第一章 搜索引擎及其技术架构
1.搜索引擎为何重要
略
2. 搜索引擎技术发展历史
- 分类目录时代,代表网站为 yahoo,hao123
- 文本检索的一代,匹配用户的输入query 与网页内容,然后按照匹配程度进行计算排序
- 链接分析的一代,文本检索没有考虑用户意图以及网页本身的质量,可能会返回排名靠前的低质量的欺诈网页给用户,链接分析可以考虑网页的入链和出链,相当于是一种推荐机制,可以有效筛选出相关且高质量的网页给用户,典型的代表为google的pagerank
- 用户中心的一代,考虑了不同用户本身查询相同query可能会有差异,同一个用户在不同的时间、地点查询相同的query可能也会有差异,也需要考虑用户的查询意图,总之围绕尽可能真正理解用户的查询需求而改进搜索引擎。
3.搜索引擎的三个目标:更快、更全、更准
4.搜索引擎的三个核心问题:
- 用户真正的需求是什么
- 哪些信息是和用户的需求真正相关的
- 哪些信息时用户可以依赖的
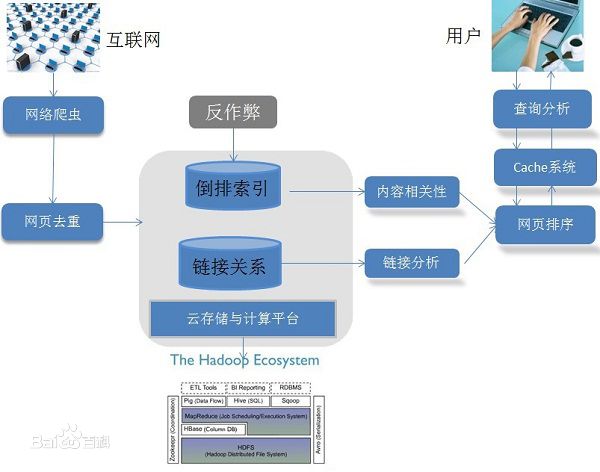
5.搜索引擎的技术架构图
第二章 网络爬虫
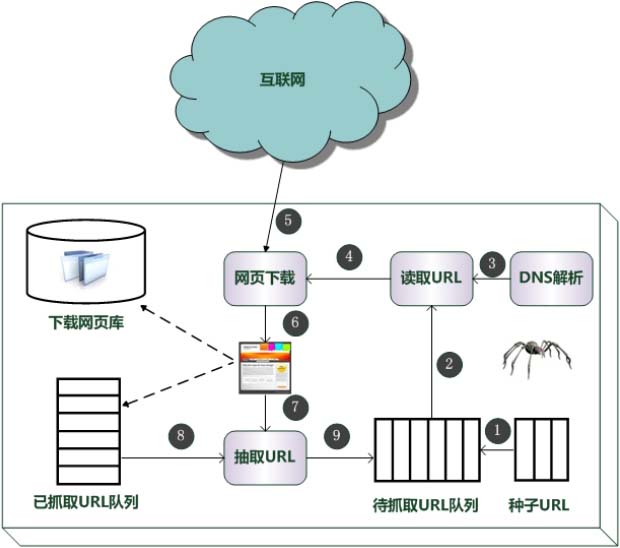
1.通用爬虫框架
2.优秀爬虫的特性
- 高性能
多进程、多线程爬虫,优化待抓取、已抓取URL队列
- 可扩展性
分布式爬虫、增加并发性
- 健壮性
能够处理各种异常情况、能够异常恢复
- 友好性
遵循爬虫协议、robots.txt,不给待抓取网站服务器造成很大的负担
3.爬虫质量的评价标准
抓取网页覆盖率、抓取网页时新性、抓取网页重要性
4.爬虫抓取策略
宽度优先遍历策略
非完全pagerank策略
OPIC(online page importance computation,在线页面重要性计算)
大站优先策略
5.网页更新策略
历史参考策略:参考网页的历史更新频率,以泊松分布建模
用户体验策略:按照网页对于用户体验的影响来决定何时更新网页
聚类抽样策略:将不同的网页进行聚类,同一个类别的网页更新方式相同,每个类别进行抽样计算类别的平均更新频率
6.暗网抓取
非web,非结构化的数据抓取
- 组合查询问题
google 富含信息查询模板
- 文本框填写问题
给定种子查询关键词列表,然后从返回的数据中提取出更多的关键词,然后迭代查询
7. 分布式爬虫
分布式数据中心、分布式抓取服务器、分布式爬虫程序
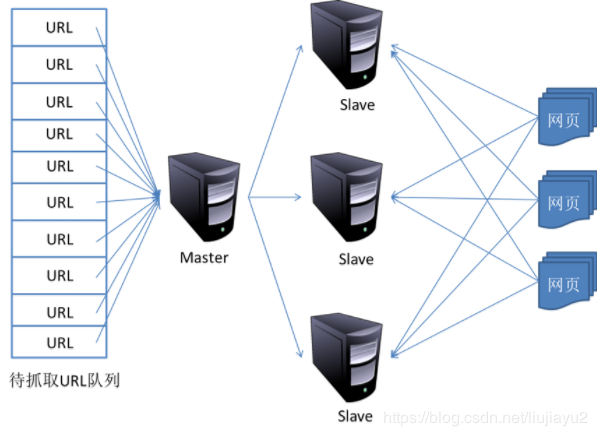
- 主从分布式爬虫
- 对等分布式爬虫
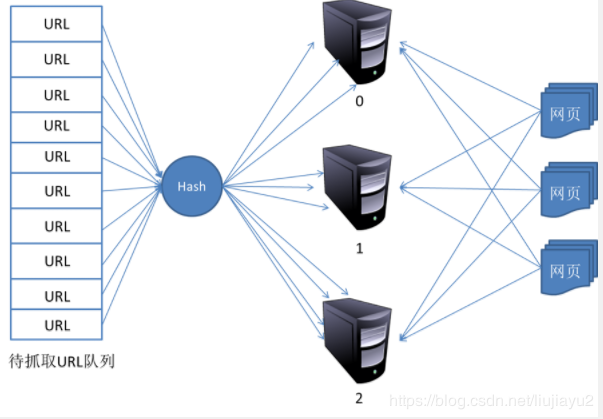
对主域名进行hash计算,然后对应分配到不同的服务器进行抓取
改进:采用一致性hash算法,将不同的服务器组成一个环,将主域名映射到[0,2^32]的某个数值,实现了可以方便进行服务器的扩展,以及某台服务器宕机了可以直接将url分发到其后的服务器,大大增强了可扩展性。