本文仅用于学习和交流,不具有任何商业价值,如有问题,请与我联系,我会即时处理。--Python逐梦人。
网址分析
通过分析,没有json,只能用html解析获取数据,抓几个页面看看规律。因为要爬八大菜系,所以有横向和纵向比较。
横向:
https://www.douguo.com/caipu/%E7%B2%A4%E8%8F%9C/0/0 第一页
https://www.douguo.com/caipu/%E7%B2%A4%E8%8F%9C/0/20 第二页
纵向:
https://www.douguo.com/caipu/%E7%B2%A4%E8%8F%9C/0/20 https://www.douguo.com/caipu/%E5%B7%9D%E8%8F%9C/0/20 https://www.douguo.com/caipu/%E6%B9%98%E8%8F%9C/0/20
数据爬取与保存
然后发现,url的规律为:https://www.douguo.com/caipu/{菜系}/0/{页码},然后手动翻了下各菜系页码都是10页。开干:
1 """ 2 爬豆果美食的菜谱 3 url规律。 4 横向: 5 https://www.douguo.com/caipu/%E7%B2%A4%E8%8F%9C/0/0 第一页 6 https://www.douguo.com/caipu/%E7%B2%A4%E8%8F%9C/0/20 第二页 7 纵向(某一菜系的第二页): 8 https://www.douguo.com/caipu/%E7%B2%A4%E8%8F%9C/0/20 9 https://www.douguo.com/caipu/%E5%B7%9D%E8%8F%9C/0/20 10 https://www.douguo.com/caipu/%E6%B9%98%E8%8F%9C/0/20 11 爬取菜谱名,发布人,用料,评分,收藏人数,链接,图片。 12 """ 13 14 # 程序开始时间 15 import random 16 import time 17 import openpyxl 18 import parsel 19 import requests 20 import re 21 22 # 打开excel文档 23 wb = openpyxl.Workbook() 24 ws = wb.create_sheet(index=0) 25 # 写入表头 26 ws.cell(row=1,column=1,value='菜系') 27 ws.cell(row=1,column=2,value='菜名') 28 ws.cell(row=1,column=3,value='发布人') 29 ws.cell(row=1,column=4,value='用料') 30 ws.cell(row=1,column=5,value='评分') 31 ws.cell(row=1,column=6,value='详情页') 32 ws.cell(row=1,column=7,value='图片链接') 33 34 35 startTime = time.time() # 时间戳 36 headers = { 37 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36', 38 } 39 caixiList = ['川菜', '湘菜','粤菜','东北菜','鲁菜','浙菜','湖北菜','清真菜'] #中国菜系 40 for caixi in caixiList: # 循环读取菜系列表 41 print(f'=====================正在爬取{caixi}=====================') 42 time.sleep(random.uniform(2, 5)) # 随机生成一个实数,也就是浮点数 43 # 进行翻页 44 for page in range(0, 10+1): 45 print(f'==============开始爬取{caixi}的第{page+1}页==============') 46 url = f'https://www.douguo.com/caipu/{caixi}/0/{page*20}' 47 response = requests.get(url=url, headers=headers) 48 # print(response.text) 49 selector = parsel.Selector(response.text) # 解析selector 50 # 选取页面中所有的li标签 51 lis = selector.css('#left .mt25 ul li') 52 # print(lis) 53 for item in lis: 54 # print(item) 55 title = item.css('a::attr(title)').get() # 标题 56 sender = item.css('div .headicon img::attr(alt)').get() # 分享人 57 majorMaterial = item.css('.cook-info p::text').get() # 主要用料 58 try: 59 rate = item.css('.score span:nth-child(2)::text').get() # 评分 60 except: 61 rate = '无' 62 # try: 63 # bookmarks = item.css('.score span').re('[收藏人数]\d+') # 收藏人数 64 # except: 65 # bookmarks = '无' 66 detailPage = 'https://www.douguo.com' + item.css('a::attr(href)').get() # 详情页 67 imgLink = item.css('.cook-img img::attr(src)').get() #图片链接 68 # print(title, sender, majorMaterial, rate, detailPage, imgLink, sep=' | ') 69 ws.append([caixi, title, sender, majorMaterial, rate, detailPage, imgLink]) 70 print(f'==========={caixi}第{str(page+1)}页提取完成->>>>>>>>>>') 71 time.sleep(2) 72 73 endTime = time.time() 74 wb.save('豆果美食菜谱.xlsx') 75 print('共用时:', round((endTime-startTime)/60, 2), '分钟!')
数据清洗
按照自己习惯清洗数据。
1 import pandas as pd 2 3 df = pd.read_excel('豆果美食菜谱.xlsx') 4 # 去重 5 df = df.drop_duplicates() 6 # 按行去空值 7 df = df.dropna(how='any', axis=0) 8 # 评分字段清洗,把分去掉 9 df['评分'] = df['评分'].str.replace('分', '').astype('float') # 将分去掉并转换成浮点型 10 # 用料字段 11 df['用料'] = df['用料'].str.replace(',', ',') # 将中文逗号替换成西文逗号
数据清洗完后就可以可视化了。
数据可视化
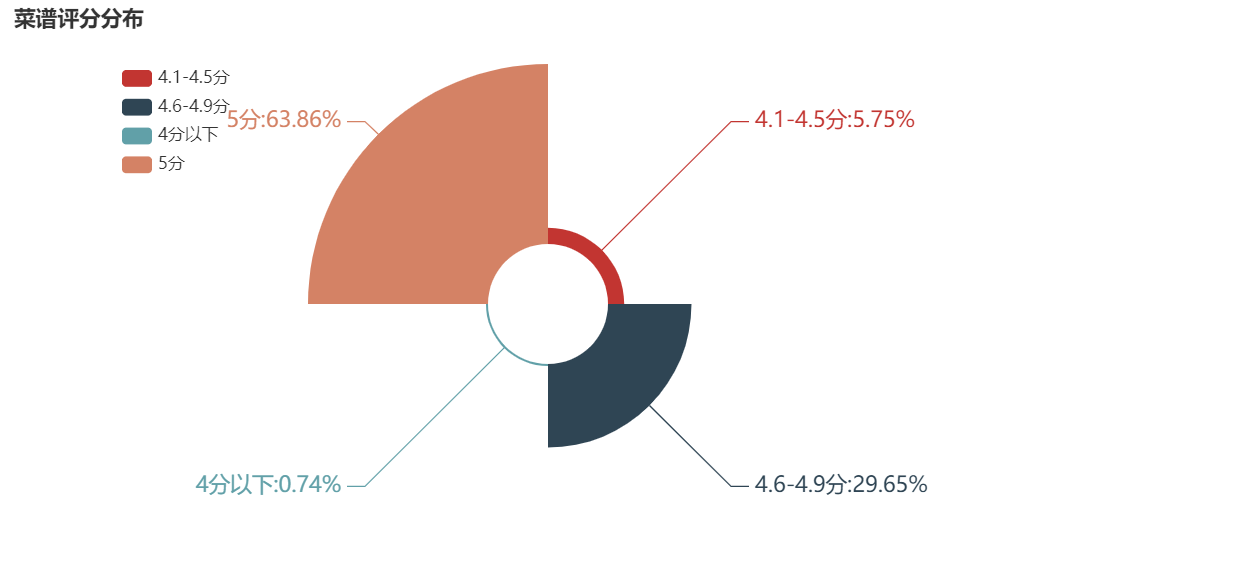
可视化一下评分分布:
1 # 菜谱评分分布 2 from pyecharts.charts import Page, Pie 3 import pyecharts.options as opts 4 from pyecharts.globals import ThemeType 5 6 cut = lambda x : '4分以下' if x < 4 else ('4.1-4.5分' if x <= 4.5 else('4.6-4.9分' if x <= 4.9 else '5分')) 7 print(cut) 8 df['评分分布'] = df['评分'].map(cut) 9 # print(df['评分分布']) 10 df2 = df.groupby('评分分布')['评分'].count() 11 df2 = round(df2, 2) 12 print(df2) 13 14 pie = ( 15 Pie() 16 .add('', [list(z) for z in zip(df2.index.tolist(), df2.tolist())], radius=['20%', '80%'], rosetype='area') 17 .set_global_opts( 18 title_opts=opts.TitleOpts('菜谱评分分布'), 19 legend_opts=opts.LegendOpts( 20 pos_left='10%', pos_top='10%', 21 orient='vertical', 22 textstyle_opts=opts.TextStyleOpts(font_size=14), 23 ), 24 ) 25 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18),) 26 ).render('菜谱评分分布.html')
运行后结果:
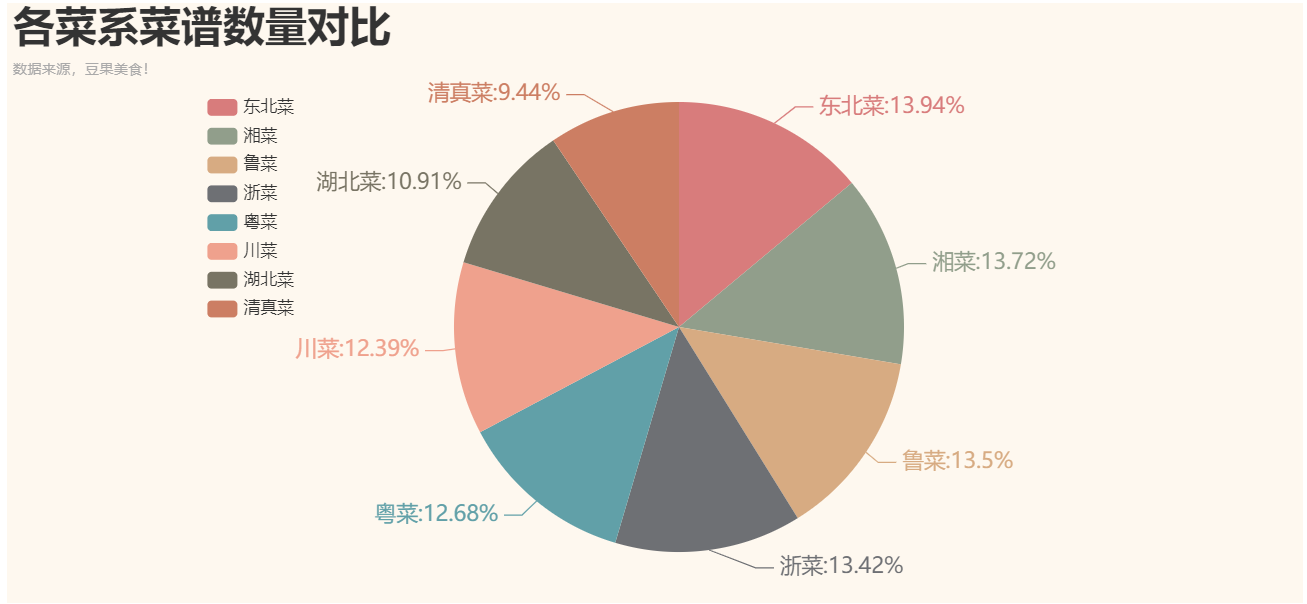
各系菜系数量对比:
1 # 各菜系菜谱数量对比 2 from pyecharts import options as opts 3 from pyecharts.charts import Page, Pie 4 df3 = df.groupby('菜系')['评分'].count() #按菜系分组,对评分统计 5 df3 = df3.sort_values(ascending=False) # 降序 6 print(df3) 7 8 p = ( 9 Pie(init_opts=opts.InitOpts(width='1080px', height='500px', theme=ThemeType.VINTAGE)) 10 .add(series_name='', center =[560, 270],data_pair= [list(z) for z in zip(df3.index.tolist(), df3.tolist())]) 11 .set_global_opts( 12 title_opts=opts.TitleOpts( 13 title='各菜系菜谱数量对比', 14 title_textstyle_opts=opts.TextStyleOpts(font_size=35), 15 subtitle='数据来源,豆果美食!' 16 ), 17 legend_opts=opts.LegendOpts( 18 orient='vertical', 19 pos_left='15%', 20 pos_top='15%', 21 textstyle_opts=opts.TextStyleOpts(font_size=14), 22 ), 23 ) 24 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%", font_size=18)) 25 ).render('各菜系菜谱数量分布图.html')
运行结果如下:
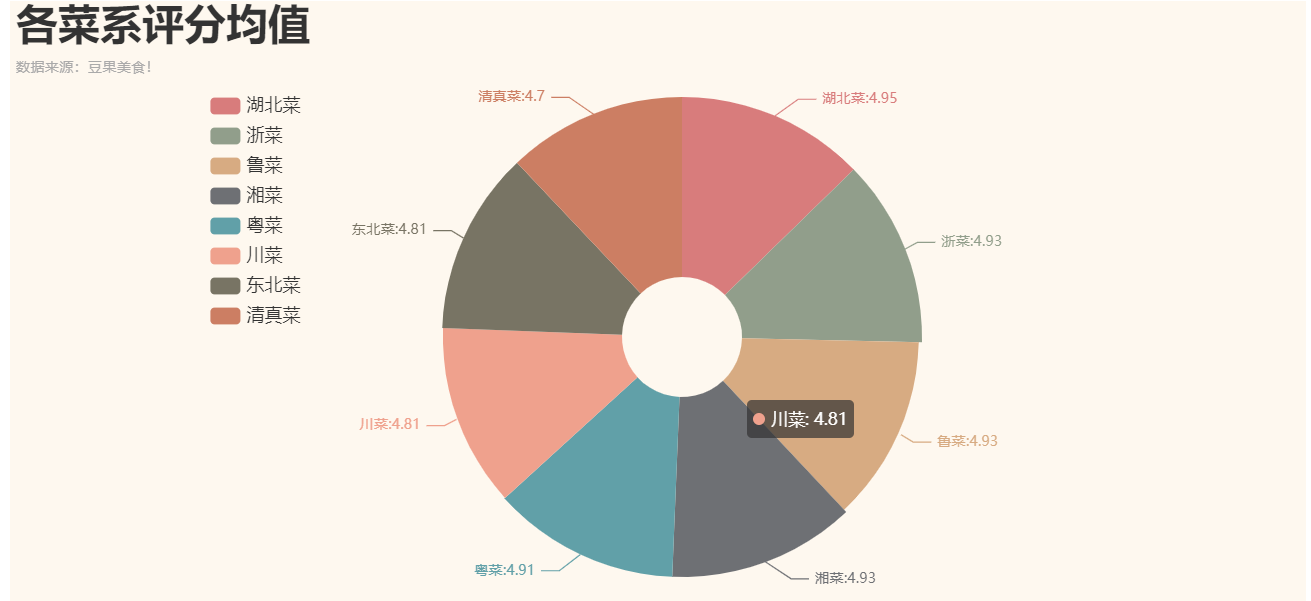
各菜系评分均值对比:
1 df4 = df.groupby('菜系')['评分'].mean() #计算平均值 2 df4 = df4.sort_values(ascending=False) #降序 3 df4 = df4.round(2) # 保留两位小数 4 5 c = ( 6 Pie(init_opts=opts.InitOpts(width='1080px', height='500px', theme=ThemeType.VINTAGE)) 7 .add(series_name='', center=[560, 280], data_pair=[list(z) for z in zip(df4.index.tolist(), df4.tolist())], radius=['20%','80%']) 8 .set_global_opts( 9 title_opts=opts.TitleOpts( 10 title='各菜系评分均值', 11 title_textstyle_opts=opts.TextStyleOpts(font_size=35), 12 subtitle='数据来源:豆果美食!', 13 ), 14 legend_opts=opts.LegendOpts( 15 orient='vertical', 16 pos_left='15%', 17 pos_top='15%', 18 textstyle_opts=opts.TextStyleOpts(font_size=15), 19 ), 20 ) 21 .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{c}")) 22 ).render('各菜系评分均值.html')
运行结果展示: