背景:
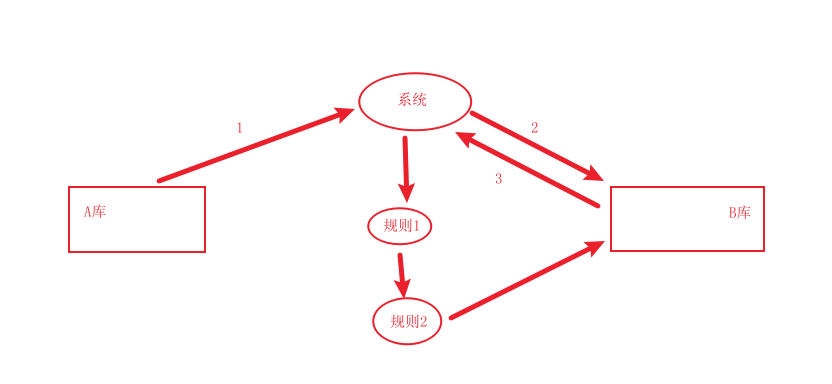
程序总体设计:
系统先从数据库 A 表中取出数据(步骤 1),放入 B 库中的表里(步骤 2);
在从 B库中的表里取出数据(步骤 3),经过层层的规则校验,再放回 B 库中的表中;
速度优化原因:
原本:方法使用单线程的方式;校验产品是否自动化通过远程调用的方式;每次批处理调价数据是50条;数据极慢;
如:202109273版本,开始时间是:2021-09-27 18:21:04,处理完是:2021-09-27 18:38:33;数据量是:477853;用时:17分钟
如:202109173版本,开始时间是:2021-09-17 15:41:54,处理完是:2021-09-17 16:36:07;数据量是:914366;用时:55分钟
如:202109161版本,开始时间是:2021-09-16 10:02:59,处理完是:2021-09-16 10:15:44;数据量是:411208;用时:12分钟
如:202109151版本,开始时间是:2021-09-15 11:24:25,处理完是:2021-09-15 11:37:55;数据量是:413146;用时:13分钟
40万条数据需要12—13分钟,90万数据需要55分钟,太慢了.....
优化目标:
100万数据量希望将规则校验时间压缩在10分钟以内;
优化方向一:
每次批处理调价数据量增加到1000条;
“校验产品是否自动化”由远程调用接口,改为直接查询数据库;(远程接口调用会在网络上限制系统的性能)
规则校验采用多线程处理,对老代码适配多线程;
成果:
收效甚微!!!!,由此可见,速度慢的问题不知规则过滤导致的;
优化方向二:
排查慢的原因,发现是 步骤 1和步骤 3 很慢,发现每次查询都是 1 秒以上,时间占据了总时间的 70%,sql:
select id, ....., del_flag from ol_autopricing_auto_pricing_bi_data where data_version = #{dataVersion} and del_flag = 0 order by id limit #{start},#{range}
结论就是:limit 在大数据了下分页很慢,淦,中招了
优化步骤 1:
换掉步骤一的 sql :
业务上条件:数据都是连续的,不会出现数据分布杂乱的情况
方案:不在使用 limit 分页,而使用主键id分页
查询出主键分页的起始和结束位置:
select min(id) as minId, max(id) as maxId from ol_autopricing_auto_pricing_bi_data where data_version = #{dataVersion} and del_flag = 0
根据起始和结束位置对主键进行分页:
起始位置:start=manId,range=1000
循环查找时通过程序控制 (start+range) <= maxId ,限制 id 不会越界;
select id, ....., del_flag from ol_autopricing_auto_pricing_bi_data where id between #{start} and #{end}and data_version = #{dataVersion} and del_flag = 0 order by id
之后发现数据很快,快到飞起,查询速度都是在 10 毫秒以内
优化步骤 2 :
插入的方案一般有两种方案:
- 用一个 for 循环,把数据一条一条的插入(这种需要开启批处理)。
- 生成一条插入 sql,类似这种
insert into user(username,address) values('aa','bb'),('cc','dd')...。
先说第一种方案,就是用 for 循环循环插入:
- 这种方案的优势在于,JDBC 中的 PreparedStatement 有预编译功能,预编译之后会缓存起来,后面的 SQL 执行会比较快并且 JDBC 可以开启批处理,这个批处理执行非常给力。
- 劣势在于,很多时候我们的 SQL 服务器和应用服务器可能并不是同一台,所以必须要考虑网络 IO,如果网络 IO 比较费时间的话,那么可能会拖慢 SQL 执行的速度。
- 虽然是一条一条的插入,但是我们要开启批处理模式(BATCH),这样前前后后就只用这一个 SqlSession,如果不采用批处理模式,反反复复的获取 Connection 以及释放 Connection 会耗费大量时间,效率奇低,
再来说第二种方案,就是生成一条 SQL 插入:
- 这种方案的优势在于只有一次网络 IO,即使分片处理也只是数次网络 IO,所以这种方案不会在网络 IO 上花费太多时间。
- 当然这种方案有好几个劣势,一是 SQL 太长了,甚至可能需要分片后批量处理;二是无法充分发挥 PreparedStatement 预编译的优势,SQL 要重新解析且无法复用;三是最终生成的 SQL 太长了,数据库管理器解析这么长的 SQL 也需要时间。
- 当数据量大的时候,生成的 SQL 将特别的长,MySQL 可能一次性处理不了这么大的 SQL,这个时候就需要修改 MySQL 的配置或者对待插入的数据进行分片处理了,这些操作又会导致插入时间更长。
使用第一种方式:
打开了数据库配置mysql 的数据库配置 rewriteBatchedStatements=true,那么就可以选择使用批量插入,一次提交的方案:
/** * 批量保存的方法 获取一个 session ,通过一个 Session 提交保存 * @param entityDates */ public void addEntityOneByOne(List<AutoPricingAffairItemEntity> entityDates) { SqlSession sqlSession = pcsSqlSessionFactory.openSession(ExecutorType.BATCH); PcsDatasourceMapper mapper = sqlSession.getMapper(PcsDatasourceMapper.class); for (AutoPricingAffairItemEntity entity : entityDates) { mapper.insertBatchBiData(entity); } // 如果不关闭,11 次之后就会获取不到链接 sqlSession.commit(); //记得提交 sqlSession.close(); //记得关闭 }
优化步骤 3:
也是查询,该表更大,但是由于该表是业务表,数据可能比较乱,主键分页不太实用,所以使用join的方式:
select bbb.id, .... bbb.del_flag from (select id from pcs.ol_autopricing_auto_pricing_bi_data <where> del_flag = 0 <if test="null != dataVersion and '' != dataVersion"> and data_version = #{dataVersion} </if> </where> order by id <if test="start != null and range != null and range > 0"> limit #{start},#{range} </if> ) aaa inner join pcs.ol_autopricing_auto_pricing_bi_data bbb on aaa.id = bbb.id
先通过子查询,查询出主键,在通过结果集形成临时表,用小表驱动大表的方式,通过主键 join 出我们的全部字段,实测50 万数据,只需要 120 毫秒,能接受了
通过这两个的优化速度已经提升了近 85% 了, 剩余的优化都是开多线程提升了,确实没什么优化的空间了;
心得:
后来也进行了综合对比,发现切换多线程和不切换多线程的时间提升不明显,性能慢的主要原因还是出现在查询数据库上;
很少说程序写的差导致总体时间过长的问题;
后续排查性能慢的首选还是得先排查慢的 sql ;
分页查询的方式有很多,具体使用哪一种,还得看具体的业务场景,有的性能可能更高,但是并不适用;例如:优化步骤 3 时,步骤一优化方案也可以用,但是会查出很多别的数据,还要系统做判断,既增加了 io,又增加了程序的复杂度,得不偿失;