1. ORM介绍
1. ORM概念
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。
简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。
ORM在业务逻辑层和数据库层之间充当了桥梁的作用。
2. 优势
ORM解决的主要问题是对象和关系的映射。它通常将一个类和一张表一一对应,类的每个实例对应表中的一条记录,类的每个属性对应表中的每个字段。
ORM提供了对数据库的映射,不用直接编写SQL代码,只需操作对象就能对数据库操作数据。
让软件开发人员专注于业务逻辑的处理,提高了开发效率。
3. 缺点
ORM的缺点是会在一定程度上牺牲程序的执行效率。
ORM的操作是有限的,也就是ORM定义好的操作是可以完成的,一些复杂的查询操作是完成不了。
ORM用多了SQL语句就不会写了,关系数据库相关技能退化...
2. django中的orm
1. 常用字段
AutoField 自增 primary_key=True主键
CharField # 字符串 字符类型,必须提供max_length参数。max_length表示字符的长度。
TextField # 大字符串 文本类型
IntegerField # 整形 一个整数类型。数值的范围是 -2147483648 ~ 2147483647。
DateTimeField DateField # 日期 日期时间
auto_now:每次修改时修改为当前日期时间。
auto_now_add:新创建对象时自动添加当前日期时间。
auto_now和auto_now_add和default参数是互斥的,不能同时设置。
BooleanField # 布尔值
DecimalField max_digits=5 decimal_places=2 #一共5位,小数点2位,最大值为:999.99
2. 字段参数
null=True 数据库中该字段可以为空
blank=True 用户输入可以为空
default 默认值
db_index=True 索引
unique 唯一约束
verbose_name 显示的名称
choices 可选择的参数
3. 批量插入(bulk_create)
# bulk_create # [bʌlk]
obj_list = []
for i in range(20):
#创建实例化对象,批量创建
obj = models.Book(
title=f'金梅{i}',
price=20+i,
publish_date=f'2019-09-{i+1}',
publish='24期出版社'
)
obj_list.append(obj)
models.Book.objects.bulk_create(obj_list) #批量创建
**打散拆解字典
request.POST -- querydict类型 {'title': ['asdf '], 'price': ['212'], 'publish_date': ['2019-09-12'], 'publish': ['asdf ']}
data = request.POST.dict() -- 能够将querydict转换为普通的python字典格式
创建数据
models.Book.objects.create(
# title=title,
# price=price,
# publish_date=publish_date,
# publish=publish
**data #同上内容
)
4. admin 建表操作
注册
python manage.py createsuperuser
Username : weihe Password: weihe666
admin.py中表信息
from django.contrib import admin
from app01 import models
admin.site.register(models.Book)
admin.site.register(models.Author)
admin.site.register(models.Publish)
admin.site.register(models.AuthorDetail)
5. orm操作数据库
一般在models文件添加__str__方法
__str__ returned non-string (type int) 必须返回字符串
def __str__(self):
return self.title
1. models 表结构
from django.db import models
# Create your models here.
class Author(models.Model):
"""
作者表
"""
name=models.CharField( max_length=32)
age=models.IntegerField()
# authorDetail=models.OneToOneField(to="AuthorDetail",to_field="nid",on_delete=models.CASCADE) #
au=models.OneToOneField("AuthorDetail",on_delete=models.CASCADE)
class AuthorDetail(models.Model):
"""
作者详细信息表
"""
birthday=models.DateField()
telephone=models.CharField(max_length=11)
addr=models.CharField(max_length=64)
# class Meta:
# db_table='authordetail' #指定表名
# ordering = ['-id',]
class Publish(models.Model):
"""
出版社表
"""
name=models.CharField( max_length=32)
city=models.CharField( max_length=32)
class Book(models.Model):
"""
书籍表
"""
title = models.CharField( max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2)
publishs=models.ForeignKey(to="Publish",on_delete=models.CASCADE,)
authors=models.ManyToManyField('Author',)
2. api 13种方法
1.all()方法
models.类名.objects.all() 查询所有结果,结果是QuerySet类型,里边的值都是对象,可以通过for循环取出对象,然后点属性得到值(面向对象)
2.filter()筛选
ret = models.Book.objects.filter()
print(ret)
得到的是QuerySet对象,没有参数时得到所有对象,
ret = models.Book.objects.filter(id=14,title="python")
print(ret)
得到的是QuerySet对象,有参数且能找到返回当前title对象
ret = models.Book.objects.filter(id=100)
print(ret)
得到的是QuerySet对象,有参数但是查不到内容,返回空的<QuerySet []>
ret = models.Book.objects.filter(pdate="2012-12-12").filter(publisher="北京出版社")
print(ret)
得到的是QuerySet对象,可以再次使用filter()方法
3. get()
ret = models.Book.objects.get()
1. 超过一个就报错 :returned more than one Book -- it returned 13!
ret = models.Book.objects.get(id=100)
print(ret)
2. 查不到数据会报错 :Book matching query does not exist.
ret = models.Book.objects.get(id=10)
print(ret)
3.可以匹配到数据,返回models对象,由于str方法得到title的值
4. exclude() #排除
ret = models.Book.objects.exclude(title__startswith="python")
print(ret)
1.objects类型调用,匹配到所有不是以python开头的QuerySet对象
ret = models.Book.objects.all().exclude(title__startswith="python")
print(ret)
2.QuerySet类型数据能够调用,匹配到所有不是以python开头的QuerySet对象
5. order_by()排序
ret = models.Book.objects.all().order_by("-price")
print(ret)
queryset类型的数据来调用,对查询结果排序,默认是按照price倒序,返回值还是queryset类型
6. reverse() 反转
ret = models.Book.objects.all().order_by("id").reverse()
print(ret)
#数据排序之后才能反转
7. count() 计数
fitst() 第一个数据
last() 最后一个数据
ret = models.Book.objects.all().count()
print(ret) ----统计返回结果的数量
first() 返回第一条数据,结果是model对象类型
last() 返回最后一条数据,结果是model对象类型
# ret = models.Book.objects.all().first() = models.Books.objects.all()[0]
ret = models.Book.objects.all().last()
8. exists() 是否存在
ret = models.Book.objects.filter(id=100).exists()
print(ret)
queryset类型的数据来调用,如果QuerySet包含数据,就返回True,否则返回False
9. values()
values(返回的queryset,里面是字典类型数据)
values_list(返回的queryset,里面是元组类型数据)
ret = models.Book.objects.filter(id=12).values("title","price")
print(ret)
得到 QuerySet类型id=12的只含有“title”,“price”属性的字典对象
# ret = models.Book.objects.all().values_list('title','price')
# ret = models.Book.objects.all().values()
# ret = models.Book.objects.values() #调用values或者values_list的是objects控制器,那么返回所有数据
10.distinct() 去重
配合values和values_list来使用
ret = models.Book.objects.all().values('publisher').distinct()
print(ret)
3. filter 双下方法
# ret = models.Book.objects.filter(price__gt=35) #大于
# ret = models.Book.objects.filter(price__gte=35) # 大于等于
# ret = models.Book.objects.filter(price__lt=35) # 小于
# ret = models.Book.objects.filter(price__lte=35) # 小于等于
# ret = models.Book.objects.filter(price__in=[35,44,66,88]) # 在其中
# ret = models.Book.objects.filter(price__range=[35,38]) # 大于等35,小于等于38 # where price between 35 and 38
# ret = models.Book.objects.filter(title__contains='金梅') # 字段数据中包含这个字符串的数据都要
# ret = models.Book.objects.filter(title__contains='金梅')
# ret = models.Book.objects.filter(title__icontains="python") # 不区分大小写
# from app01.models import Book
# ret = models.Book.objects.filter(title__icontains="python") # 不区分大小写
# ret = models.Book.objects.filter(title__startswith="py") # 以什么开头,istartswith 不区分大小写
# ret = models.Book.objects.filter(publish_date='2019-09-15')
某年某月某日:
ret = models.Book.objects.filter(pdate__year='2018')
ret = models.Book.objects.filter(pdate__month='08')
ret = models.Book.objects.filter(pdate__year__gt='2018')
ret = models.Book.objects.filter(pdate__day='1')
找字段数据为空的双下滑线
models.Book.objects.filter(publish_date__isnull=True) #这个字段值为空的那些数据
1. ORM
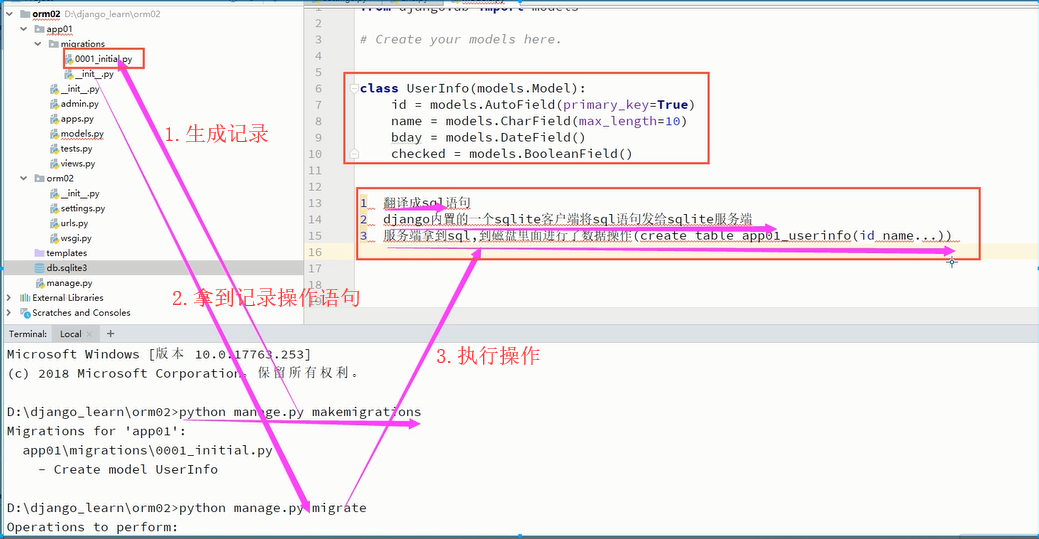
定义:object relations mapping,对象关系映射。它实现了数据模型与数据库的解耦
每个数据库有自己的sql语句,不通用。
1.将对象翻译成sql语句
2.Django内置的一个pymysql客户端将sql语句发送给mysql服务端
3.服务端拿到sql,到磁盘里面进行数据操作
Django默认数据库为sqlite3,比较鸡肋,设置为mysql数据库修改settings配置文件
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', #Django中数据库地址
'NAME':'bms', # 要连接的数据库名,连接前先cmd建库
'USER':'root', # 连接数据库的用户名
'PASSWORD':'', # 连接数据库的密码
'HOST':'127.0.0.1', # 连接主机,默认本级
'PORT':3306, # 端口 默认3306
}
}
如有必要,可以为自己的项目下的 app 配置单独的数据库,如下代码
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME':'bms', # 要连接的数据库,连接前需要创建好
'USER':'root', # 连接数据库的用户名
'PASSWORD':'', # 连接数据库的密码
'HOST':'127.0.0.1', # 连接主机,默认本级
'PORT':3306 # 端口 默认3306
},
'app01': { #可以为每个app都配置自己的数据,并且数据库还可以指定别的,也就是不一定就是mysql,也可以指定sqlite等其他的数据库
'ENGINE': 'django.db.backends.mysql',
'NAME':'bms', # 要连接的数据库,连接前需要创建好
'USER':'root', # 连接数据库的用户名
'PASSWORD':'', # 连接数据库的密码
'HOST':'127.0.0.1', # 连接主机,默认本级
'PORT':3306 # 端口 默认3306
}
}