csv模块包含在python标准库中,可用于分析CSV文件中的数据行,让我们能够快速提取感兴趣的值。首先绘制一个简单的折线图:
1 #!usr/bin/env python 2 #*-*Coding=UTF-8 *-* 3 import csv #导入csv模块 4 from matplotlib import pyplot as plt 5 6 filename = 'sitka_weather_07-2014.csv' #要处理的文件名,2014年7月的数值 7 8 with open(filename) as file_object: #打开文件filename并且将结果文件对象存储在file_object中 9 reader = csv.reader(file_object) #调用csv.reader()将文件对象file_object作为实参传递给阅读器reader 10 header_row = next(reader) #调用一次next,得到文件的第一行 11 row_2 = next(reader) #再调用一次next,就会得到文件第二行的内容 12 #print(header_row,row_2) 13 14 #文件头的格式并非总是一致,空格和单位可能总是出现在奇怪的地方。这在原始数据文件中很常见,但不会带来任何问题 15 #为让文件头更容易理解,将列表中的每个头文件及其位置打印出来 16 for index, column_header in enumerate(header_row): #调用enumerate()来获取每个元素的索引及其值。 17 print(index, column_header) #打印索引,还有对应的值 18 19 #提取并读取数据 20 highs = [] #创建空列表来存储最高气温 21 for row in reader: #在文件对象中循环读取每一行 22 print(row," ") #打印文件对象中的所有行 23 print(type(row[1])) #查看第一行第一列数据类型 24 #highs.append(row[1]) #把每一行索引为1的值(字符串)附加到列表,也就是文件中我们所需的最高气温 25 high = int(row[1]) #将每一行的索引值为1的类型为字符串的值转化成整型以便绘制图形 26 highs.append(high) #将转化成整型的数值依次附加到列表末尾 27 28 print(highs) #打印是不是符合预期 29 30 #绘制最高气温图表 31 fig = plt.figure(dpi=128,figsize=(16,9)) #定义图表输出样式 32 plt.plot(highs,c='red') #绘制最高气温并且把颜色设置成红色 33 34 plt.title("Daily High Temperatures of Sitka in July 2014",fontsize=14) #图形标题 35 plt.xlabel(" ",fontsize=10) #图形x轴标签 36 plt.ylabel("Temperatures (F) ",fontsize=10) #图形y轴标签 37 plt.tick_params(axis='both',which='major',labelsize=5) #刻度参数 38 39 plt.show() #显示图形
没有出错的话,效果图应该如下。应该注意的一点是,代码中,如果没把从每一行索引值为1的字符串转化成整型数据类型,matplotlib也能画图,但是绘制出来的图形不是预期的。
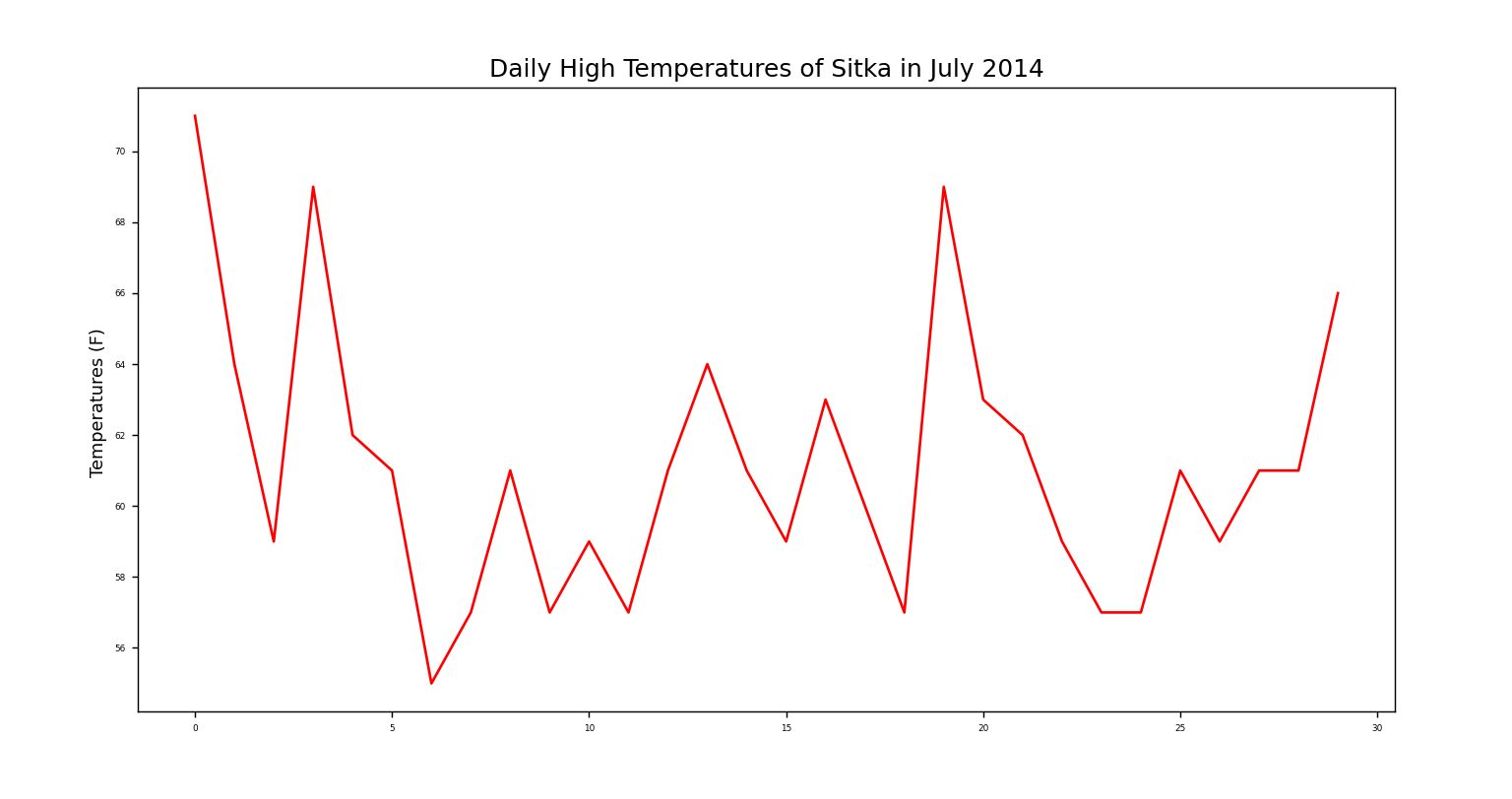
---------------------------------------------------------------------------------我是分割线---------------------------------------------------------------------------------
上面的图形只绘制了一个简单的表示最高气温的折线图,下面来添加时间还有最低气温还有涵盖更长时间(sitka_weather_2014.csv,即一整年的数值)以便比较:
1 #!usr/bin/env python 2 # *-* Coding=utf-8 *-* 3 4 import csv #导入csv模块 5 from matplotlib import pyplot as plt #导入模块以便绘图 6 from datetime import datetime #导入模块处理日期格式 7 8 filename = 'sitka_weather_2014.csv' #要处理的文件名 9 with open(filename) as file_object: #打开文件并将结果文件对象存储在file_object中 10 reader = csv.reader(file_object) #调用csv.reader()将文件对象file_object作为实参传递给阅读器reader 11 header_row = next(reader) #调用一次next,得到文件的第一行 12 row_2 = next(reader) #再调用一次next,得到文件第二行 13 print(header_row,row_2) #打印一下是不是符合预期 14 15 #文件头的格式并非总是一致,空格和单位可能总是出现在奇怪的地方。这在原始数据文件中很常见,但不会带来任何问题 16 for index, column_header in enumerate(header_row): #调用enumerate来获取每个元素的索引及其值 17 print(index, column_header) #打印索引还有对应的值 18 19 highs = [] #创建空列表以存储最高气温 20 dates =[] #创建空列表以存储日期 21 lows = [] #创建空列表以存储最低气温 22 for row in reader: #循环读取文件对象的每一行 23 high = int(row[1]) #把每一行索引为1的值即最高气温(字符串)转换成整型 24 date = datetime.strptime(row[0],"%Y-%m-%d") #利用datetime模块处理日期格式 25 low = int(row[3]) #把每一行索引为3的值即最低气温(字符串)转换成整型 26 27 highs.append(high) #将转换好的整型数值通过循环依次附加到列表末尾形成最高气温列表highs 28 dates.append(date) #将做好格式的日期通过循环依次福建到列表末尾以形成日期列表dates 29 lows.append(low) #将转换好的整型数值通过循环依次福建到列表末尾形成最低气温列表lows 30 31 print(highs,dates,lows) #打印一下是不是符合预期 32 #开始绘制图表 33 fig = plt.figure(dpi=128,figsize=(16,9)) #定义图表输出的dpi数值和输出格式 34 plt.plot(dates,highs,c='red',alpha=0.5) #绘制最高气温数据系列,并把线条设置为红色,不透明度设置为0.5 35 plt.plot(dates,lows,c='blue',alpha=0.5) #绘制最低气温数据系列,并把线条设置为蓝色,不透明度设置为0.5 36 plt.title("High and Low temperature of Sitka in 2014",fontsize=10) #图形标题 37 plt.xlabel(' ',fontsize=8) #x轴标签,绘制空标签,因为日期会出现在x轴标签位置 38 plt.ylabel("Temperatures (F) ",fontsize=8) #y轴标签 39 plt.tick_params(axis='both',labelsize=8) #刻度参数 40 fig.autofmt_xdate() #绘制斜体日期标签,以免日期标签太长而彼此重叠 41 #方法fill_between()接收一个x值系列和两个y值系列,并填充两个y值系列的空间 42 plt.fill_between(dates,highs,lows,color='green',alpha=0.1) #dates是x值系列,两个y值系列分别是highs和lows,颜色设置为绿色,不透明度设置为0.1 43 plt.show() #显示图形 44
没有出错的话,效果图应该如下。通过着色,让两个数据集之间的区域显而易见。
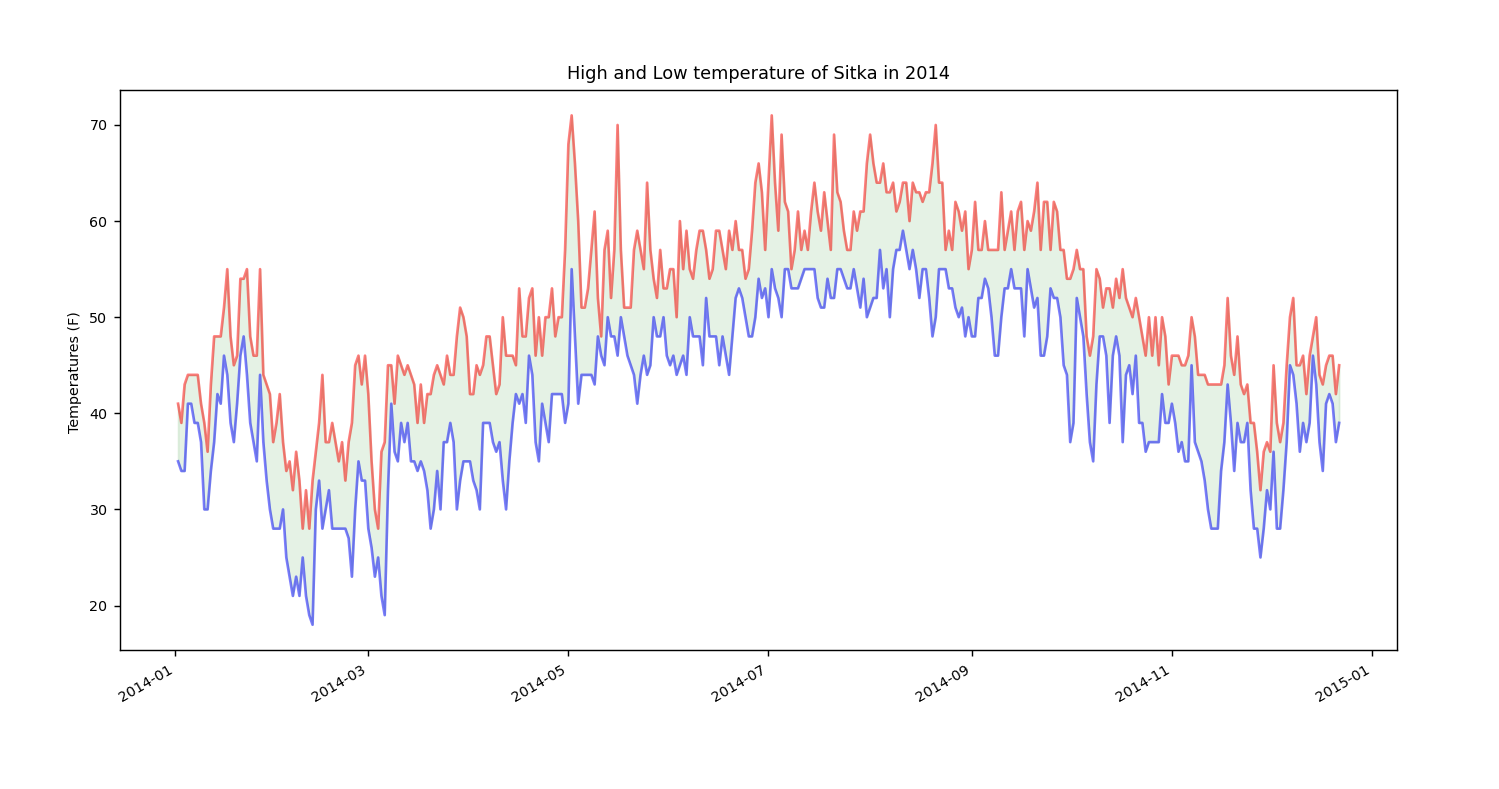
---------------------------------------------------------------------------------我是分割线---------------------------------------------------------------------------------
最后一个内容是错误检查。上面的代码,应该能处理来自世界各地任何地方的天气数据(可能会出现参数要改的情况),假定有的气象站出现了故障(或者服务器故障,或者工作人员粗心),未能收集部分或者全部应该收集的数据。缺失数据缺失可能会引发程序异常。下面把文件改成另一个文件,有数据缺失的情况。运行出现如下错误:
Traceback (most recent call last):
File "practice.py", line 23, in <module>
high = int(row[1]) #把每一行索引为1的值即最高气温(字符串)转换成整型
ValueError: invalid literal for int() with base 10: ''
这个错误表明,python无法将空字符串' '转换成整型。通过打印print(row),发现:
['2014-2-16', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '0.00', '', '', '-1']
2014年2月16日的一整行数据大部分都是空的,特别是需要的最高气温和最低气温。现在来改下代码以适应这种情况:
1 #!usr/bin/env python 2 # *-* Coding=utf-8 *-* 3 4 import csv #导入csv以处理csv文件 5 from matplotlib import pyplot as plt #从matplotlib导入pyplot以处理图形 6 from datetime import datetime #导入datetime以处理日期 7 8 filename = 'death_valley_2014.csv' #要处理的文件 9 with open(filename) as file_object: #打开文件并将结果文件对象存储在file_object中 10 reader = csv.reader(file_object) #调用csv.reader()将文件对象file_object作为实参传递给reader 11 header_row = next(reader) #调用next,读取文件的第一行 12 print(header_row) #打印是否符合预期 13 14 for index, column_header in enumerate(header_row): #调用enumerate()获取每个元素的索引和值 15 print(index,column_header) #打印索引还有对应的值 16 #文件头的格式并非总是一致,空格和单位可能总是出现在奇怪的地方。这在原始数据中非常常见,但不会带来任何问题。 17 #为让文件头更容易理解,将列表中的每个头文件及其位置打印出来 18 highs = [] #创建空列表以存储最高气温 19 dates = [] #创建空列表以存储日期 20 lows = [] #创建空列表以存储最低气温 21 22 for row in reader: #循环读取文件对象的每一行 23 #开始错误检查和处理,对于文件对象的每一行,都尝试从中提取日期,最高气温和最低气温,尝试失败就会引发ValueError异常 24 try: 25 high = int(row[1]) 26 date = datetime.strptime(row[0],"%Y-%m-%d") 27 low = int(row[3]) 28 except ValueError: #处理ValueError异常 29 #pass #直接pass,忽略 30 print(date,"data missing") #打印出缺失的数据日期和提示语 31 else: 32 highs.append(high) #将没有引发ValueError异常并且提取到的数值附加到列表highs末尾形成列表highs 33 dates.append(date) #将没有引发ValueError异常并且提取到的数值附加到列表dates末尾形成列表dates 34 lows.append(low) #将没有引发ValueError异常并且提取到的数值附加到列表lows末尾形成列表lows 35 36 fig = plt.figure(dpi=128,figsize=(16,9)) #定义图表输出的dpi数值和输出格式 37 plt.plot(dates,highs,c='red',alpha=0.5) #绘制最高气温数据系列,并把线条设置为红色,不透明度设置为0.5 38 plt.plot(dates,lows,c='blue',alpha=0.5) #绘制最低气温数据系列,并把线条设置为蓝色,不透明度设置为0.5 39 plt.title("High and Low Temperature (F) of Death Valley in 2014",fontsize=10) #图形标题 40 plt.xlabel(' ',fontsize=8) #x轴标签,绘制空标签,因为日期会出现在x轴标签位置 41 plt.ylabel('Temperature (F)',fontsize=8) #y轴标签 42 plt.tick_params(axis='both',which='major',labelsize=5) #刻度参数 43 fig.autofmt_xdate() #绘制斜体日期标签,以免日期标签太长而彼此重叠 44 #方法fill_between()接收一个x值系列和两个y值系列,并填充两个y值系列的空间 45 plt.fill_between(dates,highs,lows,color='green',alpha=0.1) #dates是x值系列,两个y值系列分别是highs和lows,颜色设置为绿色,不透明度设置为0.1 46 plt.show() #显示图形
没有出错的话,效果图应该如下。
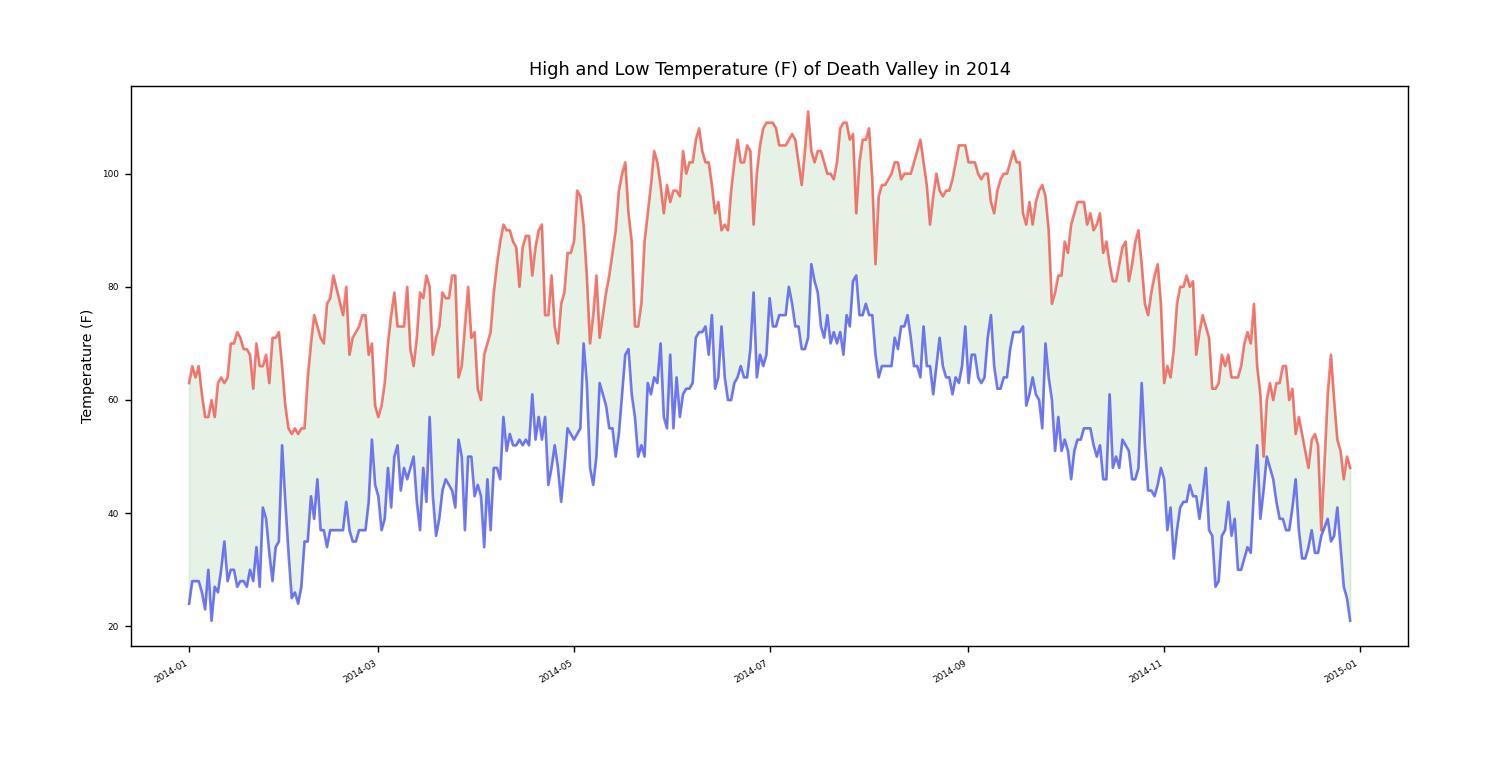
打完收工,数据参考:<python编程,从入门班到实践>。