GIL,进程池/线程池
-
GIL的全称是: Global Interpreter Lock,意思就是全局解释器锁,这个GIL并不是python的特性,他是只在Cpython解释器里引入的一个概念,而在其他的语言编写的解释器里就没有这个GIL例如: Jython,Pypy
-
为什么会有GIL: 随着电脑多核cpu的出现和cpu频率的提升,为了充分利用多核处理器,进行多线程的编程方式更为普及,随之而来的困难是线程之间数据的一致性和状态同步,而python也利用了多核,所以也逃不开这个困难,为了解决这个数据不能同步的问题,设计了GIL全局解释器锁
-
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全.
-
在一个python的进程内,不仅有test.py的主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内.
-
所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(est.py的所有代码以及Cpython解释器的所有代码).例如: test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行.
-
所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码.
-
所以执行流程是:
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码(参数)交给解释器的代码去执行.解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题: 对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码
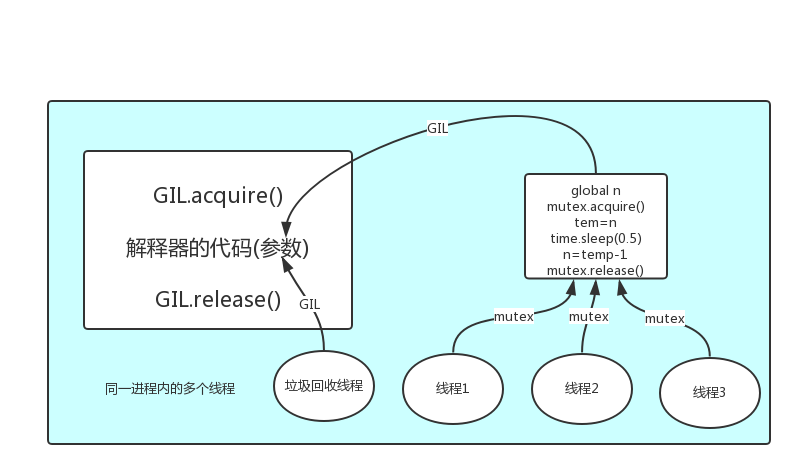
-
GIL与Lock
-
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理
-
GIL与多线程
我们有四个任务需要处理,处理方式肯定是要并发的效果,解决方案可以是: 方案一: 开启四个进程 方案二: 一个进程下,开启四个线程 # 单核情况下,分析结果: 如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,方案二胜 如果四个任务是I/O密集型,方案一创建进程的开销大,且进程的切换速度远不如线程,方案二胜 # 多核情况下,分析结果: 如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中同一时刻只有一个线程执行用不上多核,方案一胜 如果四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜 -
-
多线程与多进程性能测试
# 计算密集型
from multiprocessing import Process
from threading import Thread
import time
def task():
res = 1
for i in range(1, 10000000):
res += i
if __name__ == '__main__':
start_time = time.time()
lst1 = []
for i in range(4):
p = Process(target=task)
lst1.append(p)
p.start()
for i in lst1:
i.join()
print(f'总共用了:{time.time() - start_time}')
# 四个进程并行总共用了:1.272585868835449
start_time = time.time()
lst1 = []
for i in range(4):
t = Thread(target=task)
lst1.append(t)
t.start()
for i in lst1:
i.join()
print(f'总共用了:{time.time() - start_time}')
# 一个进程四个线程并发总共用了:3.891002655029297
# 计算密集型: 多进程的并行比单进程的多线程并发效率高很多
# 讨论IO密集型: 通过大量的任务去验证
from multiprocessing import Process
from threading import Thread
import time
def task():
time.sleep(3)
if __name__ == '__main__':
start_time = time.time()
lst1 = []
for i in range(150):
p = Process(target=task)
lst1.append(p)
p.start()
for i in lst1:
i.join()
print(f'总共用了:{time.time() - start_time}')
# 开启150个进程,开销大,速度慢,执行IO任务,总共用了:8.147555351257324
start_time = time.time()
lst1 = []
for i in range(150):
t = Thread(target=task)
lst1.append(t)
t.start()
for i in lst1:
i.join()
print(f'总共用了:{time.time() - start_time}')
# 开启150个线程,开销小,速度快,执行IO任务,总共用了:3.0526199340820312
# 任务是IO密集型,并且任务数量很大,用单进程下的多线程效率高
concurrent.futures -- 进程池/线程池模块
- 资源的复用
- 提高了效率
-
系统启动一个新线程/新进程的成本是比较高的,因为它涉及与操作系统的交互.在这种情形下,使用线程池/进程池可以很好地提升性能,尤其是当程序中需要创建大量生存期很短暂的线程/进程时,更应该考虑使用线程池/进程池.
-
线程池/进程池在系统启动时即创建大量空闲的线程/进程,程序只要将一个函数提交给线程池/进程池,线程池/进程池就会启动一个空闲的线程/进程来执行它.当该函数执行结束后,该线程/进程并不会死亡,而是再次返回到线程池/进程池中变成空闲状态,等待执行下一个函数
-
此外,使用线程池/进程池可以有效地控制系统中并发线程/进程的数量
-
从Python 3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的更高级的抽象,对编写线程池/进程池提供了直接的支持
-
常用方法
concurrent.futures模块提供了高度封装的异步调用接口 ThreadPoolExecutor:线程池,提供异步调用 ProcessPoolExecutor: 进程池,提供异步调用 1.submit(fn, *args, **kwargs): 将fn函数提交给线程池.*args代表传给fn函数的参数,*kwargs代表以关键字参数的形式为fn函数传入参数 2.map(func, *iterables, timeout=None, chunksize=1): 该函数类似于全局函数 map(func, *iterables),只是该函数将会启动多个线程,以异步方式立即对iterables执行 map处理 3.shutdown(wait=True): 关闭线程池 相当于进程池的pool.close() + pool.join()操作 wait=True,等待池内所有任务执行完毕回收完资源后才继续 wait=False,立即返回,并不会等待池内的任务执行完毕 但不管wait参数为何值,整个程序都会等到所有任务执行完毕 submit和map必须在shutdown之前 程序将task函数提交(submit)给线程池后,submit方法会返回一个Future对象,Future类主要用于获取线程任务函数的返回值.由于线程任务会在新线程中以异步方式执行,因此,线程执行的函数相当于一个“将来完成”的任务,所以Python使用Future来代表. Future 提供了如下方法: 1. cancel(): 取消该 Future 代表的线程任务.如果该任务正在执行,不可取消,则该方法返回 False;否则,程序会取消该任务,并返回 True. 2. cancelled(): 返回 Future 代表的线程任务是否被成功取消. 3. running(): 如果该 Future 代表的线程任务正在执行、不可被取消,该方法返回 True. 4. done(): 如果该 Funture 代表的线程任务被成功取消或执行完成,则该方法返回 True. 5. result(timeout=None): 获取该 Future 代表的线程任务最后返回的结果.如果 Future 代表的线程任务还未完成,该方法将会阻塞当前线程,其中 timeout 参数指定最多阻塞多少秒. 6. exception(timeout=None): 获取该 Future 代表的线程任务所引发的异常.如果该任务成功完成,没有异常,则该方法返回 None. 7. add_done_callback(fn): 为该 Future 代表的线程任务注册一个“回调函数”,当该任务成功完成时,程序会自动触发该 fn 函数.-
基本使用
from concurrent.futures import ThreadPoolExecutor from concurrent.futures import ProcessPoolExecutor import threading import time def func(n): time.sleep(2) print(f'{threading.get_ident()}打印的:{n}') return n**2 tpool = ThreadPoolExecutor(max_workers=5) # 默认线程池的线程数为CPU个数*5 # tpool = ProcessPoolExecutor(max_workers=5) # 进程池,默认进程池的进程数为CPU个数 # 异步执行 if __name__ == '__main__': t_lst = [] for i in range(5): t = tpool.submit(func, i) # 提交执行函数,返回一个结果对象,i作为任务函数的参数 t_lst.append(t) # print(t.result()) # 这个返回的结果对象t,不能直接去拿结果,不然又变成串行了 # 可以理解为拿到一个号码,等所有线程的结果都出来之后 # 我们再去通过结果对象t获取结果 tpool.shutdown() # 起到原来的close阻止新任务进来 + join的作用,等待所有的线程执行完毕 print('in 主进程/主线程') for el in t_lst: print('结果:', el.result()) # 12860打印的:1 # 19164打印的:0 # 4540打印的:3 # 5284打印的:2 # 19404打印的:4 # in 主进程/主线程 # 结果: 0 # 结果: 1 # 结果: 4 # 结果: 9 # 结果: 16 # 结果分析: 打印的结果是没有顺序的,因为到了func函数中的sleep的时候线程会切换,谁先打印就没准儿了,但是最后通过结果对象取结果的时候拿到的是有序的,因为主线程进行for循环的时候,是按顺序将结果对象添加到列表中的 # 也可以不等全部运行结束,每隔一段时间去取一次结果,哪个有结果了,就可以取出哪一个,如果有的结果对象里面还没有执行结果,那么什么也取不到,这一点要注意,不是空的,是什么也取不到 -
map的使用
map(func, *iterables, timeout=None, chunksize=1)方法,该方法的功能类似于全局函数 map(),区别在于线程池的 map() 方法会为 iterables 的每个元素启动一个线程,以并发方式来执行 func 函数.这种方式相当于启动 len(iterables) 个线程,井收集每个线程的执行结果
from concurrent.futures import ThreadPoolExecutor import threading import time def task(n): print(f'{threading.get_ident()}正在运行') time.sleep(2) return n*n if __name__ == '__main__': tpool = ThreadPoolExecutor(max_workers=5) # lst = [] # for i in range(1, 5): # future = tpool.submit(task, i) # lst.append(future) # for el in lst: # print(el.result()) s = tpool.map(task, range(1, 5)) # 取代了for循环+submit # 启动4个线程,并收集每个线程的执行结果 print([i for i in s]) -
回调函数的使用
from concurrent.futures import ThreadPoolExecutor import threading import time def task(n): print(f'{threading.get_ident()}正在运行') time.sleep(2) return n*n def call_back(m): print('结果为:', m.result()) if __name__ == '__main__': tpool = ThreadPoolExecutor(5) t_lst = [] for i in range(5): t = tpool.submit(task, i).add_done_callback(call_back)from concurrent.futures import ProcessPoolExecutor from multiprocessing import Pool import requests import os def get_page(url): print(f'进程{os.getpid()}拿到:{url}') res = requests.get(url) if res.status_code == 200: return {'url': url, 'text': res.text} def parse_page(res): res = res.result() print(f'进程{os.getpid()}分析{res["url"]}') parse_res = f'url:{res["url"]} size:{len(res["text"])} ' with open('db.txt', mode='a') as f: f.write(parse_res) if __name__ == '__main__': urls = [ 'https://www.baidu.com', 'https://www.python.org', 'https://www.openstack.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] # p = Pool(3) # for url in urls: # p.apply_async(get_page, args=(url,), callback=parse_page) # p.close() # p.join() p = ProcessPoolExecutor(3) for url in urls: p.submit(get_page, url).add_done_callback(parse_page) # parse_page拿到的是一个future对象obj,需要用obj.result()拿到结果
-