背景
桌面壁纸好久没有更新,感到有些审美疲劳。必应每日推荐高质量壁纸,有好心人已经做成了专门的必应壁纸站,更新桌面壁纸,顺便练手爬虫小程序。
分析
第一步提取出全部图片的链接,单个页面正则提取后,加个翻页功能即可。
第二步下载图片。
提取图片链接
单个页面
def getPageImgUrl(url):
headers = {
'use_agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:66.0) Gecko/20100101 Firefox/66.0',
}
res = requests.get(url,headers=headers).content
pattern = re.compile(r'data-progressive="(.*?)"')
urls = re.findall(pattern,res)
return urls
全部页面,这里取前10页
def getAllUrl():
l = []
for i in range(1,11):
url = 'https://bing.ioliu.cn/?p={}'.format(i)
u = getPageImgUrl(url)
l += u
return l
下载图片
def DownloadImg(url):
headers = {
'use_agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:66.0) Gecko/20100101 Firefox/66.0',
}
r = requests.get(url,headers=headers)
pattern = re.compile(r'/bing/(.*?)_1920')
filename = re.findall(pattern,url)
filename = str(filename)+'.jpg'
with open('/Users/markzhang/Documents/dailyimg/img/demo.jpg','w')as f:
os.getcwd()
os.chdir('/Users/markzhang/Documents/dailyimg/img/')
f.write(r.content)
os.rename('demo.jpg',filename)
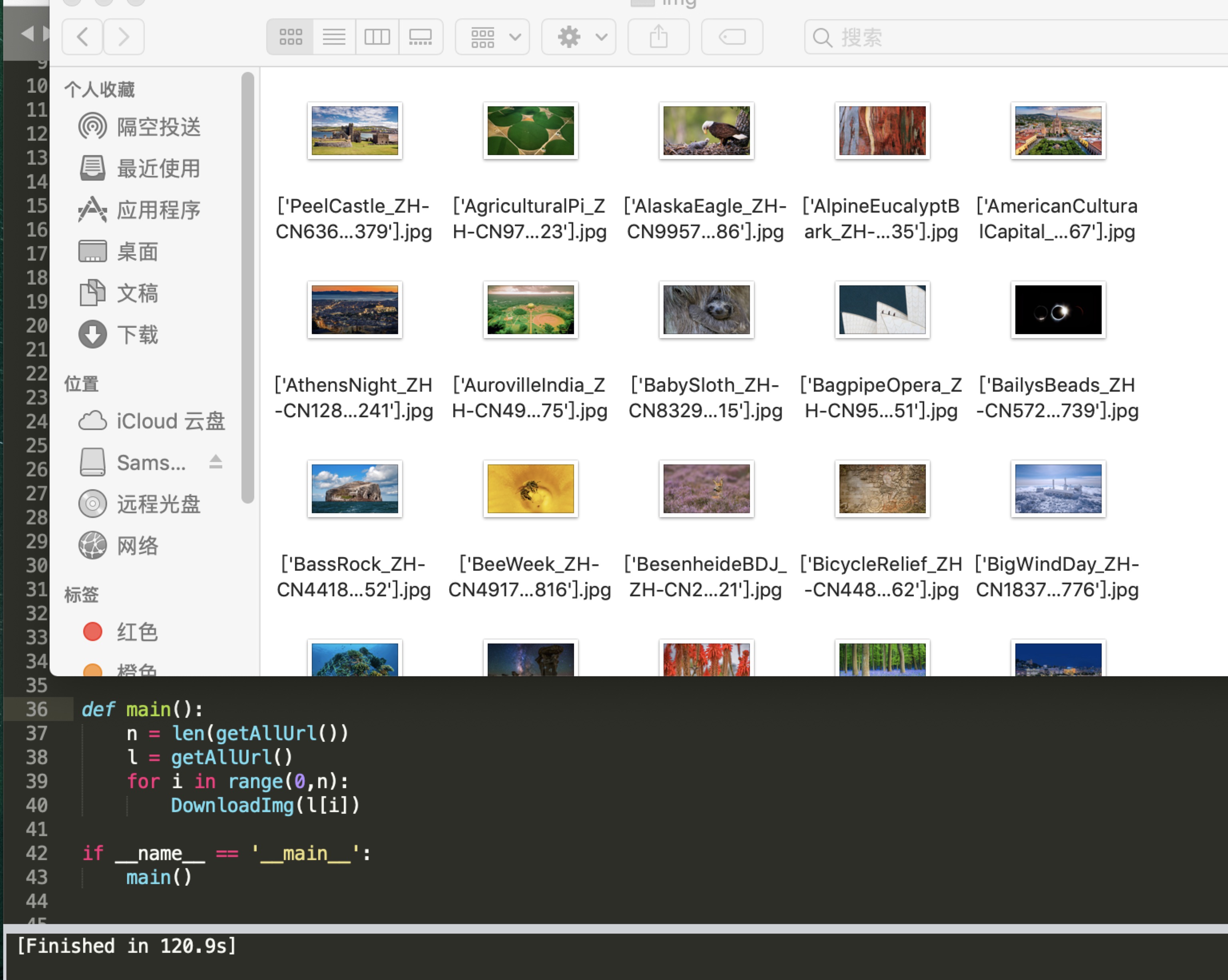
下载10页,120张图片,用了120s,两分钟,效率不高,凑合着用