引自:https://zhuanlan.zhihu.com/p/26332365
任务
这里的任务是图像到图像的翻译。如果大家看过去年一篇cvpr的论文,叫pix2pix的话,对这个任务就比较熟悉。就算你们不知道pix2pix,之前有一个很火的,可以把线条画变成猫的网页应用,就是用的pix2pix的算法。然而pix2pix的模型是在成对的数据上训练的,也就是说,对于线条到猫的应用,我们训练的时候就需要提供一对一对的数据:一个线条画,和对应的真实的猫图片。
然而在很多情况下,我们并没有这样完美的成对的训练数据。比如说如果你想把马变成斑马,并没有这样对应的一个马对应一个斑马。然而,马的图片和斑马的图片却很多。所以这篇论文就是希望,能够通过不成对的训练数据,来学到变换。
但是去年有一篇论文叫dual learning,做的是机器翻译。如果你考虑在语言之间的翻译的话,这个任务可能比图片翻译到图片更有意义。在机器翻译中,成对的翻译数据非常有限,但是单一语言的预料非常的多。这篇paper就是讨论如何用独自的语料来帮助翻译。事实上,dualgan这篇paper的出发点就来源于此,并且这三篇文章的中心创新点(cycle consistentcy)就是dual learning中的想法。(虽然cyclegan似乎不知道这篇论文,并没有引用dual learning)
CycleGAN的出发点更抽象。他们introduction第一段就开始讨论莫奈;他们的意思是,给一副莫奈的画,人能够想象出莫奈画的景色原来应该是什么样子,所以一个牛逼的AI应该也能做这件事。
模型(三篇文章一毛一样):
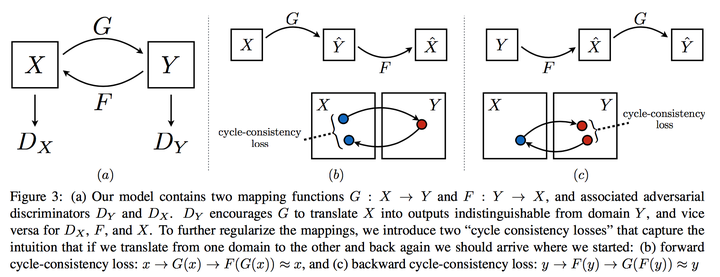
一个普通的GAN只有一个生成器和一个判别起。而在这篇文章里,分别有两个生成器和判别器。一个生成器将X域的图片转换成Y域的图片(用G表示),而另一个生成器做相反的事情,用F表示。而两个判别器和
试图分辨两个域中真假图片。(这里假图片指的是从真照片transform来的)
Cycle consistency (这个名字是来自cyclegan,另外两篇都有不同的叫法,但是本质上是一个东西) 是为了使得这个transform能成功。讲道理,如果你能从X转换到Y,然后再从Y转换到X,最后的结果应该和输入相似。这里他们用最后输出和输入的L1距离来作为另外的惩罚项。
数学形式就是和
需要足够小。
这个惩罚项防止了mode collapse的问题。如果没有这个cycle consistency项,网络会输出更真实的图片,但是无论什么输入,都会是一样的输出。而如果加了cycle consistency,一样的输出会导致cycle consistency的直接失败。所以这规定了在经过了变换之后的图片不仅需要真实,且包含原本图片的信息。
下图为图示。
网络细节:
CycleGAN:
这里的generator跟 Perceptual losses for real-time style transfer and super-resolution是一样的。他们使用了Instance Normalization。判别器使用的和pix2pix一样(PatchGAN on 70x70 patches). 为了稳定GAN的训练,他们使用了最小二乘gan(least square gan)和 Replay buffer。不像pix2pix,他们的模型没有任何的随机性。(没有随机输入z,没有dropout)这里的生成器更像是一个deteministic的style transfer模型,而不是一个条件GAN。他们使用了L1距离作为cycle consistency.
DualGAN:
他们的生成器和判别器都和pix2pix一样 (没有随机输入z,但是有dropout的随机)。 他们用了wgan来训练。cycle consistency同样选用了l1。
DiscoGAN:
他们用了conv,deconv和leaky relu组成了生成器,然后一个conv+leaky relu作为判别器。他们用l2作为cycle consistency。
实验
CycleGAN:
一个主要的实验是,在cityscapes数据集中,从图片和其语义分割的双向翻译。他们的用的评估方法和pix2pix中完全相同。CycleGAN和CoGAN, BiGAN, pix2pix(算作上界)进行了比较。其中,CoGAN这个模型在设计之初也是为了同样的任务:idea是通过两个共享weight的生成器来从相同的z生成两个域的图片,这个两个图片都需要通过各自域的判别器的检测。 BiGAN原本是为了能够找到G的逆函数E的(输入图片输出z)。这里如果你把z当作一个image,那bigan就可以用来做这个任务。
结果证明CycleGAN比所有baseline都要优秀。当然跟pix2pix还是有所差距,但是毕竟pix2pix是完全监督的方法。
他们又研究了cyclegan每个成分起到的作用:只有adversarial loss没有cycle consistency;只有cycle consistency没有adversairial loss;只有一个方向的cycle consistency。结果如下图(一句话,每个部分都很重要)。

后面他们还试了很有趣的一些应用,那些应用没有进行评估,因为没有ground truth来进行评估。这些应用包括边缘<->鞋,马<->斑马,橙子<->苹果,冬景<->夏景,艺术画<->照片。结果都很酷炫。
DualGAN:
他们做了PHOTO-SKETCH, DAY-NIGHT, LABEL-FACADES和AERIAL-MAPS的实验。在某些实验中,他们甚至得到了比pix2pix更高的realness 分数(采集自amt)。在我看来,这说明realness是一个很差的评价方式,因为本质上只要你输出足够真实的图片就可以,而不需要跟输入的图片有关。
DiscoGAN:
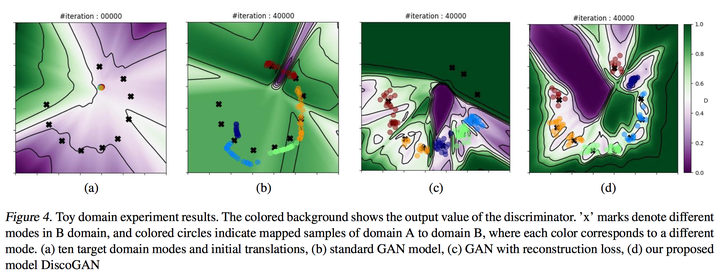
我很喜欢这篇文章中的toy experiment。他们人工生成了两个域的GMM数据点,然后根据这个人造数据学习了一个DiscoGAN。另外两个baseline,一个是最简单的GAN,另一个是GAN with forward consistency(也就是一边的consistency)。这两个baseline都会有mode collapse的问题。
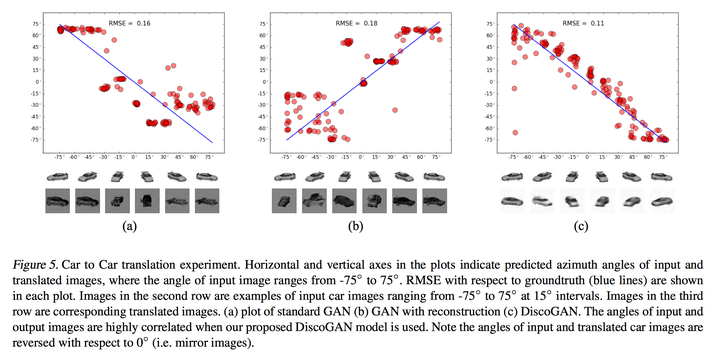
他们也有一个car到car的toy experiment。每个domain都有不同角度的3d车的图片,每15度有一些。然后你可以在这两个domain上学习discogan,可以得到角度的对应。 跟baseline相比,discogan能获得更correlated的角度关系。
他们也试了FACE to FACE,FACE CONVERSION(性别,发色等r etc.), CHAIR TO CAR, CAR TO FACE, EDGES TO PHOTOS, HANDBAG TO SHOES, SHOES TO HANDBAG。这些实验都是qualitative的实验,而且也并不怎么酷。
讨论
有趣的现象:wrong mapping。因为这是完全unsupervised,所以有时候模型会找到错误的mapping。比如说在cyclegan里,photos to labels的,building经常会被标注成树。在discoGAN图5(最后一列)里也可以看到,学到的变化是flipping(而不是exactly相同角度对应)。
此外,像狗变猫,猫变狗这样的任务也很难,因为这涉及到几何变换。我其实很怀疑这个任务是否有意义:因为这个任务很难有一个标准,就算让人将狗变成猫,这都是一件很困难的事。就算你能保留原来的pose,但是比如说品种之间如何变换,很难定义。
另外一件没有在本文中讨论的是,我觉得挺有意思的是:现在的cycle是一圈,如果我们考虑两圈,或者一圈半之类的,会有什么结果呢。