- Linux系统运行基础知识,如用户态、内核态。
- Linux内存管理相关知识,如虚拟地址、物理地址、页表。
- 汇编语言。
- C语言。
- 《深入理解计算机系统》
- 《操作系统导论》
- 《计算机组成与结构(清华大学出版社)》
- 《新一代汇编语言程序设计(高等教育出版社)》
- 博客:设备I/O模型(链接:https://github.com/zhangjaycee/real_tech/wiki/distri_018)
- 博客:Linux系统对IO端口和IO内存的管理(链接:https://blog.csdn.net/iteye_21199/article/details/82248794)
- 博客:浅谈内存映射I/O(MMIO)与端口映射I/O(PMIO)的区别(链接:https://www.cnblogs.com/idorax/p/7691334.html)
- 博客:PCI设备的地址空间(链接:https://www.cnblogs.com/zszmhd/archive/2012/05/08/2490105.html)
- 博客:PCIE的内存地址空间、I/O地址空间和配置地址空间(链接:https://www.cnblogs.com/yangxingsha/p/11551472.html)
- 博客:Linux内存寻址和内存管理(链接:https://www.cnblogs.com/zszmhd/archive/2012/08/29/2661461.html)
- StackOverflow:What does request_mem_region() actually do and when it is needed?(链接:https://stackoverflow.com/questions/7682422/what-does-request-mem-region-actually-do-and-when-it-is-needed)
- StackOverflow:What is the difference between DMA and memory-mapped IO(链接:https://stackoverflow.com/questions/3851677/what-is-the-difference-between-dma-and-memory-mapped-io)
- 文档:INS/INSB/INSW/INSD-从端口输入到字符串(链接:http://www.hgy413.com/hgydocs/IA32/instruct32_hh/vc139.htm)
- 博客:cpu指令如何读写硬盘(链接:https://blog.csdn.net/farmwang/article/details/49999879)
一、I/O体系结构
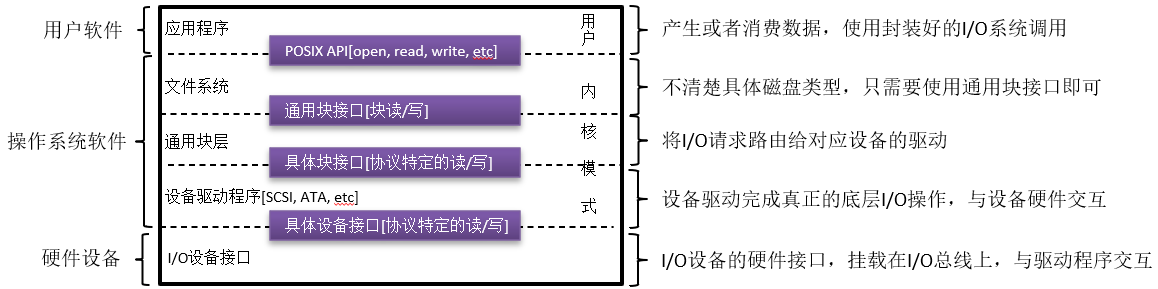
二、I/O设备与总线
本节我们学习I/O分层中的最底层,即与I/O设备相关的硬件知识。
2.1.标准I/O设备

2.2.计算机总线
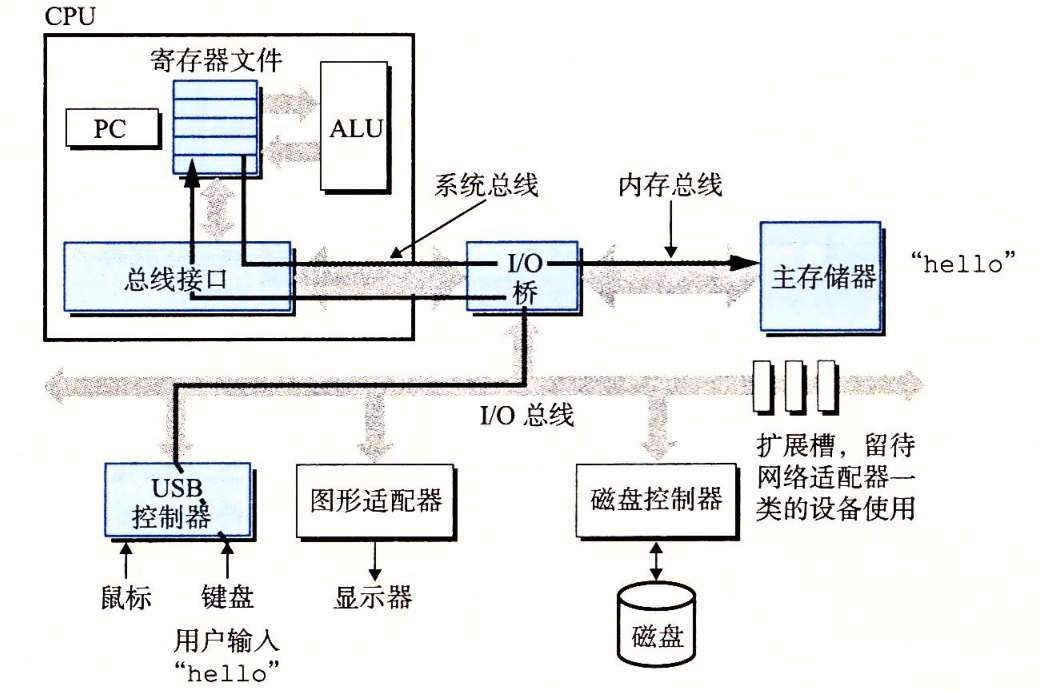
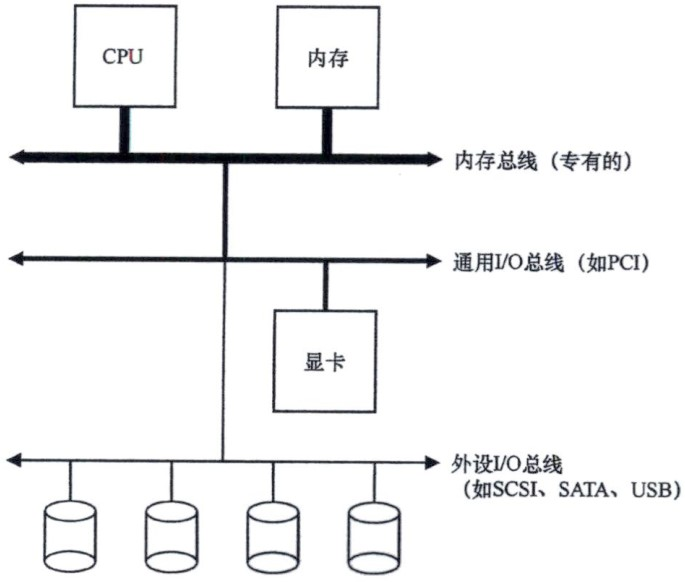
三、与I/O设备交互
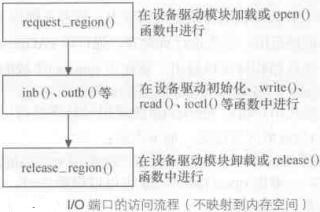
3.1.访问I/O设备
- PMIO:端口映射I/O(Port-mapped I/O)。将I/O设备独立看待,并使用CPU提供的专用I/O指令(如X86架构的in和out)访问。
- MMIO:内存映射I/O(Memory-mapped I/O)。将I/O设备看作内存的一部分,不使用单独的I/O指令,而是使用内存读写指令访问。
3.1.1.PMIO
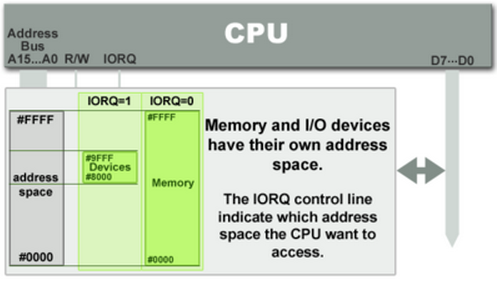
3.1.2.MMIO

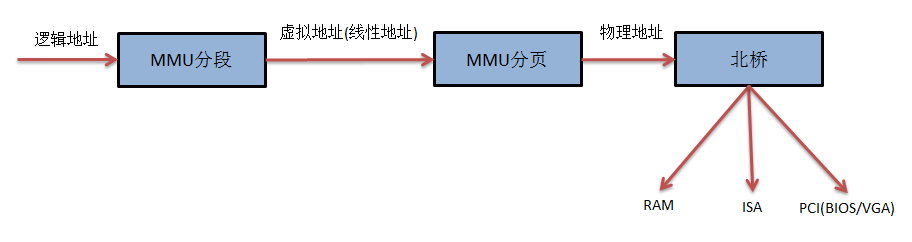
当CPU访问某个虚拟内存地址时,该虚拟地址首先转换为一个物理地址,对该物理地址的访问,会通过南北桥(现在被合并为I/O桥)的路由机制被定向到物理内存或者I/O设备上。因此,用于访问内存的CPU指令也可用于访问I/O设备,并且在内存(的物理)地址空间上,需要给I/O设备预留一个地址区域,该地址区域不能给物理内存使用。
3.1.3.PCI设备
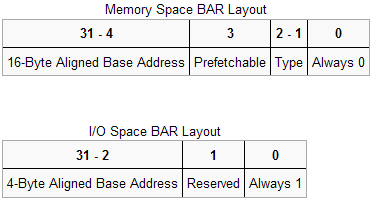
3.2.数据交互流程
3.2.1.标准交互流程

3.2.2.引入中断

为了深入理解,我们引入一段《操作系统导论》中的代码:
1 /** 2 * 等待设备就绪 3 */ 4 static int ide_wait_ready() { 5 while (((int r = inb(0x1f7)) & IDE_BSY) || !(r & IDE_DRDY))) 6 ; //轮询直到设备状态不为busy 7 } 8 9 /** 10 * 开始执行IO请求 11 */ 12 static void ide_start_request(struct buf *b) { 13 ide_wait_ready(); 14 outb(0x3f6, 0); //向IDE磁盘控制寄存器写入0,即开启中断 15 outb(0x1f2, 1); //向IDE磁盘命令寄存器的0x1f2地址写入扇区数 16 outb(0x1f3, b->sector & 0xff); //向IDE磁盘命令寄存器的0x1f3地址写入对应逻辑块地址的低字节 17 outb(0x1f4, (b->sector >> 8) & 0xff); //向IDE磁盘命令寄存器的0x1f3地址写入对应逻辑块地址的中字节 18 outb(0x1f5, (b->sector >> 16) & 0xff); //向IDE磁盘命令寄存器的0x1f3地址写入对应逻辑块地址的高字节 19 outb(0x1f6, 0xe0 | ((b->dev&1) << 4) | ((b->sector >> 24) & 0x0f)); //向IDE磁盘命令寄存器的0x1f6地址写入驱动编号 20 if (b->flags & B_DIRTY) { 21 outb(0x1f7, IDE_CMD_WRITE); //如果是写操作,向IDE磁盘命令寄存器的0x1f7地址写入写操作命令 22 outsl(0x1f0, b->data, 512/4); //向IDE磁盘命令寄存器的0x1f0地址写入数据 23 } else { 24 outb(0x1f7, IDE_CMD_READ); //如果是读操作,向IDE磁盘命令寄存器的0x1f7地址写入读操作命令 25 } 26 } 27 28 /** 29 * IDE磁盘读写 30 */ 31 void ide_rw(struct buf *b) { 32 acquire(&ide_lock); 33 for (struct buf **pp = &ide_queue; *pp; pp = &(*pp)->qnext) 34 ; //遍历链式队列,获取队尾元素 35 *pp = b; //将请求入队 36 if (ide_queue == b) 37 ide_start_request(b); //如果队列为空,直接执行请求 38 while ((b->flags & (B_VALID | B_DIRTY)) != B_VALID) 39 sleep(b, &ide_lock); //进程睡眠等待IO设备执行完请求,会释放锁ide_lock 40 release(&ide_lock); 41 } 42 43 /** 44 * 中断响应程序 45 */ 46 void ide_intr() { 47 struct buf *b; 48 acquire(&ide_lock); 49 if (!(b->flags & B_DIRTY) && ide_wait_ready() >= 0) 50 insl(0x1f0, b->data, 512/4); //如果是读请求,获取数据到内存 51 b->flags != B_VALID; 52 b->flags &= ~B_DIRTY; 53 wakeup(b); //唤醒等待的主线程 54 if ((ide_queue = b->qnext) != 0) 55 ide_start_request(ide_queue); //如果队列还有其他请求,则开始新的请求 56 release(&ide_lock); 57 }
这段代码描述了操作系统通过中断的方式向IDE磁盘发送I/O请求,通过3个主要函数来实现:
3.2.3.引入DMA
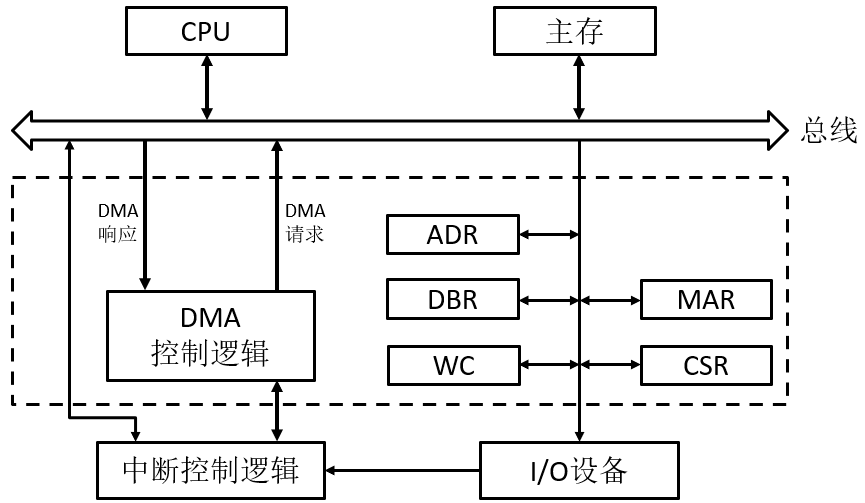
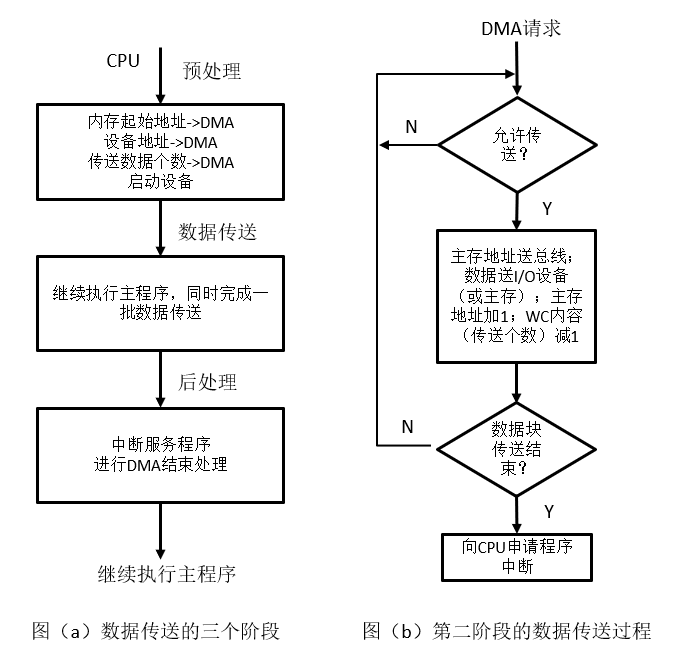

3.2.4.总结与补充
- PIO:即编程的I/O(programmed I/O),CPU参与数据移动,数据流向为"device <-> CPU register <-> memory"。
- DMA:CPU不参与数据移动,它只要启动I/O设备并向DMA控制器发送数据传输相关信息,就可以去执行其他任务,数据流向为"device <-> DMA <-> memory"。
四、Linux的具体实现
不同架构的CPU访问I/O设备的方式不尽相同,对Linux来说,它需要兼容多种访问方式,并尽可能提供统一的抽象。
4.1.共享内存地址空间
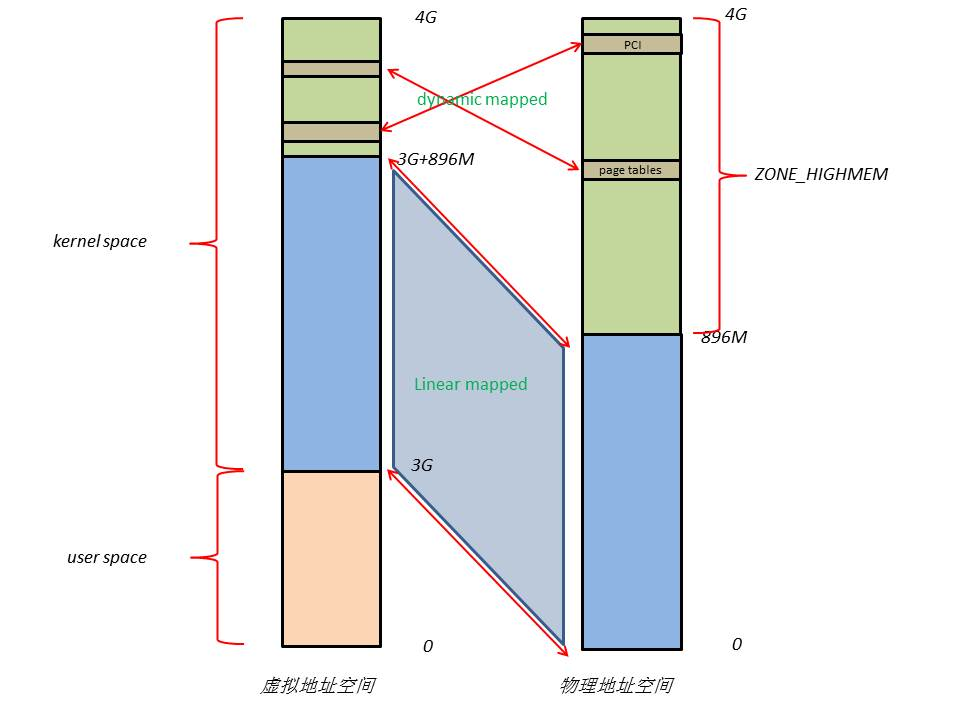
4.1.1.划分物理地址空间
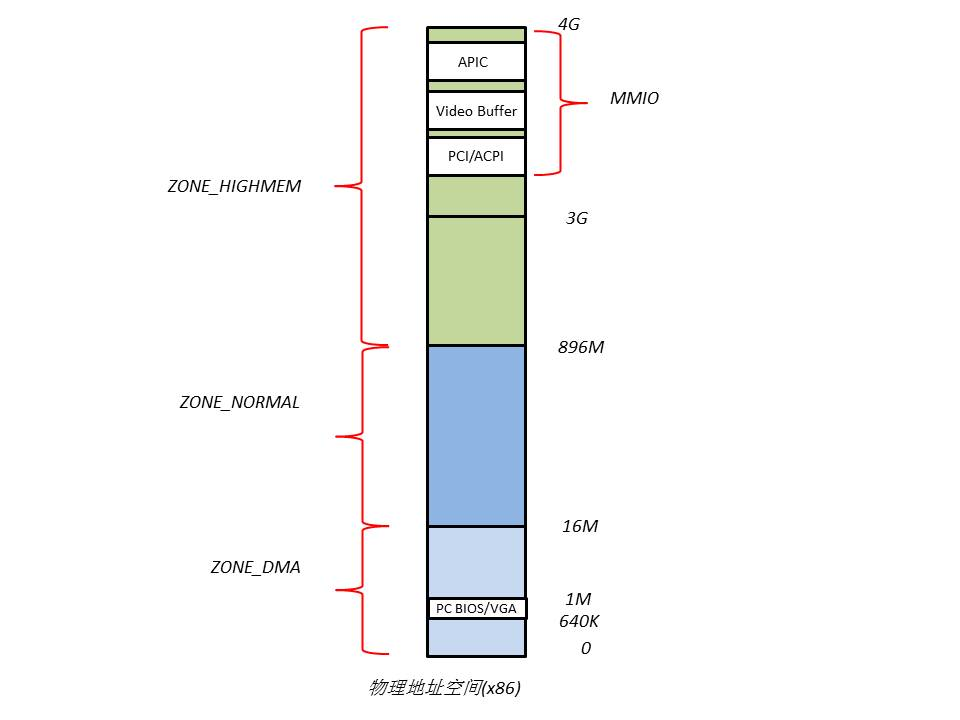
- ZONE_DMA:范围是0~16M,该段的内存页专门供I/O设备的DMA使用。之所以需要单独管理DMA的物理页,是因为DMA使用物理地址访问内存,不经过MMU,并且需要连续的缓冲区,所以为了能够提供物理上连续的缓冲区,必须从物理地址空间专门划分一段区域用于DMA。其中640K~1M这段地址空间被BIOS和VGA适配器所占据。
- ZONE_NORMAL:范围是16M~896M,该区域的物理页是内核能够直接使用的。
- ZONE_HIGHMEM:范围是896M~结束,该区域即为高端内存,内核不能直接使用。
可以看到,ZONE_DMA中640K~1M的区域以及ZONE_HIGHMEM中用于MMIO的区域,其被I/O设备等占用。当CPU访问这两个区域的物理地址时,北桥会自动将物理地址路由到相应的I/O设备上,不会发送给物理内存,因此在此处的物理内存无法被访问,从而形成RAM空洞。
4.1.2.内核虚拟地址空间
Linux使用分页机制管理内存,内核想要访问物理地址空间的话,必须先建立映射关系,然后通过虚拟地址来访问。为了能够访问所有的物理地址空间,就要将全部物理地址空间映射到1G的虚拟地址空间中,这显然不可能,于是内核采用了分类的思想来解决这个问题:
(1)内核将0~896M的物理地址空间一对一映射到自己的虚拟地址空间中,这样它便可以随时访问ZONE_DMA和ZONE_NORMAL里的物理页面,所以内核会将频繁使用的数据,如kernel代码、GDT、IDT、PGD、mem_map数组等放在ZONE_NORMAL里。
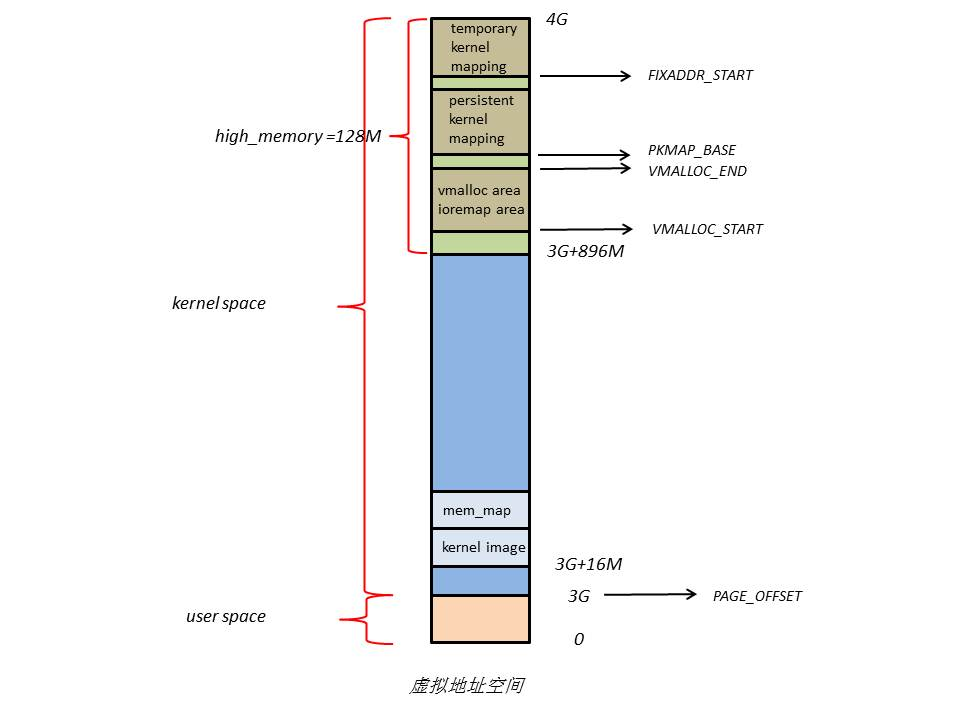
(2)此时内核剩下的128M虚拟地址空间不足以完全映射所有ZONE_HIGHMEM,Linux采取了动态映射的方法,即按需的将ZONE_HIGHMEM里的物理页面映射到kernel space的最后128M虚拟地址空间里,使用完之后释放映射关系,以供其它物理页面映射,虽然这样存在效率的问题,但是内核毕竟可以正常的访问所有的物理地址空间了。128M虚拟地址空间主要由3部分组成,分别为vmalloc area、持久化内核映射区、临时内核映射区,类似用户数据、页表(PT)等不常用数据放在ZONE_HIGHMEM里,只在要访问这些数据时才建立映射关系。
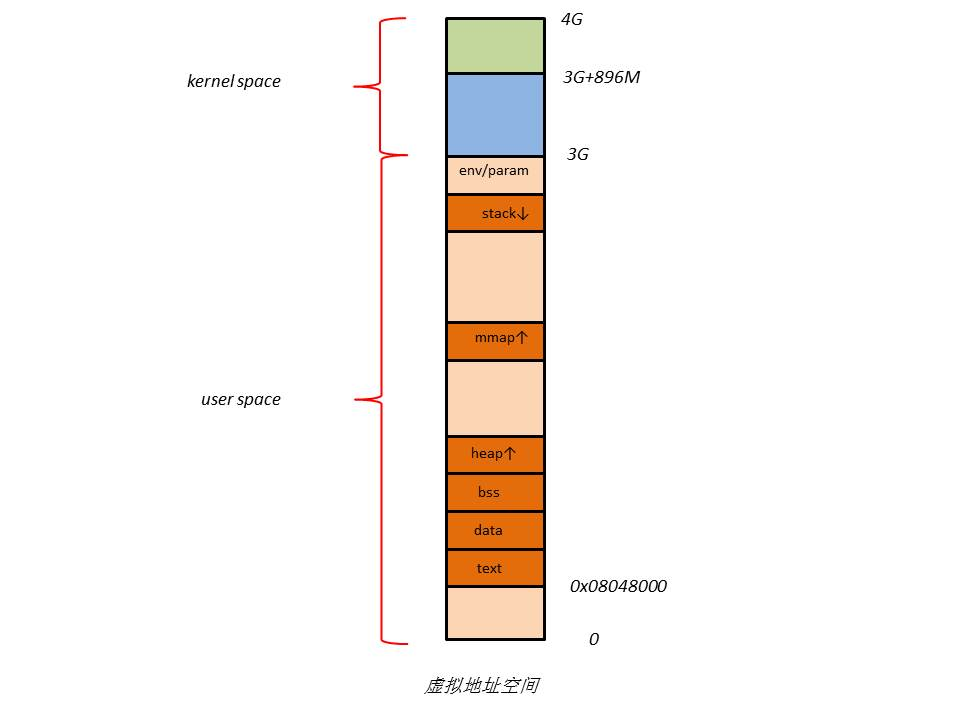
4.1.3.用户虚拟地址空间

4.2.抽象:I/O资源
1 struct resource { 2 resource_size_t start; //资源范围的开始 3 resource_size_t end; //资源范围的结束 4 const char *name; //资源拥有者的名字 5 unsigned long flags; //各种标志 6 struct resource *parent, *sibling, *child; //指向资源树中父亲,兄弟和孩子的指针 7 };
此外,Linux为PMIO和MMIO提供了2个独立的函数用于申请I/O资源,它们分别是request_region()、request_mem_region(),在使用I/O设备前,必须先通过它们申请I/O资源。我们可以简单看一下这两个函数的部分代码和注释:
1 //可以看到,这两个函数本质上都是宏定义,真正调用的是函数__request_region,但是传入的第一个参数不同 2 #define request_region(start, n, name) __request_region(&ioport_resource, (start), (n), (name)) 3 #define request_mem_region(start, n, name) __request_region(&iomem_resource, (start), (n), (name)) 4 5 //ioport_resouce,是I/O资源resource结构体的一个变量 6 struct resource ioport_resource = { 7 .name = "PCI IO", 8 .start = 0x0000, 9 .end = IO_SPACE_LIMIT, 10 .flags = IORESOURCE_IO, 11 }; 12 13 //iomem_resource,也是I/O资源resource结构体的一个变量 14 struct resource iomem_resource = { 15 .name = "PCI mem", 16 .start = 0UL, 17 .end = ~0UL, 18 .flags = IORESOURCE_MEM, 19 }; 20 21 //__request_region方法,代码略。该函数没有做实际性的映射工作,只是告诉内核要使用一块内存地址, 22 //并声明占有,内核会为其找到符合条件的一块内存地址 23 struct resource * __request_region(struct resource *parent, unsigned long start, unsigned long n, const char *name) { 24 //...... 25 }
Linux在使用I/O设备之前必须先申请I/O资源的做法,目的是告诉内核某个I/O设备的驱动程序将使用此范围的I/O地址,这将防止其他驱动程序对同一地址区域重复申请使用,该函数不进行任何类型的映射,它只是一种纯保留机制。
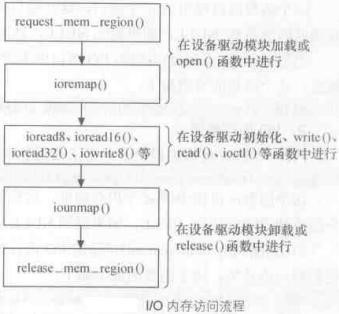
4.3.访问MMIO设备
4.4.访问PMIO设备
| 函数 | 说明 |
| inb()、inw()、inl() | 分别从I/O接口读取1、2或4个连续字节。后缀“b”、“w”、“l”分别代表一个字节(8位)、一个字(16位)以及一个长整型(32位) |
| inb_p()、inw_p()、inl_p() | 分别从I/O接口读取1、2或4个连续字节,然后执行一条“哑元(dummy,即空指令)”指令使CPU暂停 |
| outb()、outw()、outl() | 分别向一个I/O接口写入1、2或4个连续字节 |
| outb_p()、outw_p()、outl_p() | 分别向一个I/O端口写入1、2或4个连续字节,然后执行一条“哑元”指令使CPU暂停 |
| insb()、insw()、insl() | 分别从I/O端口读入以1、2或4个字节为一组的连续字节序列,字节序列的长度由该函数的参数给出 |
| outsb()、outsw()、outsl() | 分别向I/O端口写入以1、2或4个字节为一组的连续字节序列 |
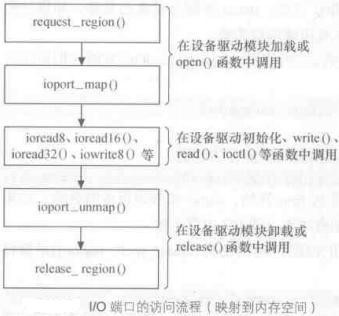
1 void __iomem *ioport_map(unsigned long port, unsigned int nr) { 2 if (port > PIO_MASK) 3 return NULL; 4 return (void __iomem *) (unsigned long) (port + PIO_OFFSET); 5 }
ioport_map仅仅是将I/O设备接口的物理地址简单加上PIO_OFFSET(64k),这样PMIO的64k地址空间就被映射到64k~128k之间,而ioremap()返回的虚拟地址则肯定在3G之上。ioport_map所谓的映射到内存空间行为实际上是给开发人员制造的一个“假象”,它并没有实际映射到内核虚拟地址,仅仅是为了让用户可以使用统一的辅助函数来访问I/O接口,这些辅助函数如下:
| 函数 | 说明 |
| unsigned int ioread8(void *addr) | 在I/O设备的端口地址被映射到虚拟地址之后,尽管可以直接通过指针访问这些地址,但是还是建议使用Linux内核的提供的函数来访问I/O映射内存。此函数用于读取指定I/O映射内存地址的连续8位 |
| unsigned int ioread16(void *addr) | 使用方式同ioread8,功能为读取指定I/O映射内存地址的连续16位 |
| unsigned int ioread32(void *addr) | 使用方式同ioread8,功能为读取指定I/O映射内存地址的连续32位 |
| void iowrite8(u8 value, void *addr) | 使用方式同ioread8,功能为向指定I/O映射内存地址写入8位数据 |
| void iowrite16(u16 value, void *addr) | 使用方式同ioread8,功能为向指定I/O映射内存地址写入16位数据 |
| void iowrite32(u32 value, void *addr) | 使用方式同ioread8,功能为向指定I/O映射内存地址写入32位数据 |
1 //ioread8源码,调用一个宏命令 2 unsigned int fastcall ioread8(void __iomem *addr) { 3 IO_COND(addr, return inb(port), return readb(addr)); 4 } 5 6 //宏命令IO_COND 7 #define VERIFY_PIO(port) BUG_ON((port & ~PIO_MASK) != PIO_OFFSET) 8 #define IO_COND(addr, is_pio, is_mmio) do { 9 unsigned long port = (unsigned long __force)addr; 10 if (port < PIO_RESERVED) { 11 VERIFY_PIO(port); 12 port &= PIO_MASK; 13 is_pio; 14 } else { 15 is_mmio; 16 } 17 } while (0) 18 19 //宏展开后的ioread8源码 20 unsigned int fastcall ioread8(void __iomem *addr) 21 { 22 unsigned long port = (unsigned long __force)addr; 23 if( port < 0x40000UL ) { 24 BUG_ON( (port & ~PIO_MASK) != PIO_OFFSET ); 25 port &= PIO_MASK; 26 return inb(port); 27 }else{ 28 return readb(addr); 29 } 30 }