1.概念了解
hive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一个数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
2.hive的安装
(1)修改配置文件
/etc/profile


并使用scource /etc/profile使配置生效
在HIVE_HOME目录下,在conf/hive-env.sh中修改配置

修改hive-site.xml(本来是不存在的,可以复制hive-default.xml,然后重命名为hive-site.xml)
将<configuration></configuration>中的内容全部删除,换成如下内容:
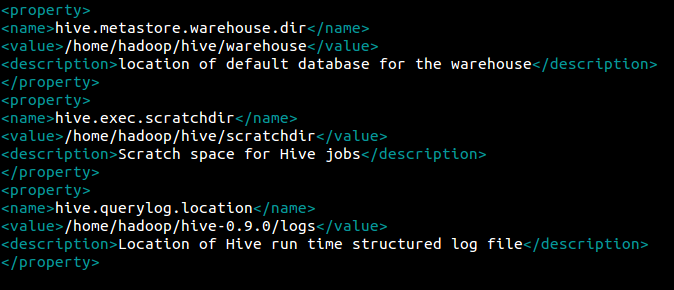
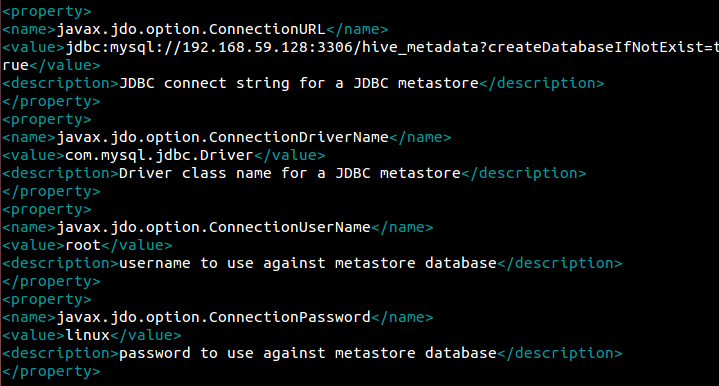
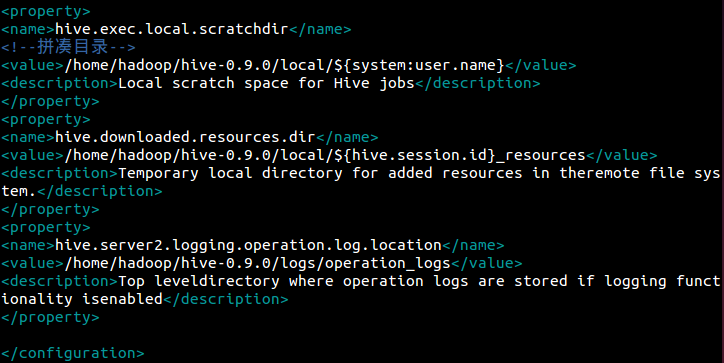
注意目录和IP地址的改变!
在HIVE_HOME下,创建文件local和logs。
在HIVE_HOME/conf中的配置文件,将hive-exec-log4j.properties.template重命名为:hive-exec-log4j.properties,将hive-log4j.properties.template重命名为:hive-log4j.properties
并在两个文件中修改内容:


(2)添加mysql驱动包放在HIVE_HOME/lib目录下
(3)修改hadoop的库文件
在$HADOOP_HOME/share/hadoop/yarn/lib下备份jline-0.9.94.jar
执行命令
$mv jline-0.9.94.jar jline-0.9.94.jar.bak
Copy高版本的jline
$cp $HIVE_HOME/lib/jline-2.12.jar $HADOOP_HOME /share/hadoop/yarn/lib
(4)验证是否安装成功:$hive

3.表的基本操作
(1)创建一个表名为student01的内部表
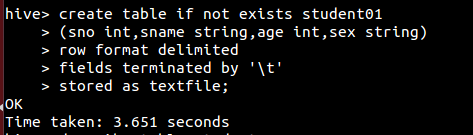
• create table 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 if not exists 选项来忽略这个异常
• external 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(location),如果文件数据是纯文本,可以使用 stored as textfile ,如果数据需要压缩,使用 stored as sequence 。
(2)创建一个表名为student2的外部表

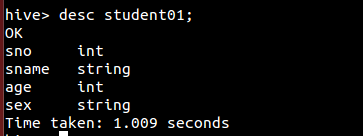
(3)展示表的元素
(4)向表中添加元素

(5)表名的更改

(6)表的删除
