awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk的用法
awk 'BEGIN{ commands } pattern{ commands } END{ commands }'第一步:运行BEGIN{ commands }语句块中的语句。
第二步:从文件或标准输入(stdin)读取一行。然后运行pattern{ commands }语句块,它逐行扫描文件,从第一行到最后一行反复这个过程。直到文件所有被读取完成。
第三步:当读至输入流末尾时,运行END{ commands }语句块。
BEGIN语句块在awk開始从输入流中读取行之前被运行,这是一个可选的语句块,比方变量初始化、打印输出表格的表头等语句通常能够写在BEGIN语句块中。
END语句块在awk从输入流中读取全然部的行之后即被运行。比方打印全部行的分析结果这类信息汇总都是在END语句块中完毕,它也是一个可选语句块。
pattern语句块中的通用命令是最重要的部分,它也是可选的。假设没有提供pattern语句块,则默认运行{ print },即打印每个读取到的行。awk读取的每一行都会运行该语句块。
这三个部分缺少任何一部分都可以。
可用awk来统计固定格式日志里的一些数据,如日志中出现过所有不同的IP
awk ‘{i=$1;count[i]++}END{for(i in count)print(i,count[i])}’ /var/log/httpd/access_logawk对文件进行流处理,每次读取一行。$1就是IP,count[i]++是将IP作为一个数组的下标,并且使得统计这个IP所对应的数组元素自增1.END后面的语句是打印结果,只执行一次。
也可以用来找出访问次数最多的ip。
awk '{a[$1] += 1;} END {for (i in a) printf("%d %s\n", a[i], i);}' 日志文件 | sort -n | tail -n 10 #用tail显示最后10行首先用awk统计出来一个列表,然后用sort进行排序,最后用tail取最后的10个。
以上参数可以略作修改显示更多的数据,比如将tail加上-n参数等,另外日志格式不同命令也可能需要稍作修改。
当前WEB服务器中联接次数最多的ip地址
netstat -ntu |awk '{print $5}' |sort | uniq -c| sort -nr查看日志中访问次数最多的前10个IP
cat access_log |cut -d ' ' -f 1 | sort |uniq -c | sort -nr | awk '{print $0 }' | head -n 10 | less查看日志中出现100次以上的IP
cat access_log |cut -d ' ' -f 1 | sort |uniq -c | awk '{if ($1 > 100) print $0}'|sort -nr | less查看最近访问量最高的文件
cat access_log | tail -10000 | awk '{print $7}' | sort | uniq -c | sort -nr | less查看日志中访问超过100次的页面
cat access_log | cut -d ' ' -f 7 | sort |uniq -c | awk '{if ($1 > 100) print $0}' | less统计某url,一天的访问次数
cat access_log | grep '12/Aug/2009' | grep '/images/index/e1.gif' | wc | awk '{print $1}'前五天的访问次数最多的网页
cat access_log | awk '{print $7}' | uniq -c | sort -n -r | head -20从日志里查看该ip在干嘛
cat access_log | grep 218.66.36.119 | awk '{print $1"\t"$7}' | sort | uniq -c | sort -nr | less列出传输时间超过 30 秒的文件
cat access_log | awk '($NF > 30){print $7}' | sort -n | uniq -c | sort -nr | head -20列出最最耗时的页面(超过60秒的)
cat access_log | awk '($NF > 60 && $7~/\.php/){print $7}' | sort -n | uniq -c | sort -nr | head -100查看23:27分,访问api/v1开头的接口
cat access-2020-09-06.log | grep 2020-09-06T23:27|grep /api/v1cat access-2020-09-06.log | grep 2020-09-06T23:27|grep /api/v1|wc -l //api/vi 开头接口多少行发现系统存在的问题
我们可以使用下面的命令行,统计服务器返回的状态码,发现系统可能存在的问题。
awk '{print $9}' access.log | sort | uniq -c | sort正常情况下,状态码 200 或 30x 应该是出现次数最多的。40x 一般表示客户端访问问题。50x 一般表示服务器端问题。
下面是一些常见的状态码:
- 200 - 请求已成功,请求所希望的响应头或数据体将随此响应返回。
- 206 - 服务器已经成功处理了部分 GET 请求
- 301 - 被请求的资源已永久移动到新位置
- 302 - 请求的资源现在临时从不同的 URI 响应请求
- 400 - 错误的请求。当前请求无法被服务器理解
- 401 - 请求未授权,当前请求需要用户验证。
- 403 - 禁止访问。服务器已经理解请求,但是拒绝执行它。
- 404 - 文件不存在,资源在服务器上未被发现。
- 500 - 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。
- 503 - 由于临时的服务器维护或者过载,服务器当前无法处理请求。
HTTP 协议状态码定义可以参阅:Hypertext Transfer Protocol -- HTTP/1.1
有关状态码的 awk 命令示例:
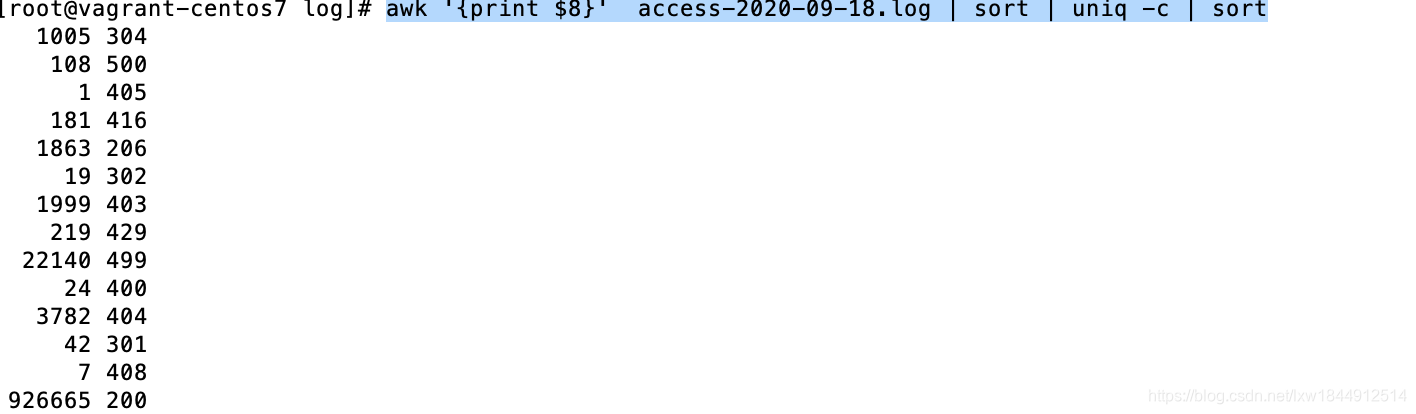
awk '{print $8}' access-2020-09-18.log | sort | uniq -c | sort //日志文件中装态码统计1. 查找并显示所有状态码为 404 的请求
awk '($9 ~ /404/)' access.log awk '($8 ~ /404/)' access-2020-09-18.log|head -20 
2. 统计所有状态码为 404 的请求(不带搜索文件的,不能用)
awk '($9 ~ /404/)'3.查询特定接口,状态码不是200的
awk '($8 !=200)' access-2020-09-18.log|grep "/api/v1/user/updateHeadImg"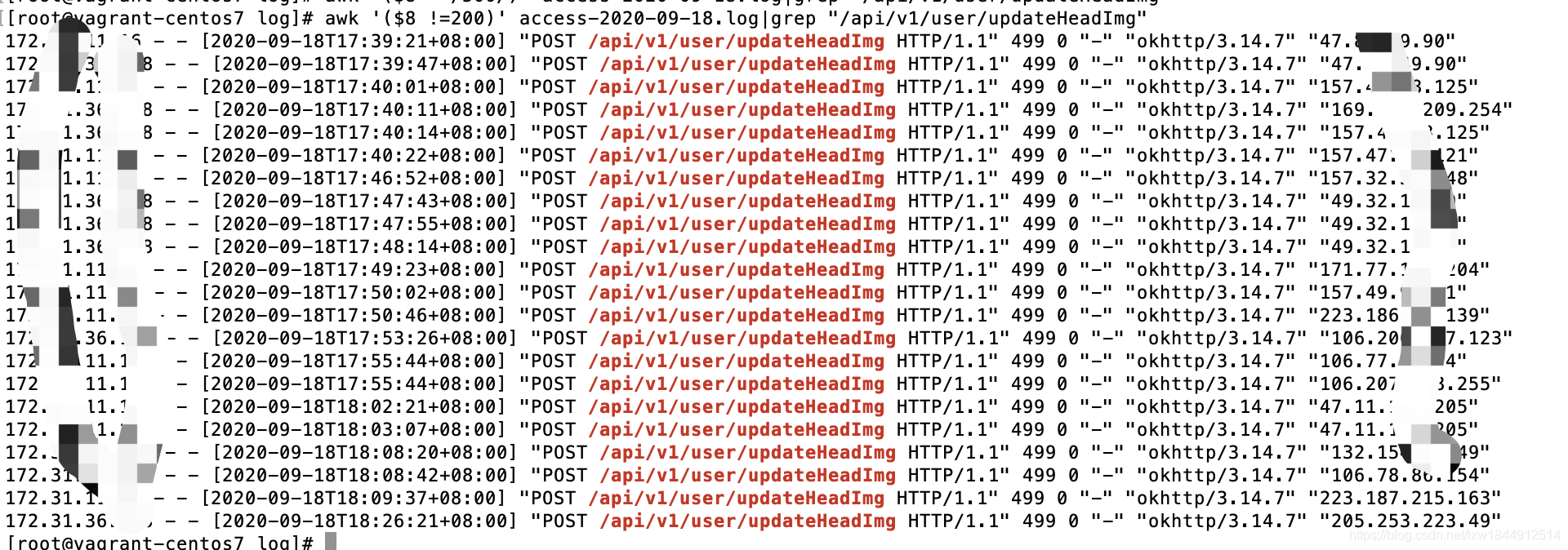
awk '($8 =499)' access-2020-09-18.log|grep "/api/v1"|head -n 100000|tail -n 95000 //状态码为499的特定接口,第95000至10万行
