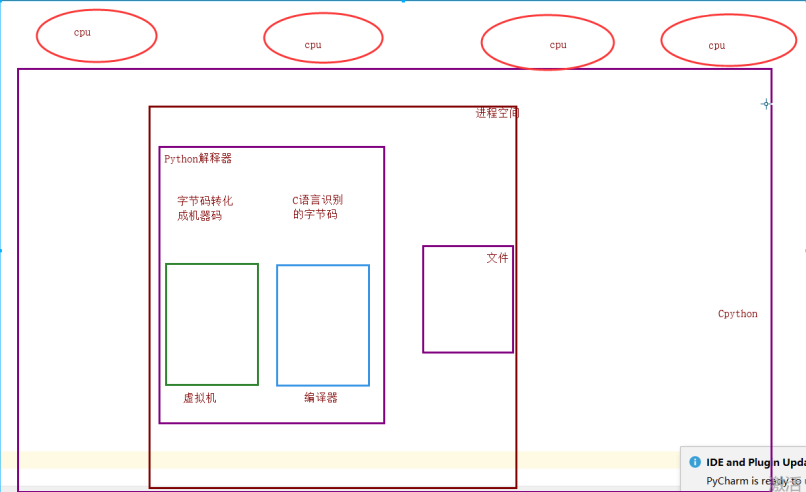
9. 死锁现象与递归锁
lock_A = lock_B = RLock 引入的是RLock模块,且必须这样写
lock_A = Lock
lock_B = Lock 这两个引入的是Lock模块
1. 死循环
from threading import Thread,Lock
import time
lock_A = Lock()
lock_B = Lock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f'{self.name}拿到了A锁')
lock_B.acquire()
print(f'{self.name}拿到了B锁')
lock_B.release()
lock_A.release()
def f2(self):
lock_B.acquire()
print(f'{self.name}拿到了B锁')
# time.sleep(0.1)
lock_A.acquire()
print(f'{self.name}拿到了B锁')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(10):
t = MyThread()
t.start()
"""
线程多了即使上边没有sleep也有可能出现相同的阻塞
即前一个人解锁了A,B锁,又拿到了B,可是下一个人已经
拿到了A锁,形成死循环
"""
2. 将上述代码解开,抢所前并行,抢到后串行 (下列代码中a,b是同一把锁)
from threading import Thread,RLock
import time
lock_A = lock_B = RLock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f'{self.name}拿到了A锁')
lock_B.acquire()
print(f'{self.name}拿到了B锁')
lock_B.release()
lock_A.release()
def f2(self):
lock_B.acquire()
print(f'{self.name}拿到了B锁')
time.sleep(0.1)
lock_A.acquire()
print(f'{self.name}拿到了B锁')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(10):
t = MyThread()
t.start()
10. 信号量 :也是一种锁, 控制并发数量(允许多个人抢锁)
(例子公共厕所人多,允许多个人,有上限,超过了,等着,同一时间最多不能超过上限)
from threading import Thread,Semaphore,current_thread
import time
import random
sem = Semaphore(5) # 英 [ˈseməfɔː(r)]
def task():
sem.acquire() #相当于锁
print(f'{current_thread().name}厕所ing')
time.sleep(random.randint(1,3))
sem.release()
print(f'{current_thread().name}走了')
if __name__ == '__main__':
for i in range(20):
t = Thread(target=task)
t.start()
11. GIL 全局解释器锁 (主要用于Cpython) pypy,Jpython都没有GIL锁.
1.理论上:单个进程的多个线程可以利用多个CPU(适用于 pypy , Jpython)
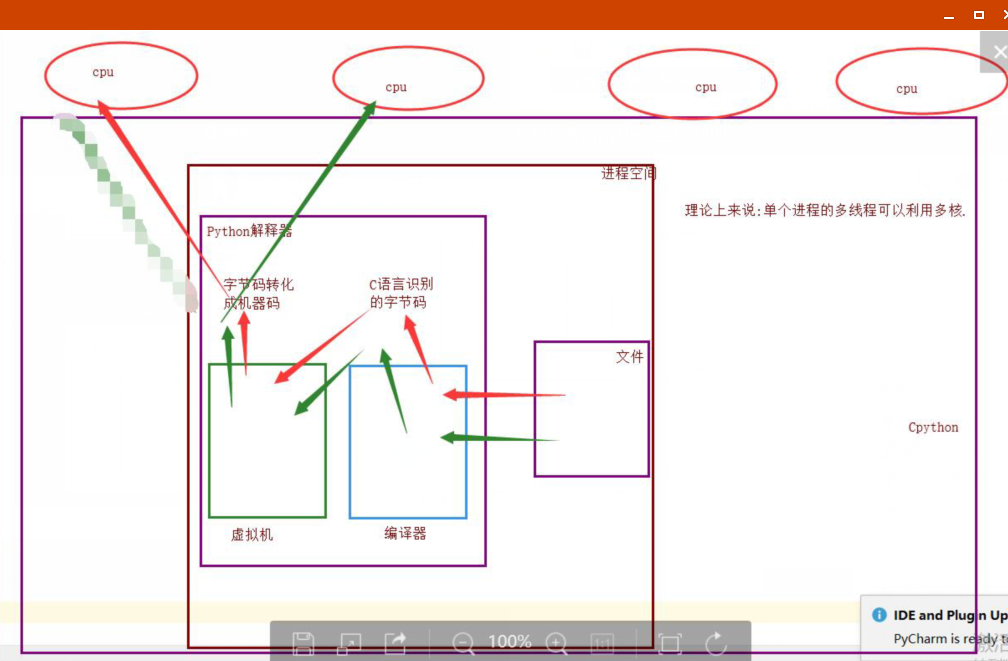
2. 实际上,Cpython解释器的程序员,给进入解释器的线程加了一把锁,导致同一时刻只能允许一个线程计入解释器
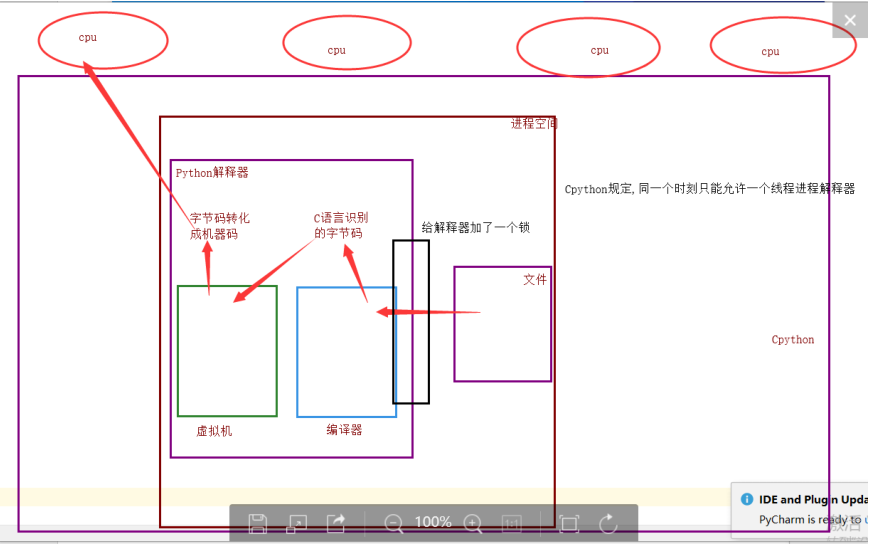
为什么加锁?
1.当时都是单核时代,而且cpu价格非常贵.
2.如果不加全局解释器锁, 开发Cpython解释器的程序员就会在源码内部各种主动加锁,解锁,非常麻烦,各种死锁现象等等.他为了省事儿,直接进入解释器时给线程加一个锁
优点: 保证了Cpython解释器的数据资源的安全.
缺点: 单个进程的多线程不能利用多核(CPU)
现在多核时代, 我将Cpython的GIL锁去掉行么?
因为Cpython解释器所有的业务逻辑都是围绕着单个线程实现的,去掉这个GIL锁,几乎不可能.
3. 当一个线程进入解释器,遇到IO阻塞是,CPU就会被操作系统切走,GIL 锁被释放,此线程挂起,另一个线程进入,实现并发 (但是不能利用多核,不能并行)
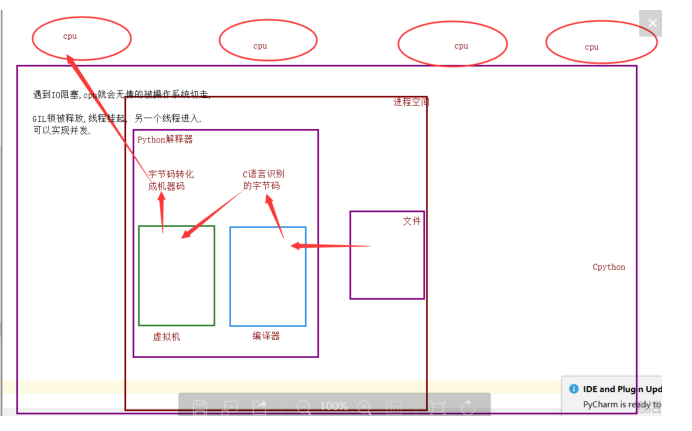
4. IO 密集型(中间有阻塞)
推荐使用:单个进程的多线程
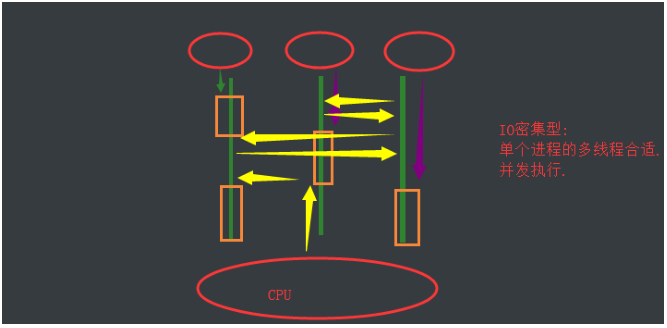
5.计算密集型(中间无阻塞)
推荐使用:多进程的并行
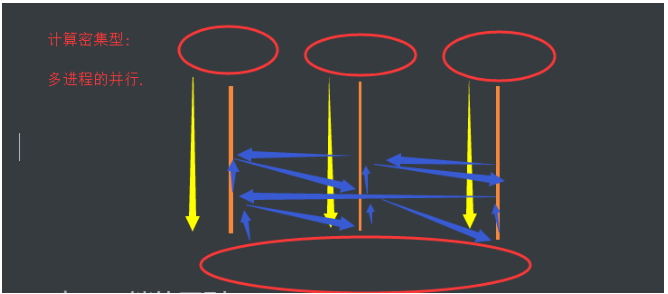
6. GIL 与 Lock锁的区别
相同点:都是同种锁,互斥锁
不同点:
- GIL锁是全局解释器锁,保护解释器内部的资源数据的安全,GIL锁 上锁,释放无需手动操作
- Lock锁是自己代码中自定义的互斥锁,保护进程中的资源数据的安全.自己定义的互斥锁必须自己手动上锁,释放锁
7. 代码说明 两重锁:第一是解释其锁,第二是自定义锁

12.验证 IO(阻塞)密集型和计算(没有阻塞)密集型的效率(主要多进程多线程的开销大小)
1. 计算密集型: 单个进程的多线程并发 vs 多个进程的并发并行(首选:多进程的并发并行效率高)
from multiprocessing import Process
from threading import Thread
import time
import random
def task():
count = 0
for i in range(100000000):
count += 1
if __name__ == '__main__':
#1.单个进程的多线程并发
start_time = time.time()
lst = []
for i in range(4):
t = Thread(target=task)
lst.append(t)
t.start()
for p in lst:
p.join()
print(f'执行效率为:{time.time()-start_time}')
#执行效率为:21.69145154953003
# #2.多进程的并发或并行
# start_time = time.time()
# lst = []
# for i in range(4):
# p = Process(target=task)
# lst.append(p)
# p.start()
#
# for p in lst:
# p.join()
#
# print(f'执行效率为:{time.time()-start_time}')
# #6.934940338134766
2. IO密集型: 单个进程的多线程并发 vs 多个进程的并发并行(首选:单个进程的多线程并发效率高)
from threading import Thread
from multiprocessing import Process
import time
import random
def task():
count = 0
time.sleep(random.randint(1,3))
count += 1
if __name__ == '__main__':
##1.多进程的并发,并行
# start_time = time.time()
# lst = []
# for i in range(100):
# p = Process(target=task)
# lst.append(p)
# p.start()
#
# for p in lst:
# p.join()
#
# print(f'执行效率为:{time.time()-start_time}') # 5.597723960876465
##2. 多线程的并发
start_time = time.time()
lst = []
for i in range(100):
t = Thread(target=task)
lst.append(t)
t.start()
for t in lst:
t.join()
print(f'执行效率为:{time.time() - start_time}') #3.0118417739868164
13. 多线程实现socket通信
1. server 服务端
import socket
from threading import Thread
def communicate(conn,addr):
while 1:
try:
from_client_data = conn.recv(1024)
print(f'来自客户端{addr[1]}的消息{from_client_data.decode("utf-8")}')
to_client_data = input('>>>').strip().encode('utf-8')
conn.send(to_client_data)
except Exception:
break
conn.close()
def _accept():
server = socket.socket()
server.bind(('127.0.0.1',8848))
server.listen(4)
while 1:
conn,addr = server.accept() #阻塞
t = Thread(target=communicate,args=(conn,addr))
t.start()
if __name__ == '__main__':
_accept()
2. client 客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1',8848))
while 1:
try:
to_client_data = input('>>>').strip()
client.send(to_client_data.encode('utf-8'))
from_server_data = client.recv(1024)
print(f'来自服务端的消息:{from_server_data.decode("utf-8")}')
except Exception:
break
client.close()
14. 进程池,线程池
1.开启进程池(进程是并行)
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import os
import time
import random
# print(os.cpu_count())
# #查看计算机的CPU个数 #本机8个,也就是可以一次处理8个
def task(n): #可有可无
print(f'{os.getppid()}连上了')
time.sleep(random.randint(1,3))
print(f'�33[1;35;0m{os.getppid()}断开了�33[0m')
if __name__ == '__main__':
#1.开启进程池
p = ProcessPoolExecutor()
# 默认不写,进程池里面的进程数与cpu个数相等
for i in range(20): #相当于20个任务
p.submit(task,i) #上边有就传值
2.开启线程池(线程是并发,一个CPU)
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import os
import time
import random
# print(os.cpu_count())
# #查看计算机的CPU个数 #本机8个,也就是可以一次处理8个
def task():
print(f'{os.getppid()}连上了')
time.sleep(random.randint(1,3))
print(f'�33[1;35;0m{os.getppid()}断开了�33[0m')
if __name__ == '__main__':
# #2.开启线程池
t = ThreadPoolExecutor()
# 默认不写, cpu个数*5 线程数
for i in range(100):
t.submit(task)