机器学习小工具集合
我!李英俊!觉得这篇文章超级有用!值得你一看!
功能: 机器学习工具集合,直接导入一个类,传参训练集,验证集就能生成报告
使用方式:
- 需要自己传入X_train, y_train, X_test, y_test作为输入(并没有用交叉验证,因为我在用的时候考虑到了样本不均衡的问题,交叉验证无法分层采样),下面有鸢尾花和手写数字集两种样本作为输入样例。
- 传入save_path作为输出报告和模型的路径,例如
save_path='./models/'。里面包括了每个模型的输出报告(测试集,验证集都有),每个模型(10个模型加最后的集成模型,对所有数据进行了重新学习),使用joblib保存的,使用的话直接joblib.load就行。还有一个优化报告,即对四种集成学习模型进行优化后的结果。 - 传入target_names作为优化报告里面两种分类的名字,暂时只支持二分类。
tips: 下面会附上代码和两个使用demo,也会贴上github上的链接,如果大家需要什么新的功能可以留言告诉我,最新的更新应该会在github上同步,希望大家星星我,有空的话再更新博客。求个赞不过分吧!转载请一定表明出处哟~
结果展示:
-
输出example
-
输出报告example
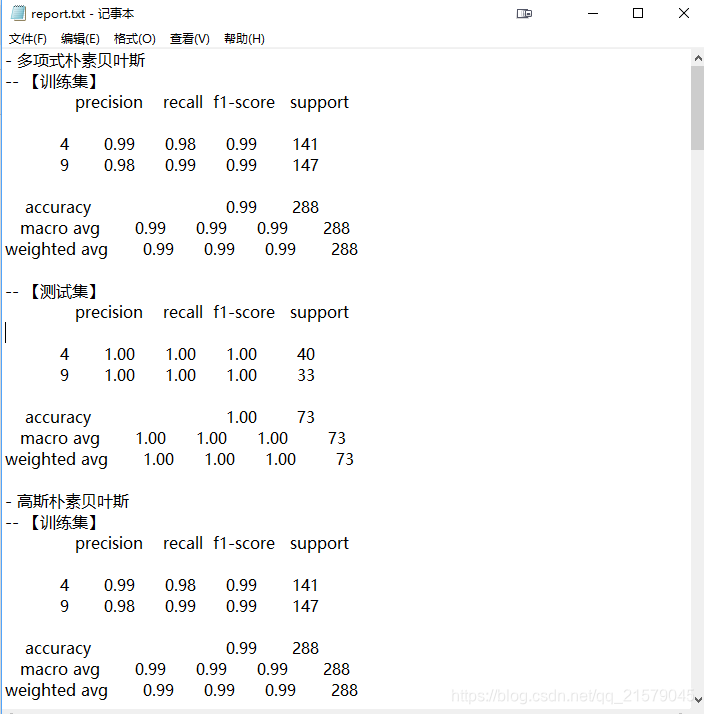
-
优化报告example

-
代码具体实现:
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: ML_combines.py @time: 2019/9/23 8:53 @desc: 机器学习工具集合,直接写一个类,传参训练集,验证集就能生成报告 """ from sklearn.metrics import f1_score from sklearn.model_selection import train_test_split from collections import OrderedDict class MLTools: """ 包含:多项式朴素贝叶斯, 高斯朴素贝叶斯, K最近邻, 逻辑回归, 支持向量机, 决策树, 随机森林, Adaboost, GBDT, xgboost """ random_state = 42 # 粗略 随机森林调参数值 # 参考链接1:https://blog.csdn.net/geduo_feng/article/details/79558572 # 参考链接2:https://blog.csdn.net/qq_35040963/article/details/88832030 parameter_tree = { # 集成模型数量越小越简单 'n_estimators': range(10, 200, 20), # 最大树深度越小越简单 'max_depth': range(1, 10, 1), # 最小样本分割数越大越简单 'min_samples_split': list(range(2, 10, 1))[::-1], } parameter_tree = OrderedDict(parameter_tree) def __init__(self, X_train, y_train, X_test, y_test): self.X_train = X_train self.y_train = y_train self.X_test = X_test self.y_test = y_test # Multinomial Naive Bayes Classifier / 多项式朴素贝叶斯 def multinomial_naive_bayes_classifier(self): from sklearn.naive_bayes import MultinomialNB model = MultinomialNB(alpha=0.01) model.fit(self.X_train, self.y_train) return model, None # Gaussian Naive Bayes Classifier / 高斯朴素贝叶斯 def gaussian_naive_bayes_classifier(self): from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(self.X_train, self.y_train) return model, None # KNN Classifier / K最近邻 def knn_classifier(self): from sklearn.neighbors import KNeighborsClassifier model = KNeighborsClassifier() model.fit(self.X_train, self.y_train) return model, None # Logistic Regression Classifier / 逻辑回归 def logistic_regression_classifier(self): from sklearn.linear_model import LogisticRegression model = LogisticRegression(penalty='l2') model.fit(self.X_train, self.y_train) return model, None # SVM Classifier / 支持向量机 def svm_classifier(self): from sklearn.svm import SVC model = SVC(kernel='rbf', probability=True) model.fit(self.X_train, self.y_train) return model, None # Decision Tree Classifier / 决策树 def decision_tree_classifier(self): from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model.fit(self.X_train, self.y_train) return model, None # Random Forest Classifier / 随机森林 def random_forest_classifier(self, is_adjust=True): from sklearn.ensemble import RandomForestClassifier # 训练普通模型 model = RandomForestClassifier() model.fit(self.X_train, self.y_train) test_pred = model.predict(self.X_test) min_score = f1_score(self.y_test, test_pred, average='macro') if not is_adjust: return model, None max_score = 0 best_param = [None, None, None] for p1 in MLTools.parameter_tree['n_estimators']: for p2 in MLTools.parameter_tree['max_depth']: for p3 in MLTools.parameter_tree['min_samples_split']: test_model = RandomForestClassifier(random_state=MLTools.random_state, n_estimators=p1, max_depth=p2, min_samples_split=p3, n_jobs=-1) test_model.fit(self.X_train, self.y_train) test_pred = test_model.predict(self.X_test) new_score = f1_score(self.y_test, test_pred, average='macro') # 输出检查每一个细节,可能存在不同的参数得到相同的精度值 # print('n_estimators=' + str(p1) + 'max_depth=' + str(p2) + 'min_samples_split=' + str(p3) + '-->' + str(new_score)) if new_score > max_score: max_score = new_score best_param = [p1, p2, p3] best_model = RandomForestClassifier(random_state=MLTools.random_state, n_estimators=best_param[0], max_depth=best_param[1], min_samples_split=best_param[2], n_jobs=-1) best_model.fit(self.X_train, self.y_train) word = '-- optimized parameters: ' count = 0 for name in MLTools.parameter_tree.keys(): word = word + name + ' = ' + str(best_param[count]) + ' ' count += 1 word = word + 'f1_macro: ' + '%.4f' % min_score + '-->' + '%.4f' % max_score + " " return best_model, word # AdaBoost Classifier / 自适应提升法 def adaboost_classifier(self, is_adjust=True): from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier model = AdaBoostClassifier() model.fit(self.X_train, self.y_train) test_pred = model.predict(self.X_test) min_score = f1_score(self.y_test, test_pred, average='macro') if not is_adjust: return model, None max_score = 0 best_param = [None, None, None] for p1 in MLTools.parameter_tree['n_estimators']: for p2 in MLTools.parameter_tree['max_depth']: for p3 in MLTools.parameter_tree['min_samples_split']: test_model = AdaBoostClassifier( DecisionTreeClassifier(random_state=MLTools.random_state, max_depth=p2, min_samples_split=p3), random_state=MLTools.random_state, n_estimators=p1) test_model.fit(self.X_train, self.y_train) test_pred = test_model.predict(self.X_test) new_score = f1_score(self.y_test, test_pred, average='macro') if new_score > max_score: max_score = new_score best_param = [p1, p2, p3] best_model = AdaBoostClassifier( DecisionTreeClassifier(random_state=MLTools.random_state, max_depth=best_param[1], min_samples_split=best_param[2]), random_state=MLTools.random_state, n_estimators=best_param[0]) best_model.fit(self.X_train, self.y_train) word = '-- optimized parameters: ' count = 0 for name in MLTools.parameter_tree.keys(): word = word + name + ' = ' + str(best_param[count]) + ' ' count += 1 word = word + 'f1_macro: ' + '%.4f' % min_score + '-->' + '%.4f' % max_score + " " return best_model, word # GBDT(Gradient Boosting Decision Tree) Classifier / 梯度提升决策树 def gradient_boosting_classifier(self, is_adjust=True): from sklearn.ensemble import GradientBoostingClassifier model = GradientBoostingClassifier() model.fit(self.X_train, self.y_train) test_pred = model.predict(self.X_test) min_score = f1_score(self.y_test, test_pred, average='macro') if not is_adjust: return model, None max_score = 0 best_param = [None, None, None] for p1 in MLTools.parameter_tree['n_estimators']: for p2 in MLTools.parameter_tree['max_depth']: for p3 in MLTools.parameter_tree['min_samples_split']: test_model = GradientBoostingClassifier(random_state=MLTools.random_state, n_estimators=p1, max_depth=p2, min_samples_split=p3) test_model.fit(self.X_train, self.y_train) test_pred = test_model.predict(self.X_test) new_score = f1_score(self.y_test, test_pred, average='macro') if new_score > max_score: max_score = new_score best_param = [p1, p2, p3] best_model = GradientBoostingClassifier(random_state=MLTools.random_state, n_estimators=best_param[0], max_depth=best_param[1], min_samples_split=best_param[2]) best_model.fit(self.X_train, self.y_train) word = '-- optimized parameters: ' count = 0 for name in MLTools.parameter_tree.keys(): word = word + name + ' = ' + str(best_param[count]) + ' ' count += 1 word = word + 'f1_macro: ' + '%.4f' % min_score + '-->' + '%.4f' % max_score + " " return best_model, word # xgboost / 极端梯度提升 def xgboost_classifier(self, is_adjust=True): from xgboost import XGBClassifier model = XGBClassifier() model.fit(self.X_train, self.y_train) test_pred = model.predict(self.X_test) min_score = f1_score(self.y_test, test_pred, average='macro') if not is_adjust: return model, None max_score = 0 best_param = [0, 0, 0] for p1 in MLTools.parameter_tree['n_estimators']: for p2 in MLTools.parameter_tree['max_depth']: for p3 in MLTools.parameter_tree['min_samples_split']: test_model = XGBClassifier(random_state=MLTools.random_state, n_estimators=p1, max_depth=p2, min_samples_split=p3, n_jobs=-1) test_model.fit(self.X_train, self.y_train) test_pred = test_model.predict(self.X_test) new_score = f1_score(self.y_test, test_pred, average='macro') if new_score > max_score: max_score = new_score best_param = [p1, p2, p3] best_model = XGBClassifier(random_state=MLTools.random_state, n_estimators=best_param[0], max_depth=best_param[1], min_samples_split=best_param[2], n_jobs=-1) best_model.fit(self.X_train, self.y_train) word = '-- optimized parameters: ' count = 0 for name in MLTools.parameter_tree.keys(): word = word + name + ' = ' + str(best_param[count]) + ' ' count += 1 word = word + 'f1_macro: ' + '%.4f' % min_score + '-->' + '%.4f' % max_score + " " return best_model, word def model_building(X_train, y_train, X_test, y_test, save_path, target_names=None, just_emsemble=False): """ 训练模型,并得到结果,并重新训练所有数据,保存模型 :param save_path: 模型的保存路径 :param target_names: 样本标签名 :param just_emsemble: 已经有了其他模型,只对模型进行集成 """ from sklearn.metrics import classification_report import joblib import os import numpy as np if not just_emsemble: tool = MLTools(X_train, y_train, X_test, y_test) models = [tool.multinomial_naive_bayes_classifier(), tool.gaussian_naive_bayes_classifier(), tool.knn_classifier(), tool.logistic_regression_classifier(), tool.svm_classifier(), tool.decision_tree_classifier(), tool.random_forest_classifier(), tool.adaboost_classifier(), tool.gradient_boosting_classifier(), tool.xgboost_classifier()] model_names = ['多项式朴素贝叶斯', '高斯朴素贝叶斯', 'K最近邻', '逻辑回归', '支持向量机', '决策树', '随机森林', 'Adaboost', 'GBDT', 'xgboost'] # 遍历每个模型 f = open(save_path + 'report.txt', 'w+') g = open(save_path + 'optimized.txt', 'w+') for count in range(len(models)): model, optimized = models[count] model_name = model_names[count] print(str(count + 1) + '. 正在运行:', model_name, '...') train_pred = model.predict(X_train) test_pred = model.predict(X_test) train = classification_report(y_train, train_pred, target_names=target_names) test = classification_report(y_test, test_pred, target_names=target_names) f.write('- ' + model_name + ' ') f.write('-- 【训练集】' + ' ') f.writelines(train) f.write(' ') f.write('-- 【测试集】' + ' ') f.writelines(test) f.write(' ') g.write('- ' + model_name + ' ') if optimized: g.write(optimized) g.write(' ') model.fit(np.r_[np.array(X_train), np.array(X_test)], np.r_[np.array(y_train), np.array(y_test)]) joblib.dump(model, os.path.join(save_path, model_name + '.plk')) f.close() g.close() # 开始集成模型 from sklearn.ensemble import VotingClassifier f = open(save_path + 'report.txt', 'a+') emsemble_names = ['随机森林', 'Adaboost', 'GBDT', 'xgboost'] emsemble_path = [os.path.join(save_path, i + '.plk') for i in emsemble_names] estimators = [] for x, y in zip(emsemble_names, emsemble_path): estimators.append((x, joblib.load(y))) voting_clf = VotingClassifier(estimators, voting='soft', n_jobs=-1) voting_clf.fit(X_train, y_train) print('11. 正在运行:集成模型...') train_pred = voting_clf.predict(X_train) test_pred = voting_clf.predict(X_test) train = classification_report(y_train, train_pred, target_names=target_names) test = classification_report(y_test, test_pred, target_names=target_names) f.write('- ' + '集成模型' + ' ') f.write('-- 【训练集】' + ' ') f.writelines(train) f.write(' ') f.write('-- 【测试集】' + ' ') f.writelines(test) f.write(' ') voting_clf.fit(np.r_[np.array(X_train), np.array(X_test)], np.r_[np.array(y_train), np.array(y_test)]) joblib.dump(voting_clf, os.path.join(save_path, '集成模型' + '.plk')) f.close() def example1(): """鸢尾花数据集进行测试""" from sklearn.datasets import load_iris iris = load_iris() iris_data = iris['data'] iris_target = iris['target'] iris_names = iris['target_names'] X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.2, random_state=42) model_building(X_train, y_train, X_test, y_test, save_path='./models/', target_names=iris_names) def example2(): """手写数据集进行测试""" from sklearn.datasets import load_digits import numpy as np digits = load_digits() digits_data = digits['images'] digits_target = digits['target'] digits_names = digits['target_names'] shape = digits_data.shape X = np.array(digits_data).reshape(shape[0], shape[1] * shape[2]) a, b = 4, 9 index1 = digits_target == a index2 = digits_target == b X = np.r_[X[index1], X[index2]] y = np.r_[digits_target[index1], digits_target[index2]] names = [str(a), str(b)] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) model_building(X_train, y_train, X_test, y_test, save_path='./models2/', target_names=names) if __name__ == '__main__': example1()
我的CSDN:https://blog.csdn.net/qq_21579045
我的博客园:https://www.cnblogs.com/lyjun/
我的Github:https://github.com/TinyHandsome
纸上得来终觉浅,绝知此事要躬行~
欢迎大家过来OB~
by 李英俊小朋友