一、pipeline出现的背景:
redis客户端执行一条命令分4个过程:
发送命令-〉命令排队-〉命令执行-〉返回结果
这个过程称为Round trip time(简称RTT, 往返时间),mget mset有效节约了RTT,但大部分命令(如hgetall,并没有mhgetall)不支持批量操作,需要消耗N次RTT ,这个时候需要pipeline来解决这个问题。
二、pepeline的性能
1、未使用pipeline执行N条命令
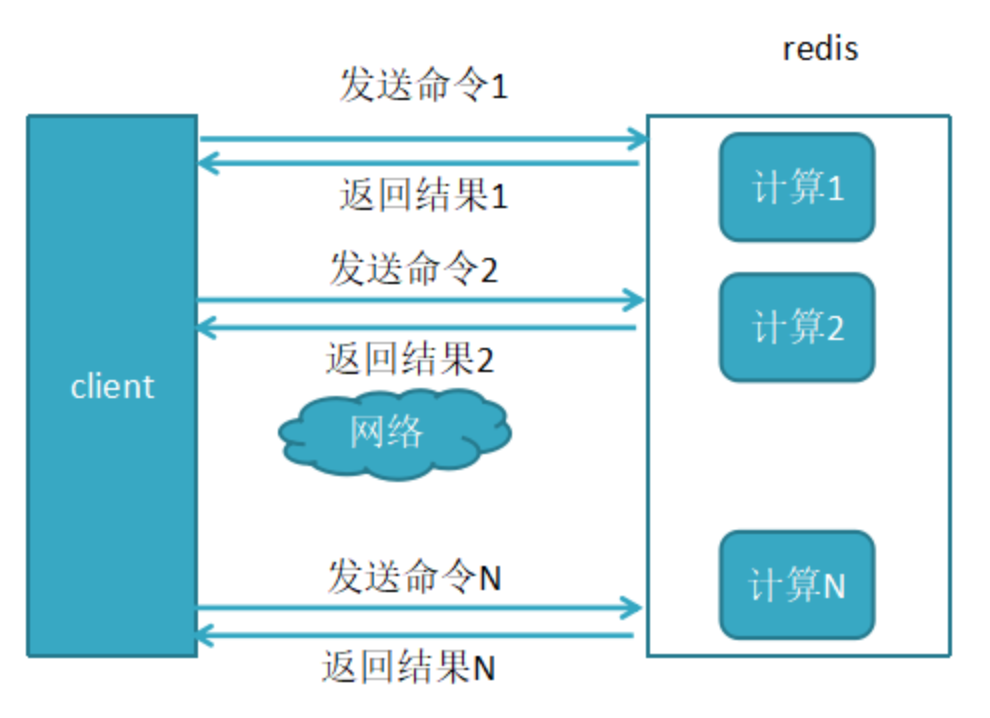
2、使用了pipeline执行N条命令

3、两者性能对比
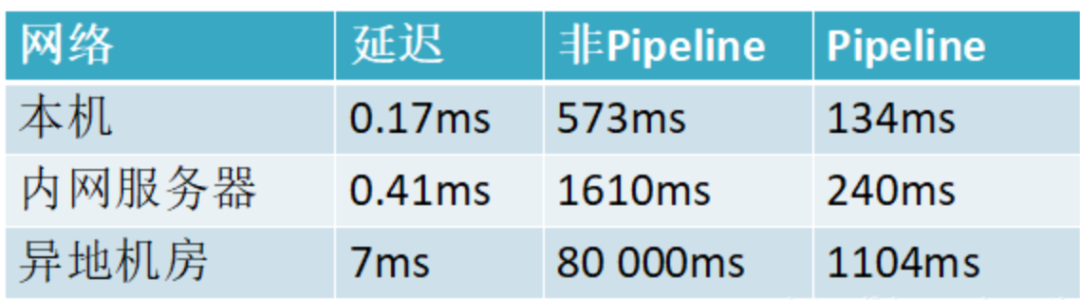
小结:这是一组统计数据出来的数据,使用Pipeline执行速度比逐条执行要快,特别是客户端与服务端的网络延迟越大,性能体能越明显.
三、原生批命令(mset, mget)与Pipeline对比
1、原生批命令是原子性,pipeline是非原子性
(原子性概念:一个事务是一个不可分割的最小工作单位,要么都成功要么都失败。原子操作是指你的一个业务逻辑必须是不可拆分的. 处理一件事情要么都成功,要么都失败,原子不可拆分)
2、原生批命令一命令多个key, 但pipeline支持多命令(存在事务),非原子性
3、原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成
四、Pipeline正确使用方式
在下面代码里,我用了一个用户名数组,数组元素的key值是用户对应的id,一旦用户修改了其用户名,我将修改两个redis值:
-
当前用户其用户名修改次数需要+1
-
更新当前用户对应的用户名数据
$redis = new Redis();
//开启管道模式,代表将操作命令暂时放在管道里
$pipe = $redis->multi(Redis::PIPELINE);
//循环遍历数据,执行操作
foreach ($users as $user_id => $username)
{
//用户名修改次数+1
$pipe->incr('changes:' . $user_id);
// 更新用户名
$pipe->set('user:' . $user_id . ':username', $username);
}
//开始执行管道里所有命令
$pipe->exec();管道里放什么操作,并没有什么限制,即使你放获取数据的操作也是ok的。
现在就假设我们要给某个redis key值+1,但是获取另一个redis key值的value数据。
如下代码就是一个操作是更新某个用户被访问的次数,另一个操作则是获取用户信息数据。
$redis = new Redis();
//开启管道模式
$pipe = $redis->multi(Redis::PIPELINE);
//循环遍历数据,执行操作
foreach ($users as $user_id => $username)
{
// 用户被访问的次数+1
$pipe->incr('accessed:' . $user_id);
// 获取用户数据记录
$pipe->get('user:' . $user_id);
}
// 开始执行管道里所有命令
$users = $pipe->exec();
// 打印数据
print_r($users);
注意,由于管道里每一条命令都会返回数据,所以最终打印的数组,会含有incr操作带来的记录,还有从获取用户操作那里拉下来的redis key值作为了打印数组的索引值。
不过有个好处,管道里每个操作命令返回的数据是按照管道里顺序存储的,key值是0,1,2这种。我们想要啥数据,自己稍微处理一下就好啦。
如果我们像取消管道操作,用下面代码即可:
$pipe->discard();总结:pipeline 虽然好用,但是每次pipeline 每次组装的命令个数不能没有节制,否则一次组装pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的pipeline拆分成多次较小的pipeline来完成。


