原文地址:https://zhuanlan.zhihu.com/p/27216346
本文要介绍的这一篇paper是ICML2016上一篇关于 CNN 在图(graph)上的应用。ICML 是机器学习方面的顶级会议,这篇文章--<< Learning CNNs for Graphs>>--所研究的内容也具有非常好的理论和实用的价值。如果您对于图的数据结构并不是很熟悉建议您先参考本文末的相关基础知识的介绍。
CNN已经在计算机视觉(CV)以及自然语言处理等领域取得了state-of-art 的水平,其中的数据可以被称作是一种Euclidean Data,CNN正好能够高效的处理这种数据结构,探索出其中所存在的特征表示。
图1 欧氏(欧几里德)数据(Euclidean Data)举例
所谓的欧氏(欧几里德)数据指的是类似于grids, sequences… 这样的数据,例如图像就可以看作是2D的grid数据,语音信号就可以看作是1D的grid数据。但是现实的处理问题当中还存在大量的 Non-Euclidean Data,如社交多媒体网络(Social Network)数据,化学成分(Chemical Compound)结构数据,生物基因蛋白(Protein)数据以及知识图谱(Knowledge Graphs)数据等等,这类的数据属于图结构的数据(Graph-structured Data)。CNN等神经网络结构则并不能有效的处理这样的数据。因此,这篇paper要解决的问题就是如何使用CNN高效的处理图结构的数据。
图2 Graph 数据举例
本文所提出算法思想很简单,将一个图结构的数据转化为CNN能够高效处理的结构。处理的过程主要分为两个步骤:1.从图结构当中选出具有代表性的nodes序列;2.对于选出的每一个node求出一个卷积的邻域(neighborhood field)。接下来我们详细的介绍算法相关的细节。
本paper将图像(image)看作是一种特殊的图(graph),即一种的grid graph,每一个像素就是graph当中的一个node。那么我猜想文章的motivation主要来自于想将CNN在图像上的应用generalize 到一般的graph上面。
那么我们首先来看一下CNN在Image当中的应用。如图3所示,左图表示的是一张图像在一个神经网络层当中的卷机操作过程。最底部的那一层是输入的特征图(或原图),通过一个卷积(这里表示的是一个3*3的卷积核,也就是文章当中的receptive filed=9)操作,输出一张卷积后的特征图。如图3 的卷积操作,底层的9个像素被加权映射到上层的一个像素;再看图3中的右图,表示从graph的角度来看左图底层的输入数据。其中任意一个带卷积的区域都可以看作是一个中心点的node以及它的领域的nodes集合,最终加权映射为一个值。因此,底部的输入特征图可以看作是:在一个方形的grid 图当中确定一些列的nodes来表示这个图像并且构建一个正则化的邻域图(而这个邻域图就是卷积核的区域,也就是感知野)。
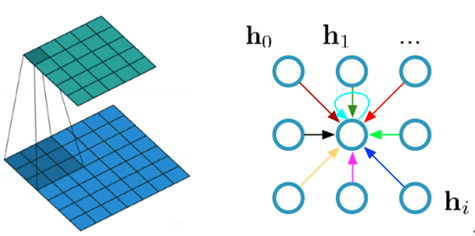
图3 图像的卷积操作
按照这样的方式来解释,那么如paper中Figure1所示,一张4*4大小的图像,实际上可以表示为一个具有4个nodes(图中的1,2,3,4)的图(graph),其中每一个node还包括一个和卷积核一样大小的邻域(neighborhood filed)。那么,由此得到对于这种图像(image)的卷积实际上就是对于这4个node组成的图(graph)的领域的卷积。那么,对于一个一般性的graph数据,同样的只需要选出其中的nodes,并且求解得到其相关的固定大小(和卷积核一样大小)领域便可以使用CNN卷积得到图的特征表示。
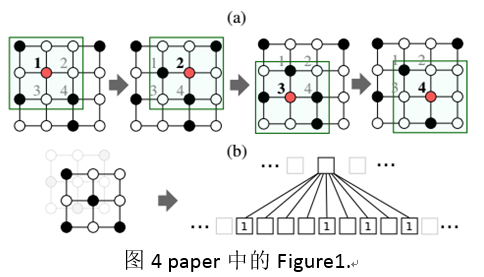
图4 paper中的Figure1.
需要注意的是,图4(b)当中表示的是(a)当中的一个node的邻域,这个感知野按照空间位置从左到右,从上到下的顺序映射为一个和卷积核一样大小的vector,然后再进行卷积。但是在一般的图集当中,不存在图像当中空间位置信息。这也是处理图数据过程当中要解决的一个问题。
基于以上的描述paper当中主要做了三个事情:1. 选出合适的nodes;2. 为每一个node建立一个邻域;3. 建立graph表示到 vector表示的单一映射,保证具有相似的结构特征的node可以被映射到vector当中相近的位置。算法具体分为4个步骤:
1. 图当中顶点的选择Node Sequence Selection
首先对于输入的一个Graph,需要确定一个宽度w(定义于Algorithm 1),它表示也就是要选择的nodes的个数。其实也就是感知野的个数(其实这里也就是表明,每次卷积一个node的感知野,卷积的stride= kernel size的)。那么具体如何进行nodes的选择勒?
实际上,paper当中说根据graph当中的node的排序label进行选择,但是本文并没有对如何排序有更多的介绍。主要采取的方法是:centrality,也就是中心化的方法,个人的理解为越处于中心位置的点越重要。这里的中心位置不是空间上的概念,应该是度量一个点的关系中的重要性的概念,简单的举例说明。如图5当中的两个图实际上表示的是同一个图,对其中红色标明的两个不同的nodes我们来比较他们的中心位置关系。比较的过程当中,我们计算该node和其余所有nodes的距离关系。我们假设相邻的两个node之间的距离都是1。

图5 图当中的两个nodes
那么对于图5当中的左图的红色node,和它直接相连的node有4个,因此距离+4;再稍微远一点的也就是和它相邻点相邻的有3个,距离+6;依次再相邻的有3个+9;最后还剩下一个最远的+4;因此我们知道该node的总的距离为23。同理我们得到右边的node的距离为3+8+6+8=25。那么很明显node的选择的时候左边的node会被先选出来。
当然,这只是一种node的排序和选择的方法,其存在的问题也是非常明显的。Paper并没有在这次的工作当中做详细的说明。
2. 找到Node的领域Neighborhood Assembly
接下来对选出来的每一个node确定一个感知野receptive filed以便进行卷积操作。但是,在这之前,首先找到每一个node的邻域区域(neighborhood filed),然后再从当中确定感知野当中的nodes。假设感知野的大小为k,那么对于每一个Node很明显都会存在两种情况:邻域nodes不够k个,或者是邻域点多了。这个将在下面的章节进行讲解。
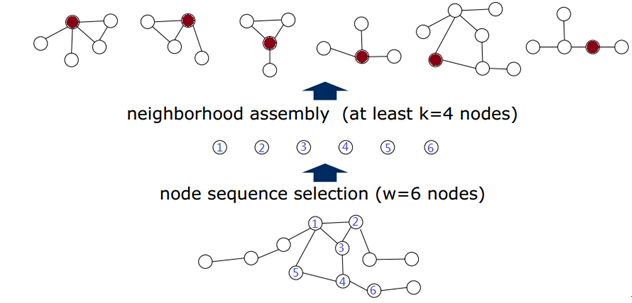
图6 Neighborhood Assemble结果
如图选出的是6个nodes,对于每一个node,首先找到其直接相邻的nodes(被称作是1-neighborhood),如果还不够再增加间接相邻的nodes。那么对于1-neighborhood就已经足够的情况,先全部放在候选的区域当中,在下一步当中通过规范化来做最终的选择。
3. 图规范化过程Graph Normalization
假设上一步Neighborhood Assemble过程当中一个node得到一个领域nodes总共有N个。那么N的个数可能和k不相等的。因此,normalize的过程就是要对他们打上排序标签进行选择,并且按照该顺序映射到向量当中。

图7 求解node的receptive filed
如果这个node的邻域nodes的个数不足的话,直接全部选上,不够补上哑节点(dummy nodes),但还是需要排序;如果数目N超过则需要按着排序截断后面的节点。如图7所示表示从选node到求解出receptive filed的整个过程。Normalize进行排序之后就能够映射到一个vector当中了。因此,这一步最重要的是对nodes进行排序。
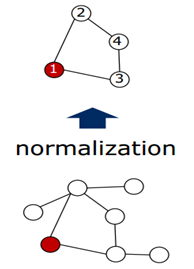
图8 Normalize 过程
如图8所示,表示对任意一个node求解它的receptive filed的过程。这里的卷积核的大小为4,因此最终要选出来4个node,包括这个node本身。因此,需要给这些nodes打上标签(labeling)。当然存在很多的方式,那么怎样的打标签方式才是最好的呢?如图7所示,其实从这7个nodes当中选出4个nodes会形成一个含有4个nodes的graph的集合。作者认为:在某种标签下,随机从集合当中选择两个图,计算他们在vector空间的图的距离和在graph空间图的距离的差异的期望,如果这个期望越小那么就表明这个标签越好!具体的表示如下:
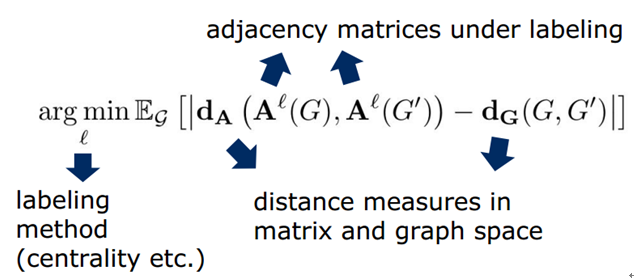
得到最好的标签之后,就能够按着顺序将node映射到一个有序的vector当中,也就得到了这个node的receptive field,如图6最右边所示。
4. 卷积网络结构Convolutional Architecture
文章使用的是一个2层的卷积神经网络,将输入转化为一个向量vector之后便可以用来进行卷积操作了。具体的操作如图9所示。
 图9 卷积操作过程
图9 卷积操作过程
首先最底层的灰色块为网络的输入,每一个块表示的是一个node的感知野(receptive field)区域,也是前面求解得到的4个nodes。其中an表示的是每一个node的数据中的一个维度(node如果是彩色图像那就是3维;如果是文字,可能是一个词向量……这里表明数据的维度为n)。粉色的表示卷积核,核的大小为4,但是宽度要和数据维度一样。因此,和每一个node卷季后得到一个值。卷积的步长(stride)为4,表明每一次卷积1个node,stride=4下一次刚好跨到下一个node。(备注:paper 中Figure1 当中,(a)当中的stride=1,但是转化为(b)当中的结构后stride=9)。卷积核的个数为M,表明卷积后得到的特征图的通道数为M,因此最终得到的结果为V1……VM,也就是图的特征表示。有了它便可以进行分类或者是回归的任务了。
基础问题:
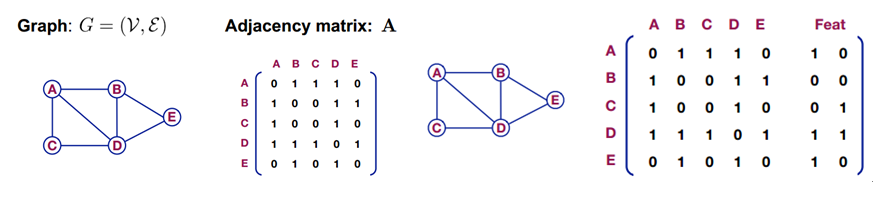
图的基本概念:主要有顶点和边构成,存在一个邻接矩阵A,如果对其中的nodes进行特征表示(Feat)的话如下右图。