1.XPath语法
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
节点关系
(1)父(Parent)
每个元素以及属性都有一个父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
<book>
<title>family</title>
<year>2007</year>
<price>78</price>
</book>
(2)子(Children)
元素节点可有零个、一个或多个子。
在上面的例子中,title、author、year 以及 price 元素都是 book 元素的子
(3)同胞(Sibling)
拥有相同的父的节点
在上面的例子中,title、author、year 以及 price 元素都是同胞
(4)先辈(Ancestor)
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素
<bookstore>
<book>
<title>family</title>
<year>2007</year>
<price>78</price>
</book>
</bookstore>
(5)后代(Descendant)
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
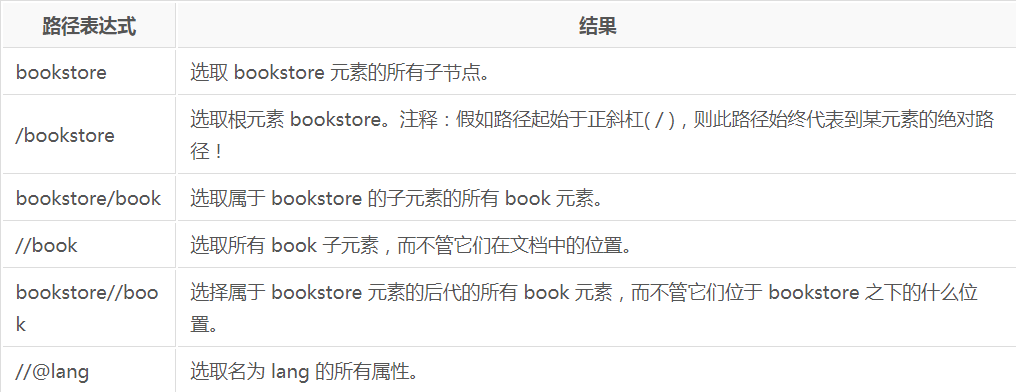
下面列出了最有用的路径表达式:

实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:

选取未知节点
XPath 通配符可用来选取未知的 XML 元素。

实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

XPath 运算符
下面列出了可用在 XPath 表达式中的运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| – | 减法 | 6 – 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |
2.lxml用法
初步使用
首先我们利用它来解析 HTML 代码,先来一个小例子来感受一下它的基本用法。
from lxml import etree text=''' <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </ul> </div> ''' html = etree.HTML(text) result = etree.tostring(html) print result
首先使用 lxml 的 etree 库,然后利用 etree.HTML 初始化,然后我们将其打印出来。
其中,这里体现了 lxml 的一个非常实用的功能就是自动修正 html 代码,应该注意到了,最后一个 li 标签,其实把尾标签删掉了,是不闭合的。不过,lxml 因为继承了 libxml2 的特性,具有自动修正 HTML 代码的功能。
所以输出结果是这样的
<html><body><div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </li></ul> </div> </body></html>
不仅补全了 li 标签,还添加了 body,html 标签。
文件读取
除了直接读取字符串,还支持从文件读取内容。比如我们新建一个文件叫做 hello.html,内容为上面的text
html = etree.parse('hello.html') result = etree.tostring(html) print result
利用 parse 方法来读取文件,同样可以得到相同的结果。
XPath实例测试
依然以上一段程序为例
(1)获取所有的 <li> 标签
html = etree.parse('hello.html') print type(html) result = html.xpath('//li') print result print len(result) print type(result) print type(result[0])
运行结果
<type 'lxml.etree._ElementTree'> [<Element li at 0x312d558>, <Element li at 0x312d530>, <Element li at 0x312d508>, <Element li at 0x312d2b0>, <Element li at 0x312d0d0>] 5 <type 'list'> <type 'lxml.etree._Element'>
可见,etree.parse 的类型是 ElementTree,通过调用 xpath 以后,得到了一个列表,包含了 5 个 <li> 元素,每个元素都是 Element 类型
(2)获取 <li> 标签的所有 class
html = etree.parse('hello.html') print type(html) result = html.xpath('//li/@class') print result
运行结果
<type 'lxml.etree._ElementTree'> ['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
(3)获取 <li> 标签下 href 为 link1.html 的 <a> 标签
html = etree.parse('hello.html') result = html.xpath('//li/a[@href="link1.html"]') print result
(4)获取 <li> 标签下的所有 <span> 标签
/ 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
result = html.xpath('//li//span')
(5)获取 <li> 标签下的所有 class,不包括 <li>
result = html.xpath('//li/a//@class')
(6)获取最后一个 <li> 的 <a> 的 href
result = html.xpath('//li[last()]/a/@href') #['link5.html']
(7)获取倒数第二个元素的内容
result = html.xpath('//li[last()-1]/a')
(8)获取 class 为 item-1 的标签名
result = html.xpath('//*[@class="item-1"]') print result[0].tag