2018-10-08 22:40:48
线性回归(Linear Regression)是机器学习中最经典、最简单的线性模型。也是西瓜书中介绍的第一个模型。
1. 原理
西瓜书中LR的定义是:给定数集D={(x1,y1),(x2,y2),...,(xm,ym)},其中xi=(xi1;xi2;...;xid),yi属于R。LR试图学得一个线性模型以尽可能准确地预测实值输出标记。
最简单的情况是只有一个自变量x和一个因变更y的数据集,此时LR试图学得:f(xi)=wxi+b,使得f(xi)≈yi。
均方误差是LR最常用的性能度量。基于均方误差最小化来进行模型求解的方法是“最小二乘法”(least square method)。在LR中,最小二乘法就是试图找到一条直线,使所有样本到直线上的欧氏距离之和最小。
下面以鸢尾花数据集来进行一元线性回归模型的搭建。
2. 纯python实现
以Iris数据为例,进行LR编程。
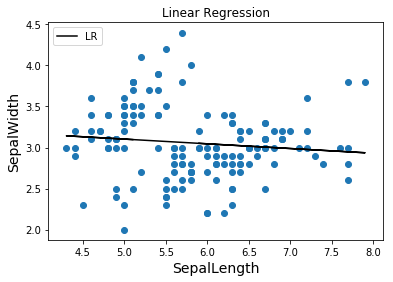
为了完成一元线性回归,仅取iris.csv的前两列
import numpy as np import pandas as pd import matplotlib.pyplot as plt """一元线性拟合 采用的拟合数据为iris.csv的前两列:SepalLength,SepalWidth """ #拟合曲线参数计算 def liner_fitting(data_x,data_y): size = len(data_x); i=0 sum_xy=0 sum_y=0 sum_x=0 sum_sqare_x=0 average_x=0; average_y=0; while i<size: sum_xy+=data_x[i]*data_y[i]; sum_y+=data_y[i] sum_x+=data_x[i] sum_sqare_x+=data_x[i]*data_x[i] i+=1 average_x=sum_x/size average_y=sum_y/size return_k=(size*sum_xy-sum_x*sum_y)/(size*sum_sqare_x-sum_x*sum_x) return_b=average_y-average_x*return_k return [return_k,return_b] #完成完后曲线上相应的函数值的计算 def calculate(data_x,k,b): datay=[] for x in data_x: datay.append(k*x+b) return datay #绘制数据点和拟合后的直线 def draw(data_x,data_y_new,data_y_old): plt.plot(data_x,data_y_new,color="black",label='LR') plt.scatter(data_x,data_y_old)
plt.xlabel('SepalLength',size=14)
plt.ylabel('SepalWidth',size=14) plt.title("Linear Regression") plt.legend(loc="upper left") plt.show() def createdata(): df = pd.read_csv('e:/00__python/iris.csv') datax = np.array(df[['SepalLength']]).tolist() datay = np.array(df[['SepalWidth']]).tolist() datax_list = [i for item in datax for i in item] datay_list = [i for item in datay for i in item] return datax_list, datay_list datax,datay = createdata() parameter = liner_fitting(datax,datay) draw_data = calculate(datax,parameter[0],parameter[1]) draw(datax,draw_data,datay)
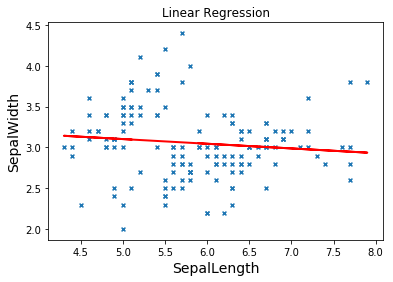
3. Sklearn实现
利用Sklearn的LinearRegression,sklearn内置了iris的处理函数,代码编写也会方便很多。
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.linear_model import LinearRegression #导入鸢尾花数据集并获取前两列数据,分别存储至x1和y1数组 irisD = load_iris() x1 = [n[0] for n in irisD.data] y1 = [n[1] for n in irisD.data] x = np.array(x).reshape(len(x),1) y = np.array(y).reshape(len(y),1) #直接用线性回归模型,进行训练和预测 clf = LinearRegression() clf.fit(x,y) pre = clf.predict(x) #第三步 调用Matplotlib扩展包并绘制相关图形 plt.scatter(x,y,s=15,marker='x') plt.plot(x,pre,color="r",linewidth=2,label='LR') plt.title("Linear Regression") plt.xlabel('SepalLength',size=14) plt.ylabel('SepalWidth',size=14) plt.show()