1.Combiner
Combiner是MapReduce的一种优化手段。每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少map和reduce结点之间的数据传输量,以提高网络IO性能。只有操作满足结合律的才可设置combiner。
Combiner的作用:
(1)Combiner实现本地key的聚合,对map输出的key排序value进行迭代:如图所示:
map: (K1, V1) → list(K2, V2) combine: (K2, list(V2)) → list(K2, V2) reduce: (K2, list(V2)) → list(K3, V3)
(2)Combiner还有本地reduce功能(其本质上就是一个reduce)
例如wordcount的例子和找出value的最大值的程序 ,combiner和reduce完全一致,如下所示:
map: (K1, V1) → list(K2, V2) combine: (K2, list(V2)) → list(K3, V3) reduce: (K3, list(V3)) → list(K4, V4)
使用combiner之后,先完成的map会在本地聚合,提升速度。对于hadoop自带的wordcount的例子,value就是一个叠加的数字,所以map一结束就可以进行reduce的value叠加,而不必要等到所有的map结束再去进行reduce的value叠加。
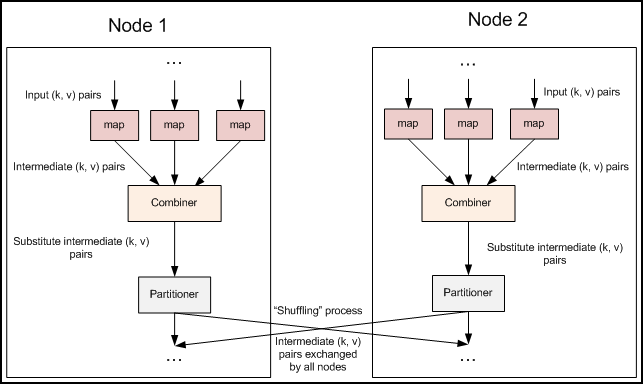
在实际的Hadoop集群操作中,我们是由多台主机一起进行MapReduce的,如果加入规约操作,每一台主机会在reduce之前进行一次对本机数据的规约,然后在通过集群进行reduce操作,这样就会大大节省reduce的时间,从而加快MapReduce的处理速度。
2.Partitioner
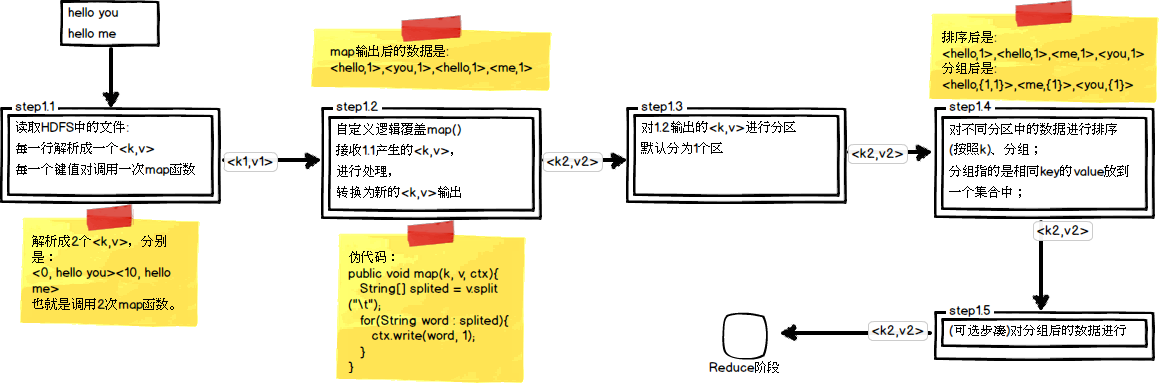
step1.3就是分区操作,哪个key到哪个reducer的分配过程,是由Partitioner规定的。
用户在中间key上使用分区函数来对数据进行分区,之后在输入到后续任务执行进程。一个默认的分区函数式使用hash方法(比如常见的:hash(key) mod R)进行分区。hash方法能够产生非常平衡的分区。
自定制Partitioner函数:
package mapreduce01;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class fenqu {
static String INPUT_PATH="hdfs://master:9000/test";
static String OUTPUT_PATH="hdfs://master:9000/output/fenqu";
static class MyMapper extends Mapper<Object,Object,IntWritable,NullWritable>{
IntWritable output_key=new IntWritable();
NullWritable output_value=NullWritable.get();
protected void map(Object key, Object value, Context context) throw IOException,InterruptedException{
int val=Integer.parseUnsignedInt(value.toString().trim());
output_key.set(val);
context.write(output_key,output_value);
}
}
static class LiuPartitioner extends Partitioner<IntWritable,NullWritable> {
@Override
public int getPartition(IntWritable key, NullWritable value, int numPartitions){
int num=key.get();
if(num>100) return 0;
else return 1;
}
}
static class MyReduce extends Reducer<IntWritable,NullWritable,IntWritable,IntWritable>{
IntWritable output_key=new IntWritable();
int num=1;
protected void reduce(IntWritable key,Iterable<NullWritable> values,Context context) throws IOException,InterruptedException{
output_key.set(num++);
context.write(output_key,key);
} }
public static void main(String[] args) throws Exception{
Path outputpath=new Path(OUTPUT_PATH);
Configuration conf=new Configuration(); |
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job,outputpath);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setNumReduceTasks(2);
job.setPartitionerClass(LiuPartitioner.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
}
}
分区Partitioner主要作用在于以下两点:
根据业务需要,产生多个输出文件;多个reduce任务并发运行,提高整体job的运行效率。
3.Shuffle过程
reduce阶段的三个步骤:
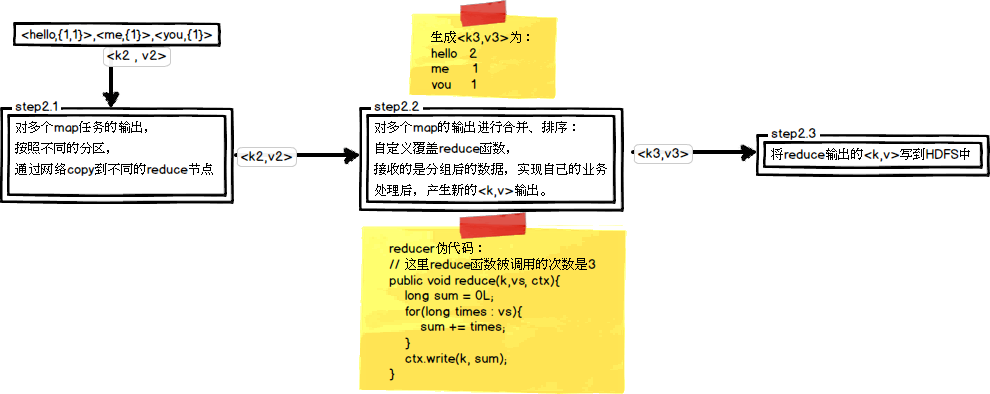
step2.1就是一个shuffle【随机、洗牌】操作
shuffle是什么:针对多个map任务的输出按照不同的分区(Partition)通过网络复制到不同的reduce任务节点上,这个过程就称作为Shuffle。
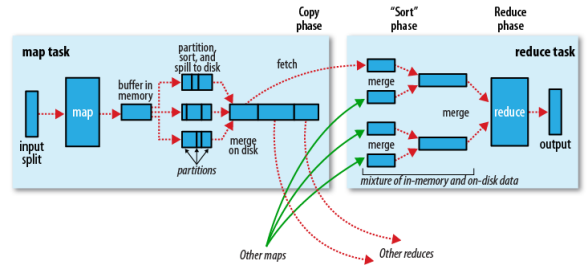
在map端:
1.在map端首先是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生<K2,V2>的输出,这些输出先存放在缓存中,每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
2.写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。
3.最后将磁盘中的数据送到Reduce中,图中Map输出有三个分区,有一个分区数据被送到图示的Reduce任务中,剩下的两个分区被送到其他Reducer任务中。而图示的Reducer任务的其他的三个输入则来自其他节点的Map输出。
reduce端:
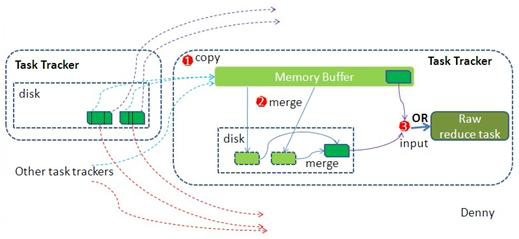
1. Copy阶段:Reducer通过Http方式得到输出文件的分区。
reduce端可能从n个map的结果中获取数据,而这些map的执行速度不尽相同,当其中一个map运行结束时,reduce就会从JobTracker中获取该信息。map运行结束后TaskTracker会得到消息,进而将消息汇报给JobTracker,reduce定时从JobTracker获取该信息,reduce端默认有5个数据复制线程从map端复制数据。
2.Merge阶段:如果形成多个磁盘文件会进行合并
从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
3.Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中。
4.排序sort
step4.1第四步中需要对不同分区中数据进行排序和分组,默认情况按照key进行排序和分组。
自定义类型MyGrouptestt实现了WritableComparable的接口,该接口中有一个compareTo()方法,当对key进行比较时会调用该方法,而我们将其改为了我们自己定义的比较规则,从而实现我们想要的效果。
自定义排序:
GroupSort.java
package mapreduce01;
import java.io.IOException;
import mapreduce01.fenqu.LiuPartitioner;
import mapreduce01.fenqu.MyMapper;
import mapreduce01.fenqu.MyReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class GroupSort {
static String INPUT_PATH="hdfs://master:9000/input/f.txt";
static String OUTPUT_PATH="hdfs://master:9000/output/groupsort";
static class MyMapper extends Mapper<Object,Object,MyGrouptest,NullWritable>{
MyGrouptest output_key=new MyGrouptest();
NullWritable output_value=NullWritable.get();
protected void map(Object key, Object value, Context context) throws IOException, InterruptedException{
String[] tokens=value.toString().split(",",2);
MyGrouptest output_key=new MyGrouptest(Long.parseLong(tokens[0]), Long.parseLong(tokens[1]));
context.write(output_key,output_value);
}
}
static class MyReduce extends Reducer<MyGrouptest,NullWritable,LongWritable,LongWritable>{
LongWritable output_key=new LongWritable();
LongWritable output_value=new LongWritable();
protected void reduce(MyGrouptest key,Iterable<NullWritable> values,Context context) throws IOException,InterruptedException{
output_key.set(key.getFirstNum());
output_value.set(key.getSecondNum());
context.write(output_key,output_value);
}
}
public static void main(String[] args) throws Exception{
Path outputpath=new Path(OUTPUT_PATH);
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job,outputpath);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(LiuPartitioner.class);
job.setMapOutputKeyClass(MyGrouptest.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(LongWritable.class);
job.waitForCompletion(true);
}
}
MyGrouptest.java
package mapreduce01;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class MyGrouptest implements WritableComparable<MyGrouptest> {
long firstNum;
long secondNum;
public MyGrouptest() {}
public MyGrouptest(long first, long second) {
firstNum = first;
secondNum = second;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(firstNum);
out.writeLong(secondNum);
}
@Override
public void readFields(DataInput in) throws IOException {
firstNum = in.readLong();
secondNum = in.readLong();
} /* * 当key进行排序时会调用以下这个compreTo方法 */
@Override
public int compareTo(MyGrouptest anotherKey) {
long min = firstNum - anotherKey.firstNum;
if (min != 0) { // 说明第一列不相等,则返回两数之间小的数
return (int) min;
}
else {
return (int) (secondNum - anotherKey.secondNum);
}
}
public long getFirstNum() { return firstNum; }
public long getSecondNum() { return secondNum; }
}