2020—2021—1学期20202405《网络空间安全导论》第四周学习总结
学习内容:《计算机科学概论》第8、9章
周五听了课后又一次认真读了教材,巩固了第六章、第七章的学习,这个周末我就开启了第八章第九章的学习。
第八、九章是《计算机科学概论》的第四部分——程序设计层的第二个小部分。上节课谢老师说,第六章到第九章是本书的核心内容,对日后的学习有很大的帮助,必须经常翻书看一看,才能有所收获,所以这两章的重要性自然不言而喻,带着这种压力,紧接着上一章所学的知识,下面我系统的梳理一下我自学到的的知识。
第8章: 抽象数据类型与子程序
上一章我们讨论了一种思想——抽象,在这一章我们进一步谈论抽象和抽象容器,我们知道操作和它们做的事情,却不知道操作是如何实现的。
8.1抽象数据类型
首先我们了解一下抽象数据类型的定义:
抽象数据类型(ADT):属性(数据和操作)明确地与特定实现分离的容器。
设计的目标是通过抽象减小复杂度。
把ADT与上下文联系起来需要知道如何观察数据。在计算机领域可以从应用层、逻辑层和实现层观察数据。
应用(用户)层是特定问题中的数据的视图。
逻辑(抽象)层是数据值(域)和处理它们的操作的抽象视图。
实现层明确表示出了存放数据项的结构,并用程序设计语言对数据的操作进行编码。这个视图用明确的数据域和子程序表示对象的属性。这一层涉及了数据结构:
数据结构:一种抽象数据类型中的复合数据域的实现。
这一章的抽象数据类型是在现实世界的问题中反复出现过的,这些ADT是存储数据项的容器,每种ADT都具有特定的行为,称它们为容器。
容器:存放和操作其他对象的对象。
8.2栈
栈是一种抽象复合结构。总结一下:
①只能从一端访问栈中的元素,可以从第一个位置插入元素,也可以删除第一个元素:这种类型的处理称为LIFO,意思是后进先出。(可以类比一下餐厅拿走第一个盘子才能让第二个盘子变成第一个。)
②删除的项总是在栈中时间最短的项目。插入操作没有任何约束;整个LIFO行为就体现在删除操作上。
③插入操作叫做Push(推进),删除操作叫做Pop(弹出)。
④栈没有长度属性,所以没有返回栈中项目个数的操作。我们需要的是确定栈是否为空的操作,因为当栈空的时候再弹出项目会出错。
8.3队列
队列也是一种抽象结构,但是:
①队列中的项目只能从一端入,从另一端出,这种行为称为FIFO,意思是先进先出。(类比一下超市排队)
②删除的总是在队列中时间最长的项目。插入操作没有任何约束,整个FIFO行为就体现在删除操作上。
③插入操作和删除操作没有标准的相关术语!插入操作在队列的尾部进行,删除操作在队列的头部进行。
书上的例子上,按照相反顺序输出,那就利用栈(先进后出嘛),反之就用队列~
8.4列表
列表有三个属性特征:项目是同构的、项目是线性的、列表是变长的。(线性:每个项目除了第一个都有一个独特的组成部分在它之前,除了最后一个也都有一个独特的组成部分在它之后。)
列表通常提供插入一个项目的操作、删除项目的操作、检索一个项目是否存在以及报告列表中项目数量,还有机制允许用户查看序列中的每一项。因为项目可以被删除和检索,所以列表中的项目必须能够相互比较。
| 操作 | |
|---|---|
| 插入 | Insert |
| 删除 | Delete |
| 检索 | IsThere |
| 报告数量 | GetLength |
| 查看每一项 | Reset、GetNext、Moreltems |
不要把列表误认为是数组!!!!! 数组是内嵌结构,而列表时抽象结构。但是列表应用于数组之中。
列表也可以被形象化为链式结构,链式结构以节点的概念为基础,一个节点由两部分构成:用户的数据和指向列表的下一个节点的链接或指针。列表的最后一个节点的指针变量存放的是表示列表结束的符号,通常是null,用“/表示。
链式结构:一个将数据项和找到下一项位置的信息保存到同一容器的实现方法。
无序列表的顺序并不重要,项目只是随意被放入其中。有序列表中,项目之间具有语义关系。除了第一个项目之外所有项目都存在某种排序关系。除了最后一个项目所有项目都有着相同的关系。
8.5树
因为之前提到的本质上都是线性的,只模拟了一种数据关系。如果我们想模拟比较复杂的数字关系(比如动物阶层)就需要一种具体的分层体系——树。在计算领域,我们通常说的是二叉树,即每个节点最多有两个子节点的树。
8.5.1二叉树
二叉树是一种抽象结构,其中每个节点可以有两个后继节点,叫做子女,这些子女也可以有自己的子女,依此类推就形成了树的分支结构。树的头部是一个起始节点,叫做根,它不是任何节点的子女。
如果一个节点左边的子节点存在,那么这个子节点叫做左子女,反之右边的子节点存在,叫做右子女。如果一个节点没有子女。则这个节点叫做树叶。
二叉树:具有唯一起始节点(根节点)的抽象复合结构,其中每个节点可以有两个子女节点,根节点和每个节点之间都有且只有一条路径。
根:树中唯一的开始节点。
叶节点:没有子女的树节点。
此外,根节点和每个节点之间有且只有一条路径,就是说,除了根节点外,每个节点都只有一个父母节点。
根节点的每个子女本身又是一个小二叉树或子树的根。事实上,树中每个节点都可以被看作一个子树的根。根节点是树中其它所有节点的先辈。(可以想象成高中生物学的系谱图)
8.5.2二叉检索树
二叉检索树就像已排序的列表,节点间存在语义排序。二叉检索树具有二叉树的形状属性,还具有语义属性来刻画树中节点上的值,即任何节点的值都要大于它的左子树中的所有节点的值,并且要小于它的右子树中的所有节点的值。
8.5.2.1在二叉检索树中搜索
(相似于第七章学的线性结构的二分检索法)
如果current指向一个节点,那么info(current)指的就是这个节点中的用户数据,left(current)指向的是current的左子树的根节点,right(current)指向的是current的右子树的根节点。null是一个特殊值,说明指针指向空值。
根据书上给出的算法,理解了在二叉检索树中搜索的过程。

8.5.2.2构造二叉检索树
书上用一个具体例子为我们讲述了如何构造二叉检索树。我刚开始没有弄明白书上是怎么比较字符串之间的大小的,后来询问了谢老师,才知道原来是按照ASCII字符集比较的,懂了懂了~
8.5.2.3输出二叉检索树中的数据
根据书上给出的一个看似很容易的算法,我也是努力去看了输出这个树的过程,终于看明白了,激动。
8.5.3其他操作
终于意识到,二叉检索树其实是和列表具有同样功能的对象,它们的区别在于操作的有效性,而行为是相同的。
书上引出了Length操作的递归:

这个显而易见吧,很好理解。
8.6图
树有一种约束,也就是一个节点至多只有一个指向它的节点(父母),如果去掉这种约束,就得到了另外一种数据结构——图。图由一组节点和连接节点的线段构成。
图:由一组节点和一组把节点相互连接起来的边构成的数据结构。
顶点:图中的节点。
边(弧):表示图中两个节点的连接的顶点对。
图中的顶点表示对象,那么边则描述了定点之间的关系。这种图分为两种:
无向图:其中的边没有方向的图。
有向图:其中的边是从一个顶点指向另一个顶点(或同一个顶点)的图。
如果两个顶点有一条边相连,则把他们称为邻顶点,两个顶点通过一条有顺序的路径相连。
8.6.1创建图
列表、栈、队列和树都是可容纳元素的容器。用户根据特定的问题选择最合适的容器,不被纳入检索过程的算法是没有固定语义的:栈返回的元素是在其中停留时间最少的元素。队列返回的是在其中停留时间最长的元素。队列和树返回的信息都是被请求的。然而不同的是,在图中定义的算法可以解决实际的问题。
8.6.2图算法
8.6.2.1深度优先搜索

这种搜索叫做深度优先搜索,因为我们走向最深的分支。但你必须回溯时,选择离你无法走通位置的最近的分支继续搜索。相比于更早时候可选的其他分支,你会选择一条尽可能可以走远的路。
但是我还是觉得这个算法太难以理解了。
8.6.2.2广度优先搜索
因为栈是按照元素出现的相反顺序来保存元素,而现在我们想回溯到尽可能远,以找到从最初的顶点出发的路径。那么我们就不再适合用栈了,在这次我们只要把栈替换成队列,就可以成功。
深度优先搜索算法从起点出发尽可能地往更远的路径检查,而不是优先选择检查与起点相邻的第二个顶点。相反,广度优先搜索会优先检查所有与起点相邻的顶点,而不是检查与这些顶点相连的其他顶点。
8.6.2.3单源最短路搜索
还是以从两个城市之间的航班为例。就比如说我想从北京跑回到我的家乡葫芦岛,我就肯定得走一条路程最短的路啊,要不然就累死了(我承认无论怎么样,我要是跑回去都得累死),就这么个意思,所以这个时候我们就需要单源最短路搜索了。我们需要辅助的数据结构存储此后处理的城市,最后广度优先搜索算法可以找到最小换成次数的航线。但是这并不代表最短的总距离。最短路遍历必须说明在搜索过程中城市间的距离,而不是像深度优先搜索和广度优先搜索一样。我们想要检索当前顶点最近的顶点,也就是与此顶点相连的边权值最小的顶点。我们称这种抽象容器为优先队列,被检索的元素是在队列中拥有最高优先度的元素,比如这里,我们就让距离数最为优先,则可以弹出一系列包括两个顶点和两个顶点间距离的元素。
8.7子程序
许多子程序都是高级语言或语言附带库的一部分。如果一个子程序需要传递信息,调调用单元将会把值发送给子程序来使用。
8.7.1参数传递
参数列表是子程序要使用标识符或值的列表,它放置在子程序名后的括号中。由于子程序是在被调用之前定义的,所依它不知道调用单元会传递什么样的变量。为了解决这个问题,在子程序后面的括号中声明了一个变量名的列表。这些标识符称为形参。当子程序被调用时,调用单元将列出子程序名,并在其后的括号中列出一系列标识符。这些标识符叫做实参。实参表示的是调用单元中的真实变量。
参数列表:程序中两部分之间的通信机制。
形参:列在子程序名后的括号中的标识符。
实参:子程序调用中列在括号中的标识符。
可以把形参看成是子程序中使用的临时标识符。当子程序被调用时,调用单元会把真正的标识符的名字发送给子程序。子程序中的动作则是用形参定义的。当动作执行时,实参将逐个替代形参。
当子程序被调用时候,它将得到一个实参列表。实参将告诉子程序在哪里可以找到它要用的值。当子程序用到第一个形参时,子程序会通过形参在留言板上的相对位置访问实参。调用子程序时传递的实参个数必须与子程序定义中的形参个数相同。但是形参和实参是通过位置匹配的,所以名字不必一致。以这种方式传递的形参通常叫做位置形参。
8.7.2值参与引用参数
传递参数的基本方式有两种,即通过值传递和通过引用传递。如果一个形参是值参,调用单元将把实参的一个副本传递给子程序。如果一个形参是引用参数,调用单元将把实参的地址传递给子程序。所以子程序不能改变实参内容(因为接受的只是一个副本),相反,子程序可以改变调用单元传递给引用参数的任何实参,因为子程序操作的是实际变量,而不是副本。
值参:由调用单元传入实参的副本的形参。
引用参数:由调用单元传入实参的地址的形参。
有的子程序是有返回值的,在这种情况下,子程序被调用的方式是用它的名字和参数的表达式;子程序也可能是没有返回值的,在这种情况下,调用程序用子程序的名字作为声明。
第9章: 面向对象设计与高级程序设计语言
在开始探索高级语言之前,我们需要了解面向对象的设计。面向对象的设计是审视设计过程的另一种方式,它从数据角度出发而非任务。因为程序的功能和设计过程在高级语言汇编过程中经常发生不匹配的情况,因此我们需要在探讨特定的高级语言之前理解这种设计的过程。
9.1面向对象方法
面向对象的设计方法是用叫做对象的独立实体生成解决方案的问题求解方法,对象由数据和处理数据的操作构成。面向对象设计的重点是对象以及它们在问题中的交互。一旦收集到了问题中的所有对象,它们就能构成问题的解决方案。
9.1.1面向对象
在面向对象的思想中,数据和处理数据的算法绑在一起,因此每个对象负责自己的处理。面向对象设计(OOD)的底层概念是类和对象。
对象:在问题背景中相关的食物或实体
对象类或类:一组具有相似的属性和行为的对象的描述
字段:表示类的属性
方法:定义了类的一种行为的特定算法
类是一种模式,说明了对象是什么以及它的行为。
9.1.2设计方法
分解过程有四个阶段:
1、头脑风暴:在面向对象的问题求解背景中,头脑风暴是一种集体行为,为的是生成解决某个特定问题要用到的候选类的列表。
2、过滤:头脑风暴下一阶段要根据暂时的列表确定问题解决方案中的核心类。一个列表中也许有的类根本不属于问题的解决方案,那么我们就需要过滤,完成过滤后就进入了下一个阶段。
3、场景:这个阶段的目标是给每个类分配责任,最终责任将被实现为子程序。
责任的类型有两种,即类自身必须知道什么(知识)和类必须能够做什么(行为)。类把它的数据(知识)封装了起来,使得一个类的对象不能直接访问另一个类中的数据。所谓封装,就是把数据和动作集中在一起,使数据和动作的逻辑属性与它们的实现细节分离。封装是抽象的关键。不过,每个类都有责任让其它类访问自己的数据。因此,每个类都有责任了解自身。
4、责任算法
(执行责任的算法一般都相当短)
5、总结
自顶向下的设计方法重点在于把输入转化成输出的过程,结果将生成任务的体系结构。面向对象设计的重点是要转换的数据对象,结果生成的是对象的体系结构。
9.1.3示例
面向对象的设计比自顶向下的设计更好,因为它创建的一些类还可以用于其他背景。可复用性是面向对象设计的一大优点。为一个问题设计的类还可以用于解决另一个问题,因为每个类都是自约束的,也就是说,每个类只负责自己的行为。
9.2翻译过程
第六章就提到,用汇编语言编写的程序要输入汇编器,由它把汇编语言指令翻译成机器码,最终执行的是汇编器输出的机器码。
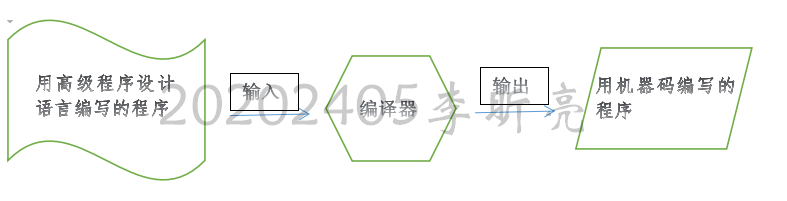
9.2.1编译器
翻译用高级程序设计语言编写的程序的程序叫做编译器。早期编译器输出的是程序的汇编语言版本,这个版本还要经过汇编器处理才能得到可执行的机器语言程序。但是随着科学家更加深入地了解翻译过程,编译器变得复杂,汇编语言的阶段通常被省略了。
任何计算机只要具有一种高级语言的编译器,就能运行用这种语言编写的程序。注意编译器是一种程序,所以要编译一个程序,就必须具有这个编译器在特定机器上的机器码版本。如果想在多种类型的机器上使用一种高级语言,就要具备这种语言的多个编译器。
9.2.2解释器
解释器:输入用高级语言编写的程序,指导计算机执行每个语句指定的动作的程序。
解释器与汇编器和编译器(只是输出机器码且机器码再单独执行)不同,它在翻译过语句之后会立即执行这个语句。
翻译器和模拟器都接受用高级语言编写的程序作为输入。翻译器(汇编器或编译器)只用适合的机器语言生成等价的程序,这个程序再单独运行。而模拟器则直接执行输入的程序。
——Terry Pratt
因为需要解释的语言编写的程序通常比要编译的程序的运行速度慢很多,所以要编译的语言发展成了主流,于是产生了Java
Java的设计中,可移植性是最重要的特征。为了达到最佳可移植性,Java被编译成一种标准机器语言——字节码。一种名为JVM的软件解释器接受字节码程序,然后执行它。也就是说,字节码不是某个特定硬件处理器的机器语言,任何具有JVM的机器都可以运行编译过的Java程序。
标准化的高级语言实现的可移植性与把Java程序翻译成字节码然后在JVM上解释它所实现的可移植性是不同的。Java编译器输出的程序将被解释,而不是直接被执行。
9.3程序设计语言范型
9.3.1命令式范型
命令式范型具有顺序执行指令的特征,变量的使用代表了内存地址,而是用赋值语句则改变这些变量的值。
9.3.1.1面向过程的范型
面向过程编程是一种命令式模型,在这里语句被分组成子程序。一个程序是子程序分层次构成的,每一层执行整个问题求解的一个必要的特定任务。
9.3.1.2面向对象的范型
面向对象视角是与对象交互的一种方式。每个对象负责执行它自己的动作。
在面向过程的范型中,数据被认为是被动并且被程序所操控的;在面向对象的范型中,数据对象是活跃的。每个对象负责控制自己的操作。
9.3.2声明式范型
声明式范型是一个描述结果的模型,但是完成结果的过程则不被描述。在这种范型中的两种基本模型:函数式和逻辑式。
9.3.2.1函数式模型
基于函数的数学概念。基本的原理是函数的求值。
9.3.2.2逻辑编程
基于数理逻辑的原则。解决潜在问题的算法用逻辑的规则来推演出事实和规则的答案。
9.4高级程序设计语言的功能性
命令式语言的标志就是两种伪代码结构——选择和重复(循环)。首先先分析一下布尔表达式:
9.4.1布尔表达式
写出语句然后测试是true还是false是程序设计语言提问的方式。这些语句称为断言或条件。编写算法是我们采用自然语言表示断言。翻译成高级程序语言时,这种用自然语言编写的语句就会被重写成布尔表达式。
布尔表达式是一个标识符序列,标识符之间由相容的运算符分隔,求得的值是true或false。
9.4.2数据归类
只能在变量中存储合适的类型的要求叫做强类型化。
数据类型是描述一组数值和一组可以应用在这种类型的数值上的基本操作。
大多数高级语言都有四种数据类型:整数、实数、字符和布尔型。
声明是把变量、动作或语言中的其他实体与标识符关联起来的语句,使程序员可以通过名字引用这些项目。
保留字是一种语言中具有特殊意义的字,不能用它作为标识符。
注意C++、Java、Python和VB.NET是区分大小写的,这意味着大小写不同的同一标识符会被认为是不同的词。
9.4.3输入/输出结构
高级语言把输入的文本数据看作一个分为多行的字符流。字符的含义由存放值的内存单元的数据类型决定输出与基础所有输入语句都由三部分构成:要存放数据的变量的声明、输入语句和要读入的变量名以及数据流自身。
在非强类型语言中,输入的格式决定了类型。 输出语句创建字符流。在强类型语言中不管输入输出语句的语法或输入输出流在哪,处理的关键在于数据类型。数据类型确定字符是如何被转换为位模式以及如何被转换为字符。
9.4.4控制结构
重复、选择和子程序,这种结构叫做控制结构,因为他们决定了其他指令在程序中被执行的顺序。
1、嵌套逻辑
2、异步处理
异步:不与计算机这种的其他操作同时发生。
9.5面向对象语言的功能性
9.5.1封装
封装:实施信息隐蔽的语言特性
对象(问题求解阶段):与问题背景相关的事物或实体
类(实现阶段):对象的模式
对象类或类(问题求解阶段):属性和行为相似的一组对象的说明
对象(实现阶段):类的一个实例
9.5.2类
如果用标识符来代表一个类,那么必须在使用前显式地询问即将被创建的类。也就是需要实例化这个类,以获取符合这种模式的对象。
实例化:创建类的对象
9.5.3继承
继承:类获取其他类的属性(数据字段和方法)的机制
9.5.4多态
多态是语言在运行时确定给定调用将执行哪些可能的方法的能力。
9.6过程设计与面向对象设计的区别
总结与反思
自学了这么多内容,有很多东西不是很理解。比如说第八章的搜索与参数还有第九章部分概念,但是还是有很大收获,也更加巩固了之前的知识,再接再厉。
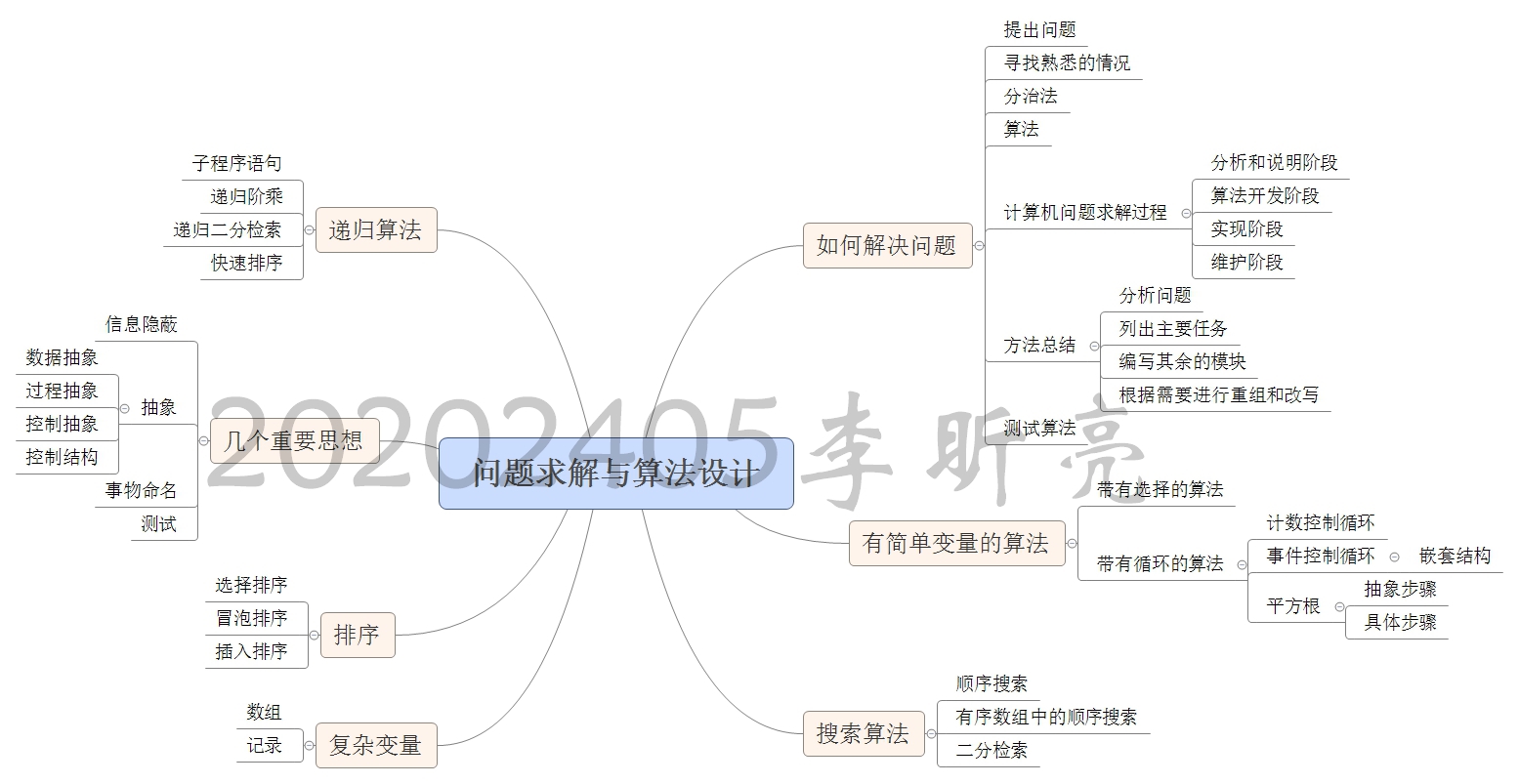
思维导图
用两张思维导图“来个了断”吧~