1. Welcome
主要讲四部分内容:
non-personized systems
popularity: 基于流行度或者最大利益化的推荐。 缺点也明显:你可能在特殊地方有些特殊需求, 或者你本来就是大多数人不一样
Association: 找出订单里一起下单的物品的相关性,一般有Aproiri, FP 等算法
collaborative filtering
matrix factorization (and its variant like probablistic matrix factorization), also known as SVD
Deep learning

2. Simple recommentation systems
基于popularity 的推荐要考虑时效性,比如一则新闻虽然曾经是爆炸性的阅读量很多,但是不合适出现新闻的推荐中,这就需要在popularity 和 age(时间老化) 之间做平衡.
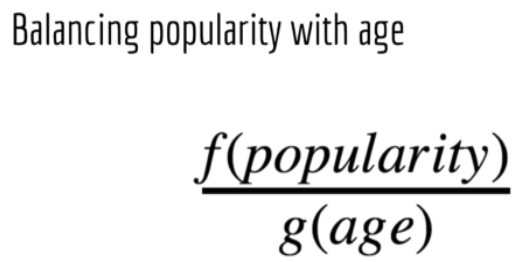
具体地,Hacker News 网站用的公式为:也叫 rank formula
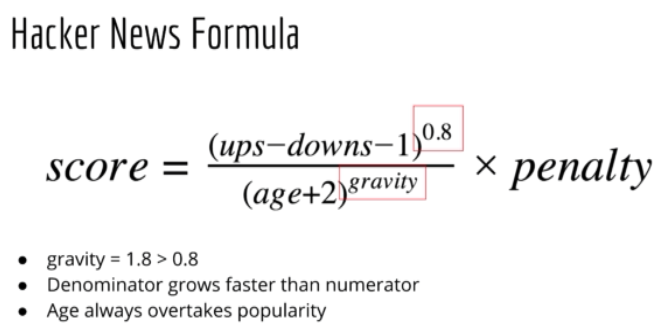
另一个具体的例子是Reddit:

如果平均值一样,那么需要考虑rating 个数,可以参考下面公式:

google 的 PageRank 算法是基于 Markov 模型的. Markov 模型就是NLP里面的unigram, bigram 的概念,基于前面的条件算出后面结果出现的概率.

怎么评估 Rank 结果

3. Collaborative Filtering
user-user CF - based on user-user similarity
item-item CF - based on item-item similarity
参考资料[2] 里面有具体的代码,不过不是矩阵实现,最好看我翻译的另一篇文章 Comprehensive Guide to build a Recommendation Engine from scratch (in Python) / 从0开始搭建推荐系统, 这里有矩阵实现, 更快而且我觉得更明白.
4. Matrix Factorization & Deep Leanring
4.1 Matrix Factorization

1. 先来个最basic 版的matrix factorization 的公式,就是把矩阵X分解成 X=WU. metric 用 Sum Squere Error. 这里面有个ALS的概念,spark里面实现了这个算法.

2. 再考虑 bias, user bias 和 item bias


3. formulas: with regularization


4. MF with SVD, 确定是不能有missing data (MF 和SVD 很相似,MF有两个矩阵U和V, SVD 有3个 U,S,V), 很多人认为SVD 和MF是一回事,作者认为SVD和MF不一样,因为SVD在有missing value的时候都不工作.

5. Probabilistic Matrix Factorization, 没看懂,只能拷些图片在这里了



6. Bayesian Matrix Factorization, 也没看懂,讲者说是optional 就不看了
7. matrix factorization in Keres
# keras model u = Input(shape=(1,)) m = Input(shape=(1,)) u_embedding = Embedding(N, K, embeddings_regularizer=l2(reg))(u) # (N, 1, K) m_embedding = Embedding(M, K, embeddings_regularizer=l2(reg))(m) # (N, 1, K) # subsubmodel = Model([u, m], [u_embedding, m_embedding]) # user_ids = df_train.userId.values[0:5] # movie_ids = df_train.movie_idx.values[0:5] # print("user_ids.shape", user_ids.shape) # p = subsubmodel.predict([user_ids, movie_ids]) # print("p[0].shape:", p[0].shape) # print("p[1].shape:", p[1].shape) # exit() u_bias = Embedding(N, 1, embeddings_regularizer=l2(reg))(u) # (N, 1, 1) m_bias = Embedding(M, 1, embeddings_regularizer=l2(reg))(m) # (N, 1, 1) x = Dot(axes=2)([u_embedding, m_embedding]) # (N, 1, 1) # submodel = Model([u, m], x) # user_ids = df_train.userId.values[0:5] # movie_ids = df_train.movie_idx.values[0:5] # p = submodel.predict([user_ids, movie_ids]) # print("p.shape:", p.shape) # exit() x = Add()([x, u_bias, m_bias]) x = Flatten()(x) # (N, 1)
model = Model(inputs=[u, m], outputs=x)
model.compile(
loss='mse',
# optimizer='adam',
# optimizer=Adam(lr=0.01),
optimizer=SGD(lr=0.08, momentum=0.9),
metrics=['mse'],
)
4. 2 Deep Learning
1. 在matrix factorization 上加了deep network, 形成的 deep learning. 前面讲的 matrix factorization 只是linear model, deep learning 会提供 non-linear 能力,所以理论上比只有前面棕色部分(matrix factorization部分)好
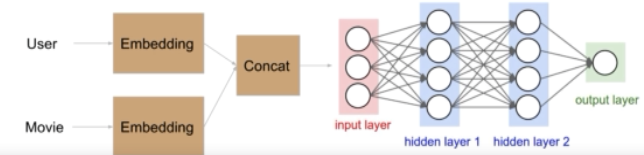
2. 还可以先分支网络,然后再合并,课程里叫 residual, 我觉得不是computer vision里面的 resnet 的概念.

3. 还可以用 AutoEncoder (AutoRec), 这个算法本来是用来复原图片的. model.fit(X, X) not model.fix(X, Y).

AutoRec 比deep learning 快,原因如下

AutoRec 算法要注意一个问题,因为这个算法是用来反推输入X的,输出就是预测的输入,所有网络可能会直接copy back, 有欺骗性。因此,我们不能直接用 test_set 来预测 test_set 的输出,而是用train_set 来预测test_set, 看下面代码


5. Retricted Boltzmann Machines (RBMs) for Collaborative Filtering
受限波兹曼机(RBMs)是波兹曼机的简化版,不是全部连接,只需要 visible nodes 和 hidden nodes 连接就行.
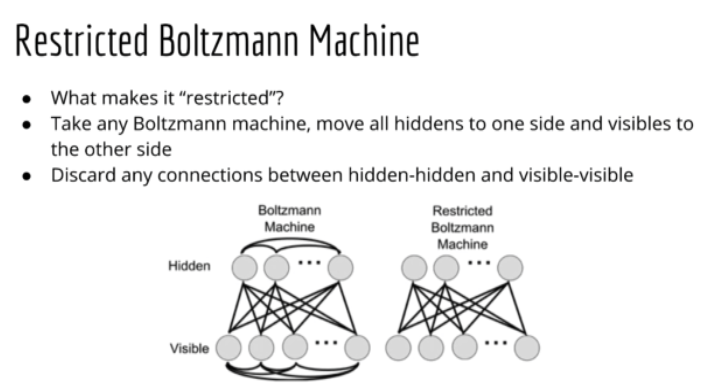
确实有点点难懂...
Others:
Explore-Exploit dilemma 概念: 比如,你在youtube上看视屏学炒鸡蛋,你看了很多视屏学会了炒鸡蛋,结果因为看的视屏多,在你学会了炒鸡蛋过后youtube还是老是给你推荐炒鸡蛋视屏,这就是explore-exploit dilemma, 数据越多结果越差.
Ref:
- [Udemy] Recommender Sytem and Deep Learning in Python
- https://github.com/mashuai191/machine_learning_examples/tree/master/recommenders
- 谷歌PageRank算法简单解释