scala源码
import org.apache.spark.{SparkConf, SparkContext} import scala.collection.JavaConverters._ object a { def main(args: Array[String]): Unit = { if(args == null || args.length == 0){ throw new Exception("指定文件路径") } val conf = new SparkConf() conf.setAppName("标签生成") val sc = new SparkContext(conf) val rdd1 = sc.textFile(args(0)) val rdd2 = rdd1.map(s => { val sp = s.split(" ") val lst = JSONUtil.parseJson(sp(1)) (sp(0), lst) }).filter(_._2.size() > 0) val rdd3 = rdd2.flatMapValues(_.asScala).map(t=>((t._1,t._2),1)).reduceByKey((a,b)=>a+b).groupBy(_._1._1).mapValues(_.map(t=>(t._1._2,t._2))) val rdd4 = rdd3.mapValues(_.toList.sortBy(-_._2)).sortBy(-_._2(0)._2) val rdd5 = rdd4.collect() Thread.sleep(100000) } }
java解析json串工具类
import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONArray; import com.alibaba.fastjson.JSONObject; import java.util.ArrayList; import java.util.List; public class JSONUtil { private JSONUtil(){} public static List<String> parseJson(String line) { List<String> list = new ArrayList<String>(); JSONObject jsonObject = JSON.parseObject(line); JSONArray extInfoList = jsonObject.getJSONArray("extInfoList"); if(extInfoList != null && extInfoList.size() != 0){ for (Object o : extInfoList) { JSONObject jo = (JSONObject)o; if(jo.get("title").equals("contentTags")){ JSONArray values = jo.getJSONArray("values"); for (Object value : values) { list.add(value.toString()); } } } } return list; } }
依赖
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
</dependencies>
</project>
1、生成jar包
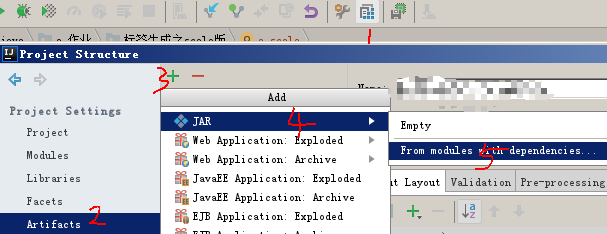
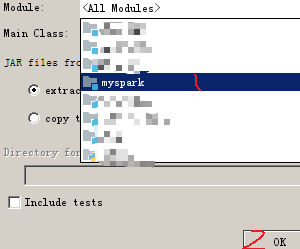
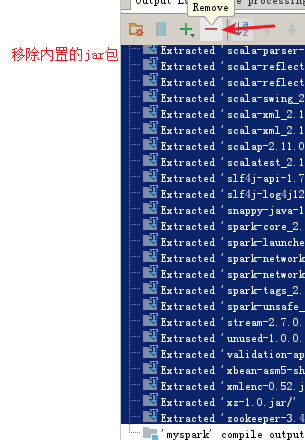
注:以下3是把json包打散和自己的myspark目录生成一个jar包,如果选put则是一个json jar包
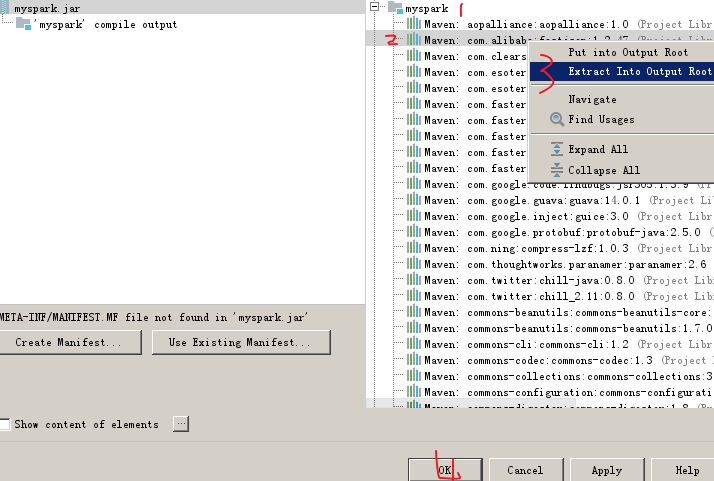

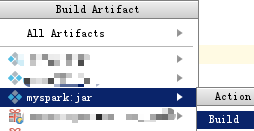
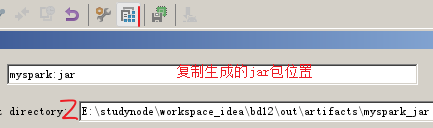

2、将jar包和源文件上传到HDFS
3、spark-submit 提交应用
spark-submit --class a --master spark://s101:7077 --deploy-mode cluster hdfs://s101/myspark.jar temptags.txt
//部署模式分:client、cluster,本次是cluster模式,driver由master分配
//a 全类名执行入口
//hdfs://s101/myspark.jar打包的jar文件,集群部署模式下,jar在hdfs上
//temptags.txt 待处理的源文件,hdfs中