1.字节缓存的基本原理
数据压缩也被称作基本压缩,或无损压缩,一般采用 LZ 系列压缩算法。数据压缩具有自包
含性:即对端解压缩方只根据数据包本身:即可进行解压还原,不需要其它任何信息。压缩比因数
据类型而异:文本数据压缩比最大,各种网页、Windows office 文件(Excel、word 等等)、PDF 其
次,对多媒体和已压缩数据基本无效。字节缓存技术又叫“字典缓存”或“超级压缩”等名称。
它通过缓存的方式在内存和硬盘中记录下流经的数据流,并以一定的大小(例如 32 字节、64 字
节或 128 字节等)为最小单位建立易于查询的索引。当以后流向广域网链路的数据流出现了大于
最小单位的相同数据时,可以将该数据替换成某个更短的符号。远端的设备能够将相应符号还原
成原始数据。
字节缓存与数据压缩的不同之处是,字节缓存不具有自包含性。要解开压缩数据,对端设备
必须引用以前记录的历史缓存信息。为达到这一目的,字节缓存技术需要连接两端的缓存完全同
步,于是需要在每条广域网链路两端的加速设备之间建立缓存数据同步机制。对比于数据压缩,
字节缓存的另一优势是即使对本身不具可压性的数据类型,如多媒体或已压缩数据,只要曾经传
输过相同或类似数据,字节缓存即可以提取出全部或部分相同数据,从而大幅缩减需要传输的数
据量。字节缓存技术通过使用大量的缓存信息(包括该数据流本身以前的数据历史和其他数据流
的数据历史)来压缩当前数据,有时能够达到非常高的压缩比。
2.MODP
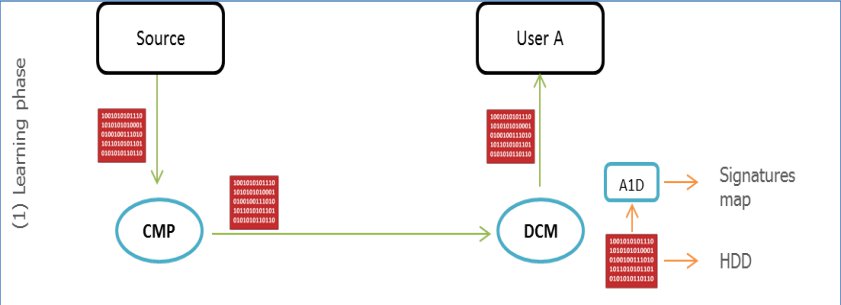
MODP这种技术首先应用于在一个大的文件系统中查找相似的文件。这种技术之所以叫MODP是由于使用了
取模运算和所有样本中的1/p样本被取样。使用MODP的系统如下图所示:

假设数据从左侧服务器发送到右侧服务器。当数据包通过MODP(图中 左侧的LotWan),数据包中的重复部分将被替换为
Label,而在对端的MODP(图中右侧的LotWan)将Label替换成真正的数据。因此我们面对的问题就是如何提高查找重复数据
的命中率!
2.1 指纹计算
我们可以用Rabin指纹来标识数据包。其定义如下:

Rabin指纹定义了一系列长度为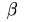 的字节序列。当以
的字节序列。当以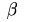 为窗口值和单个字节递增的方式就可以计算整个数据包的指纹。这种
为窗口值和单个字节递增的方式就可以计算整个数据包的指纹。这种
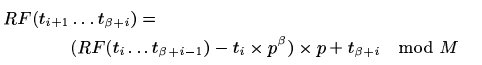
的字节序列。当以为窗口值和单个字节递增的方式就可以计算整个数据包的指纹。这种
指纹计算方法的一个优势就是下一个指纹可以通过上一个指纹计算出来,如下所示:
因此当我们有上一个指纹时,我们就可以通过一个减法,一个乘法,一个加法和一个取模计算出下一个指纹值。通过
提前计算 可以优化此步骤。
可以优化此步骤。
可以优化此步骤。
2.2 指纹选择
由于指纹是按字节递增计算,指纹的总数接近于字节总数,因此实现上不可能将所有的指纹取样。重复数据
对位置非常敏感,我们也不可以按固定位置来选择指纹,只要调整一个字节就会影响后面指纹的计算。因此我们
就需要选择部分指纹用于表示数据包。因为指纹都是随机和均匀分布,在实现上可以选择指纹值的后p位为0的用于取样。
2.3 算法
MODP中需要一个字典来存放最近缓存的数据包,字典通过标识数据包的指纹进行索引。对于一个需要缓存的数据包的
伪代码如下:
1 def handle_packet(payload): 2 for i in paylod: 3 rf = hash(i) //计算指纹 4 if check(rf): //确认指纹是否符合取样标准 5 if cache.find(rf): //是否在字典中查找到相同的指纹 6 expand(rf) //向左和向右扩充匹配的字符串 7 cache.rset(rf) //更新此指纹对于的数据包,如果原数据包没有在其他地方引用,可以释放。 8 else: 9 cache.set(rf): //用此指纹更新字典
2.4 应用举例:
华夏的AppEx应该是使用类似技术。AppEx 首先使用全部缓存信息及字典索引对超过 64 字节的长数据模式进行快速智能匹配,再利用局部缓存信息匹配短数据串(超过 8 字节即可完成匹配),最后再对结果进行 LZ 压缩。通过三级压缩过程,数据的冗余成分被完全提取。
通常数据压缩和字节缓存功能由于对数据进行了复杂处理,并且处理中可能涉及到硬盘读写,往往引入可观的延迟。对某些实时性要求较高的应用,显著增加的延迟可能会带来用户体验的明显下降。为最大限度的降低这一副作用, AppEx 设计了独特的内存硬盘二级缓存及字典结构,动态智能判断最可能被使用的数据,并将其置于内存中。同时根据当前连接匹配情况智能判断接下来需要的历史记录,并提前调入内存中。除此之外,AppEx 还动态监控数据延迟,在必要时改变压缩方式(如只采用 LZ 压缩等方式)以控制延迟引入。这一独特的延迟的控制为用户带来整体应用体验的提升。
2.5 存在的问题:
- 为了让hash冲撞的可能性尽可能的小,选择hash的槽数为2的60次方,在实现上这样明显不可以行,因此需要二级hash来实现,这样的话就有可能数据没有在二级hash表上均匀分布,从而导致查找的时间过长。
- 在选择样本的时候,我们只选择了指纹值后p位为0的值,这样导致会导致重复数据没有被选取。
- 需要考虑发送端和接收端之间的数据一致性。
3.PACK
PACK是一种低延迟、低CPU开销的TRE(traffic redundancy elimination)技术。PACK设计需要TCP扩展项的支持,
因此PACK可以支持所有应用TCP的应用程序。PACK是一种基于接收端TRE技术,而发送端不需要缓存数据并进行过多的计算。
3.1 PACK的处理流程如下:

如上图,PACK对TCP的三次握手和数据发送都进行了一定的修改。
3.2 数据的缓存
PACK的数据缓存类似于LBFS(A Low-bandwidth Network File System)。PACK和MODP一样,
需要考虑如何标识已经接收的历史数据。对于接收数据的处理如下:
1 def handle_data(payload): 2 for i in payload: 3 rbhash = hash(i) //第一步:计算数据包的Rabin指纹 4 if check(rbhash): //第二步:根据标准选取数据包的分割点,通过分割点将数据包分割的长度近似500字节。 5 setbound(i)
第一步中我们按48bits来计算Rabin指纹,使用这种方法是因为Rabin指纹是位置无关的。第二步
只有最小的12或13位的值等于预定值的Rabin指纹才会被用来作为分割点。如下图:
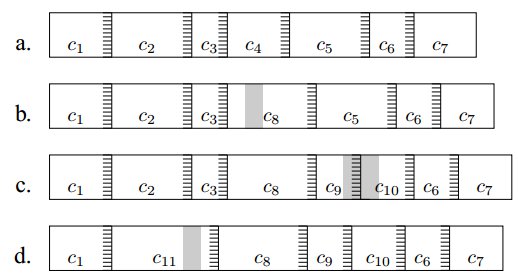
假如a为一个数据包初始的状态,当数据包b中之是修改了c4的时候,那么只会影响c4而不会影其余的数据块。
数据包c的修改也只是影响了c5,数据包d的修改只是影响了c2和c3。
对数据包进行分割后,将数据块计算SHA后会存入字典,但是此字典有两个特别之处:
- 在字典中的数据块会用用指针建立链表,其顺序就是数据块在数据包中的顺序。
- 此字典需要将以往所有接收的数据进行缓存。
3.3 接收端算法
接收端的主要功能:
- 验证发送端送来的数据是否已经缓存,如果缓存发送预测数据。
- 如果发送端送的数据是新数据,添加到字典。
算法的伪代码如下:

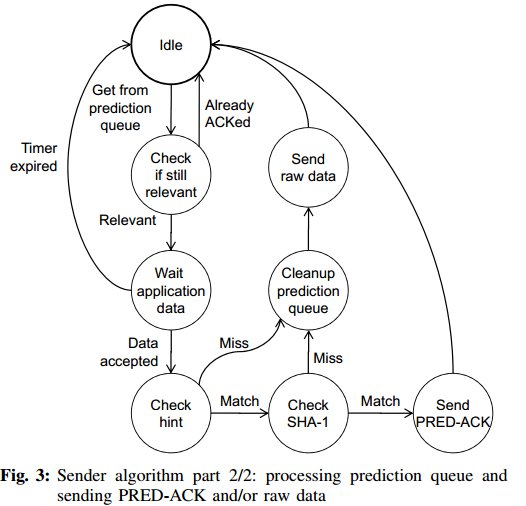
3.4 发送端算法
发送端的主要功能就是当接收端发来预测信息后,验证发送缓冲区的数据是否和预测信息匹配。
通过状态机来描述发送端算法。

3.5 应用

3.6 待考虑的问题
- PACK应该会影响TCP的其他功能,如TCP Retransmission、Delayed ACKs、Round-Trip Time Measurements 等。
- PACK的字典中并没有实际的数据,需要考虑实际数据的存放。
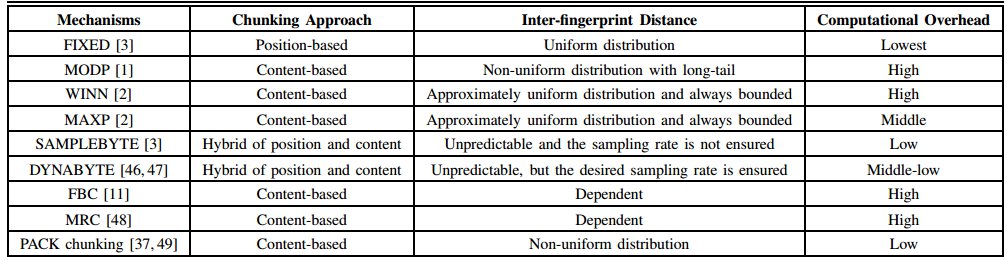
4.常用的字节缓存技术

参考资料
[1] A Protocol-Independent T echnique for Eliminating Redundant Network Traffic
[2] A Low-bandwidth Network File System
[3] PACK: Speculative TCP Traffic Redundancy Elimination
[4] On Protocol-Independent Data Redundancy Elimination
[5] HyperCompression 低延迟深度压缩技术白皮书
[6] DiViNetworks Compression Technology