在我们new一个webdriver的过程中,Selenium首先会确认浏览器的nativa component是否存在可用而且版本匹配。接着就在目标浏览器里启动一整套web service(实际上就是浏览器厂商提供的driver,比如IEDriver,ChromeDriver,他们都实现了WebDriver's wire protocol),这套web service使用了Selenium自己设计定义的协议,名字叫做The WebDriver Wire Protocol. 这套协议非常之强大,几乎可以操作浏览器做任何事情,包括打开、关闭、最大化、最小化、元素定位、元素点击、上传文件等等。
WebDriver Wire是通用的,也就是说不管是FirefoxDriver还是ChromeDriver,启动之后都会在某一个端口启动基于这套协议的Web Service。例如FirefoxDriver初始化成功之后,默认会从http://localhost:7055开始,而ChromeDriver则大概是https://localhost:46350之类的。接下来,我们调用WebDriver的任何API,都需要借助一个CommandExecutor发送一个命令,实际上是一个HTTP request给监听端口上的webservice。在我们的HTTP request的body中,会以webdriver wire协议规定的JSON格式的字符串来告诉Selenium我们希望浏览器接下来做什么事情。
可以更通俗的理解:由于客户端脚本(java,python,ruby)不能直接和浏览器通信,这时候可以把webservice当做一个翻译器,它可以把客户端代码翻译成浏览器可以识别的代码(比如js),客户端(也就是测试脚本)创建一个session,在该session中通过http请求向webservice发送restful的请求,webservice翻译成浏览器懂得脚本传给浏览器,浏览器把执行的结果返回给webservice,webservice把返回的结果做了一些封装(一般都是json格式),然后返回给client,根据返回值就能判断对浏览器的操作是不是执行成功。
摘自官网对于chrome driver的描述:
The ChromeDriver consists of three seperate pieces. There is the browser itself("chrome"), the language bindings provided by the Selenium project("the driver") and an executable downloaded from the Chromium proejct which acts as a bridge between "chrome" and the "driver". This executable is called "chromedriver", but we'll try and refer to it as the "server" in this page to reduce confusion.
大概意思就是我们下载的chrome可执行文件(.exe) 是为作为浏览器与client(language binding)桥梁的作用,也更印证了对于webservice(driver)的理解。
举个实际的例子:
WebDriver driver = new FirefoxDriver();
driver.get('http://www.google.com");
在执行driver.get('http://www.google.com");这句代码时,client也就是我们的测试代码向webservice(remote server)发送了如下的请求:
POST session/285b12e4-2b8a-4fe6-90e1-c35cba245956/url
post_data{"url":"http://google.com"}
通过POST的方式请求localhost:port/hub/session/session_id/url地址,请求浏览器完成跳转url的操作。
如果上述请求是可接受的,或者说web service是实现了这个接口,那么web service会跳转到该post data包含的url,并返回如下的response:
{"name":"get", "sessionid":"285b12e4-2b8a-4fe6-90e1-c35cba245956","status":0,"value":""}
该response中包含如下信息
name: web service端的实现的方法的名称,这里是get,表示跳转到指定url;
sessionid:当前session的id;
status:请求执行的状态码,非0表示未正确执行,这里是0,表示一切ok不必担心;
value:请求的返回值,这里返回值为空,如果client调用title接口,则该值应该是当前页面的title;
如果client发送的请求是定位某个特定的页面元素,则response的返回值可能是这样的:
{"name":"findElement","sessionId":"285b12e4-2b8a-4fe6-90e1-c35cba245956","status":0,"value":{"ELEMENT":"{2192893e-f260-44c4-bdf6-7aad3c919739}"}}
name,sessionid,status跟上面的例子是差不多的,区别是该请求的返回值是ELEMENT:{2192893e-f260-44c4-bdf6-7aad3c919739},表示定位到元素的id,通过该id,client可以发送如click之类的请求与server端进行交互。
下图表示了各种webdriver的工作原理
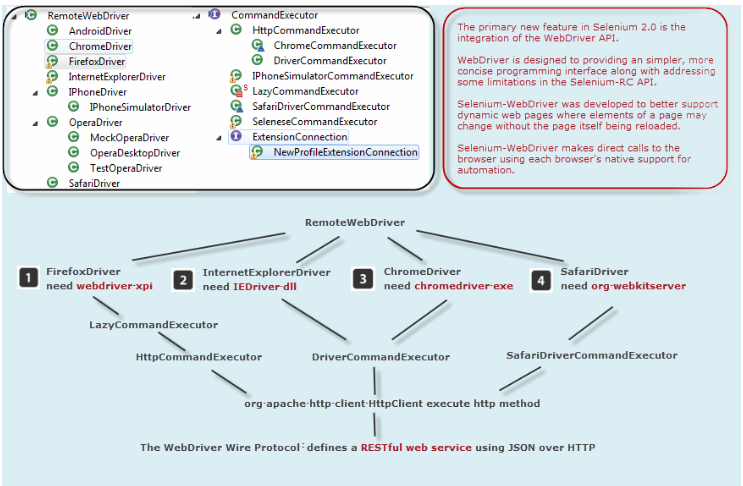
从上图我们可以看出,不同浏览器的webdriver子类,都需要依赖特定的浏览器原生组件,例如运行firefox就需要一个add-on名字叫webdriver.xpi。而IE的话就需要用到一个dll文件来转化web service的命令为浏览器native的调用。另外,图中还标明了WebDriver wire协议是一套基于RESTFUL的web service.
关于WebDriver Wire协议的细节,比如希望了解这套Web Service能够做哪些事情,可以阅读Selenium官方的协议文档,在Selenium的源码中,我们可以找到一个HttpCommandExecutor这个类,里面维护了一个Map<String, CommandInfo>, 它负责将一个个代表命令的简单字符串key,转化为相应的URL,因为REST的理念是将所有的操作视作一个个状态,每一个状态对应一个URI。所以当我们以特定的URL发送HTTP request给这个RESTFUL web service之后,它就能解析出需要执行的操作。截取一段源码如下:

可以看到实际发送的URL都是相对路径,后缀多以/session/:sessionId开头,这也意味着WebDriver每次启动浏览器都会分配一个独立的sessionId,多线程并行的时候彼此之间不会有冲突和干扰。例如我们最常用的一个WebDriver的API,getWebElement在这里就会转化为/session/:sessionid/element这个URL,然后在发出的HTTP request body内再附上具体的参数比如by ID还是CSS还是xpath,各自的值又是什么。收到并执行了这个操作之后,也会回复一个HTTP response。内容也是JSON,会返回找到的WebElement的各种细节,比如text, CSS selector, tag name, class name等等。以下是解析我们说的HTTP response的代码片段:
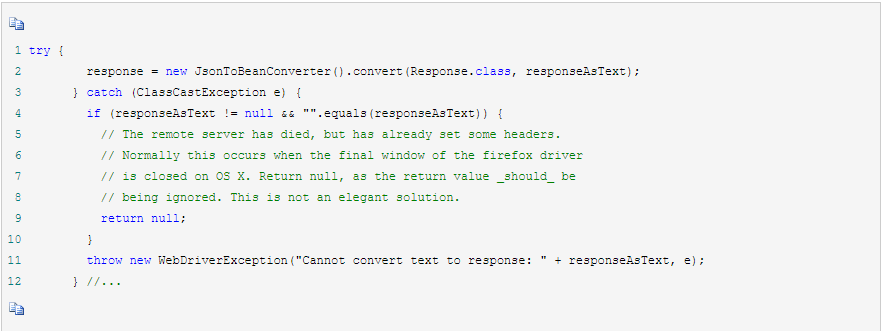
PS:如果想更深入的了解WebDriver的架构,可以参考该文章http://www.aosabook.org/en/selenium.html。