在最近做项目的时候碰到某个统计查询比较慢,比较影响效率,经过排查发现是这个程序使用了递归调用,我遍历的是组织架构,
当这个层级很深时这个程序就会越慢,
这是我写的统计某个组织的下属组织总数
1 /** 2 * 叠加父级下子级的数量(递归调用) 3 * @param pd 封装的PageData用来接受参数(可以理解成Map) 4 * @param res 初始为0 5 * @return 6 * @throws Exception 7 */ 8 public Integer listsubType(PageData pd,int res) throws Exception{ 9 int count=this.subType(pd);//统计该组织数量(可以是人员或者类型数量) 10 res+=count;//叠加每次的数量 11 List<PageData> list=listParentId(pd);//遍历该组织下属组织架构 12 for(PageData pd2:list){//遍历如果无则跳出 13 this.listsubType(pd2,res);//继续调用 14 } 15 return res;//返回统计结果 16 }
这个是我本地的数据库,数据量并不多
普通递归执行花费时间
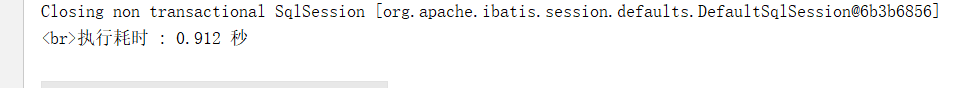
怎么优化一开始我并没有思路,但是通过百度我逐渐了解递归的效率可谓是声名狼藉,那么效率与代码简洁是否可以共存呢?答案是肯定的
尾递归 百度百科的解释为:如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的
让函数在末尾被调用,好办, 于是稍微改了下代码(其实就是把this改为了return)
1 /** 2 * 叠加父级下子级的数量(递归调用) 3 * @param pd 封装的PageData用来接受参数(可以理解成Map) 4 * @param res 初始为0 5 * @return 6 * @throws Exception 7 */ 8 public Integer listsubType(PageData pd,int res) throws Exception{ 9 int count=this.subType(pd);//统计数量 10 res+=count;//叠加每次的数量 11 List<PageData> list=listParentId(pd);//遍历该组织下属组织架构 12 for(PageData pd2:list){//遍历如果无则跳出 13 return listsubType(pd2,res);//继续调用 14 } 15 return res;//返回统计结果 16 }
尾递归执行花费时间

差距是不是很明显,当然我取得只是测试中某一个值,两者之间花费时间我也各测试了好几次,我取的是大概中间值
其实到了这一步也差不多完成了优化,可我对这其中的原理还是一知半解,普通递归好理解,但尾递归呢?于是继续研究
1 // 例一 2 function f(x){ 3 let y = f(x); 4 return y; 5 } 6 7 // 例二 8 function f(x){ 9 return f(x) + 1; 10 }
上面的的两个都不属于尾递归(不对,应该是不属于尾调用),因为在调用自身后它们还需要进行操作,
尾调用:尾调用是指一个函数里的最后一个动作是一个函数调用的情形,即这个调用的返回值直接被当前函数返回的情形。这种情形下称该调用位置称为“尾位置”
尾递归:若一个函数在尾位置调用自身,则称这种情况为尾递归。尾递归是递归的一种特殊情形
这样也算是初步理解了尾递归与尾调用的概念了
那么为什么普通递归与尾递归的查询效率会差这么多呢
查询资料得:
函数调用会在内存形成一个"调用记录",又称"调用帧"(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用记录上方,还会形成一个B的调用记录。等到B运行结束,将结果返回到A,B的调用记录才会消失。如果函数B内部还调用函数C,那就还有一个C的调用记录栈,以此类推。所有的调用记录,就形成一个"调用栈"(call stack)
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用记录,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用记录,取代外层函数的调用记录就可以了
自己理解的如下
这是用普通递归求1到n的和
1 int fn( int n ) 2 { 3 int result; 4 if(n<=0) 5 result=0; 6 else if(n==1) 7 result=1; 8 else 9 result=fn(n-1)+n; 10 return result; 11 }
如果输入的是3,那么大家理解的就是2+3=5,里面的真实计算为fn(0)+fn(1)+fn(2)+fn(3)
这是用尾递归求1到n的和
1 int fn( int n,int res) 2 { 3 if(n<=0) 4 return res=0; 5 else if(n==1) 6 return res; 7 8 return fn(n-1,n+res); 9 }
如果输入的是3,那么就是2+3=5等价于fn(2)+fn(3),因为2和3已经计算好的可以直接拿过来用,而不需要再次计算
不用尾递归,函数的堆栈耗用难以估量,需要保存很多中间函数的堆栈。比如f(n, sum) = f(n-1) + value(n) + sum; 会保存n个函数调用堆栈,而使用尾递归f(n, sum) = f(n-1, sum+value(n)); 这样则只保留后一个函数堆栈即可
以上我写的优化查询的确实有问题,但递归与尾递归的解释还是可以参考的