电影《长津湖》是今年电影界的神,其他的不说,我来爬些豆瓣对长津湖的短评看看,暂时不做可视化。
"""
爬取一下豆瓣的长津湖短评,爬取短评的六个内容:
评论人,是否看过,星级(推荐力度),时间,获赞数,评论内容
将爬取的内容存储到csv文档中
"""
import requests
# from bs4 import BeautifulSoup
import parsel
import csv
# 首先建立csv文档
csvFile = open('长津湖豆瓣短评.csv', mode='a', encoding='utf-8-sig', newline='')
csvWriter = csv.DictWriter(csvFile, fieldnames=[
'评论人',
'是否看过',
'推荐力度',
'评论时间',
'获赞数量',
'评论内容',
])
# 先写头
csvWriter.writeheader() #写入表头
# 接下来是爬取数据
# 先建立header
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
# url规律,变化在start=的数字
# url = f'https://movie.douban.com/subject/25845392/comments?start={page}&limit=20&status=P&sort=new_score'
# 开始请求网页
for page in range(0, 120, 20): # 我这里就爬六页
url = f'https://movie.douban.com/subject/25845392/comments?start={page}&limit=20&status=P&sort=new_score'
response = requests.get(url, headers=headers) # 通过开发者工具,发现请求是get的,我这里就用get的
response.encoding = response.apparent_encoding
response.raise_for_status()
response.encoding = 'utf-8'
selector = parsel.Selector(response.text)
allData = selector.css('#comments div.comment-item')
for item in allData:
user = item.css('.comment-info a::text').get() # 获取评论人的名称
islook = item.css('.comment-info span::text').get() # 是否看过
# islook = item.css('.comment-info span:nth-child(2)::text').get() # 是否看过
isrecommended = item.css('.comment-info span::attr(title)').get() # 推荐力度
# isrecommended = item.css('.comment-info span:nth-child(3)::attr(title)').get() # 推荐力度
ratetime = item.css('.comment-info span:nth-child(4)::attr(title)').get().strip() # 评论时间
# followers = item.css('.comment-vote span::text').get() # 点赞数量
followers = item.css('.comment-vote span::text').get() # 点赞数量
print(followers)
# content = item.css('.comment-content .short::text').get() # 评论内容
content = item.css('.comment-content span::text').get()
csvwriterdict = {
'评论人': user,
'是否看过': islook,
'推荐力度': isrecommended,
'评论时间': ratetime,
'获赞数量': followers,
'评论内容': content,
}
print(csvwriterdict)
# 将上面的字典写入到csv文档
csvWriter.writerow(csvwriterdict)
csvFile.close() # 关闭文件
本来想用bs4爬的,看到某大神用parsel进行数据解析,学习下。存储的效果如下:
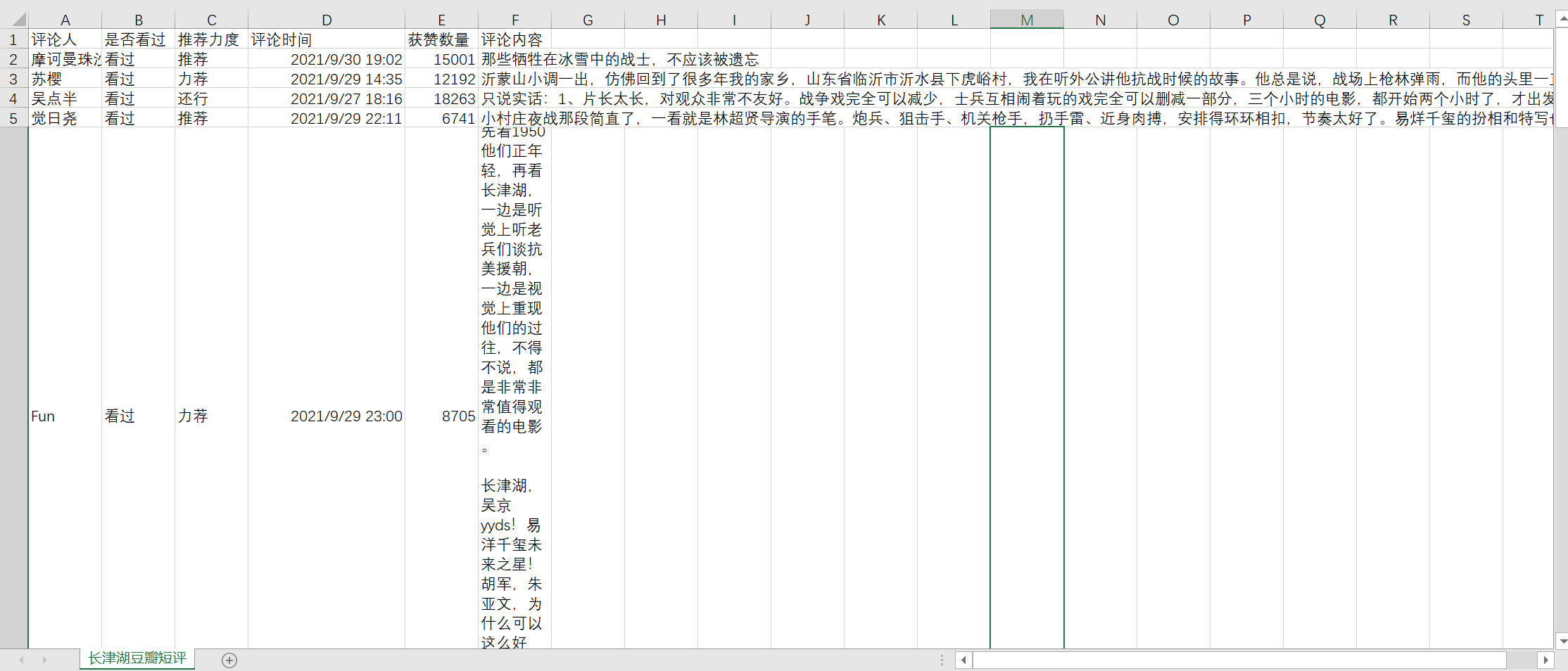
留几个问题,作为自己的动力。
1,用bs4或者selenium重新爬一次上面的项目;
2,做些可视化;
3,利用pandas的格式进行保存。
懒了,有空再做这几个。