PYTHON 补充知识点
面向对象三大特性:封装,继承和多态。
继承的意义在于两点:
第一,子类如若继承自父类,则自动获取父类所有功能,并且可以在此基础上再去添加自己独有的功能。
第二,当子类和父类存在同样方法时,子类的方法覆写了父类的代码,于是子类对象执行的将是子类的方法,即“多态”。
多态到底有什么用呢?在继承关系里,子类对象的数据类型也可以被当作父类的数据类型,但是反过来不行。那么当我们编写一个函数,参数需要传入某一个类型的对象时,我们根本不需要关心这个对象具体是哪个子类,统统按照基类来处理,而具体调用谁的重载函数,再具体根据对象确切类型来决定:
class Animal():
def get_name(self):
print("animal")
class Dog(Animal):
def get_name(self):
print("dog")
class Cat(Animal):
def get_name(self):
print("cat")
def run(animal): # 待执行的函数。
animal.get_name()
cat = Cat()
run(cat)
dog = Dog()
run(dog)
>>>cat
>>>dog
当我们再新增子类rabbit,wolf等时,根本不需要改变run函数。这就是著名的开闭原则:即对扩展开放(增加子类),对修改关闭(不需要改变依赖父类的函数参数)
多态存在的三个必要条件:继承,重写,父类引用指向子类对象。
对于静态语言来说,需要传入参数类型,那么实参则必须是该类型或者子类才可以。而对于动态语言(比如python)来说,甚至不需要非得如此,只需要这个类型里面有个get_name方法即可。这就是动态语言的鸭子特性:只要走路像鸭子,就认为它是鸭子!”这样的话,多态的实现甚至可以不要求继承。
装饰器的使用
装饰器的本质就是一个Python函数,它可以在其他函数不做任何代码变化的前提下增强额外功能。装饰器也返回一个函数对象。当我们想给很多函数额外添加功能,给每一个添加太麻烦时,就可以使用装饰器。
比如有几个函数想给它们添加一个“输出函数名称的功能”:
def test():
print("this is test")
print(test.__name__)
test()
但是如果还有其他函数也需要这个功能,那么就要每个都添加一个print,这样代码非常冗杂。这时候就可以使用装饰器。
def log(func):
def wrapper(*args,**kwargs):
print(func.__name__)
return func(*args,**kwargs)
return wrapper
@log # 装饰器
def test():
print("this is test")
test()
当把@log加到test的定义处时相当于执行了:
test = log(test)
于是乎再执行test()其实就wrapper(),可以得到原本函数的功能以及新添加的功能,非常方便。
还可以定义一个带参数的装饰器,这给装饰器带来了更大的灵活性:
def log(text):
def decorator(func):
def wrapper(*args, **kwargs):
print(text)
return func(*args, **kwargs)
return wrapper
return decorator
@log("ahahahahaha") # 带参数的装饰器
def test():
print("this is test")
这样就相当于执行了:
test = log("ahahahahaha")(test)
还有一点,虽然装饰器非常方便,但是这样使用会导致test的原信息丢失(比如上面的代码test.__name__会变成"wrapper"而不是"test")。这样的话需要导入一个functool包,然后在wrapper函数前面加上一句@functools.wraps(func)就可以了:
def log(text):
def decorator(func):
@functools.wraps(func) # 加上一句
def wrapper(*args, **kwargs):
print(text)
return func(*args, **kwargs)
return wrapper
return decorator
@log("ahahahahaha")
def test():
print("this is test")
最后,如果一个函数使用多个装饰器进行装饰的话,则需要根据逻辑确定装饰顺序。
Python中的多继承与MRO
Python是允许多继承的(即一个子类有多个父类)。多重继承的作用主要在于给子类拓展功能:比如dog和cat都是mamal类的子类,它们拥有mamal的功能,如果想给它们添加“runnable”的功能,只需要再继承一个类runnable即可。这个额外功能的类一般都会加一个“Mixin”后缀作为区分,表示这个类是拓展功能用的:
class Dog(mamal,RunableMixIn,CarnivorousMixIn)
pass
使用Mixin的好处在于不用设计复杂的继承关系即可拓展类的功能。
多继承会产生一个问题:如果同时有多个父类都实现了一个方法,那么子类应该调用谁的方法呢?这就涉及到MRO(方法解析顺序)。
在Python3之后,MRO使用的都是C3算法(不区分经典类和新式类,全部都是新式类)。C3算法首先使用深度优先算法,先左后右,得到搜索路径后,只保留“好的结点”。好的结点指的是:该节点之后没有任何节点继承自这个节点。
比如说下图:
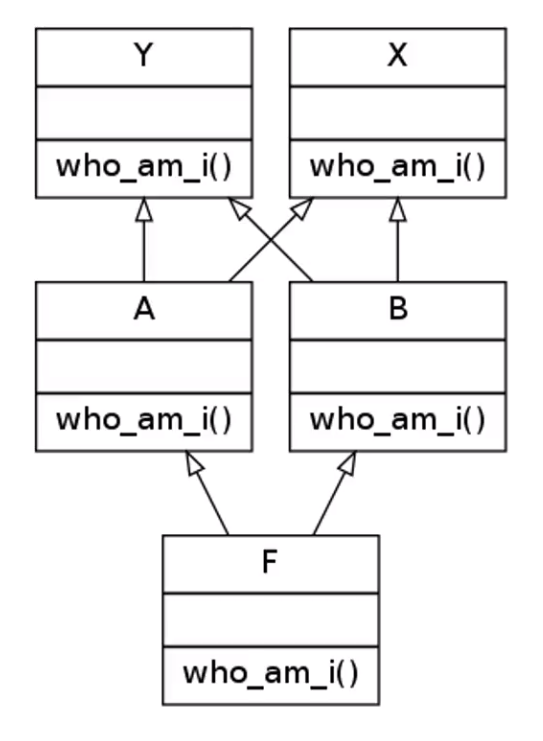
按照深度优先,从左至右的顺序应该是F,A,Y,X,B,Y,X。其中第一个Y和第一个X后面B也继承自Y,X,于是把它们去掉,最终路径是:F,A,B,Y,X
在MRO中,使用super方法也要注意:假设有类A,B,C,A继承自B和C。如果B中使用了Super重写了一个方法,这个方法会在C中去寻找(尽管C并不是B的父类):
class B:
def log(self):
print("log B")
def go(self):
print("go B")
super(B, self).go()
self.log()
class C:
def go(self):
print("go C")
class A(B, C):
def log(self):
print("log A")
super(A,self).log()
if __name__ == "__main__":
a = A()
# 1.a对象执行go,先找自己有没有go,自己没有按照MRO去找B
# 2.B中找到了go并执行,super顺位查找到c的go,执行。
# 3.然后执行self.log,因为self此时是A对象,于是首先找到A中的log函数执行
# 4.再次执行super函数,此时顺位查找到B,执行B.log
a.go()
"结果"
go B
go C
log A
log B
进程与线程
以前的单核CPU也可以进行多任务,方法是任务1一会儿,任务2一会儿,任务3一会儿......因为CPU速度很快,所以看起来像是执行了多任务,其实就是交替执行任务。
真正的并行需要在多核CPU上进行。但实际开发中的任务数量一定比核数量要多,所以每个核依旧是在交替执行任务。
进程:对于操作系统来说,一个任务就是一个“进程”,打开一个文件,程序等都是打开一个“进程”。
当一个程序在硬盘上运行起来,会在内存中形成一个独立的内存体,这个内存体中有自己独立的地址空间,有自己的堆。操作系统会以进程为最小的资源分配单位。
线程:线程是操作系统调度执行的最小单位。有时一个进程会有多个子任务:比如一个word文件它同时进行打字、编排、拼写检查等任务,这些子任务被称为“线程”。每个进程至少要有一个线程,和进程一样,真正的多线程只能依靠多核CPU来实现。
进程与线程的区别:进程是拥有资源的独立单位,线程不拥有系统资源,但可以访问自己所隶属的进程的资源。在系统开销方面,进程的创建与撤销都需要系统都要为之分配和回收资源,它的开销要比线程大。
多进程的优点是稳定性高,因为一个进程挂了,其他进程还可以继续工作。(主进程不能挂,但是由于主进程负责分配任务,所以挂的概率很低)。而线程呢,由于多线程共享一个进程的内存,所以一个线程挂了全体一起挂。并且多线程在操作共享资源时容易出错(死锁等问题)
一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程;
资源分配给进程,同一进程的所有线程共享该进程的所有资源;
处理机分给线程,即真正在处理机上运行的是线程;
线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步
无论是多进程还是多线程,一旦任务数量多了效率都会急剧下降,因为切换任务不仅仅是直接去执行就好了,这中间还需要保存现场、创建新环境等一系列操作,如果任务数量一多会有很多时间浪费在这些准备工作上面。
实现多任务主要有三种办法:
- 多个进程,每个进程仅有一个线程
- 一个进程,进程中有多个线程
- 多进程多线程(过于复杂,不推荐)
同时执行多个任务的时候,任务之间是要互相协调的,有时任务2必须要等任务1结束之后去执行,有时任务3和4不能同时执行......所以多进程和多线程编写架构要相对更复杂。
任务类型主要分为IO密集型和计算密集型”。计算密集型任务主要是需要大量计算,比如计算圆周率,对视频解码等。计算密集型任务主要消耗的是CPU资源(不适合Python这种运算效率低的脚本语言编写代码,适合C语言);而IO密集型任务主要是IO操作,CPU消耗很少,大部分时间都消耗在等待IO。(适合开发效率高的脚本语言)
对于计算密集型任务来说,如果多进程多线程任务远远大于核数,那么效率反而会急剧下降;而对于IO密集型任务来说,多进程多线程可能会好一些,但还是不够好。
利用异步IO可以实现单进程单线程执行多任务。利用异步IO可以显著提升操作系统的调度效率。对应到Python语言,异步IO被称为协程。
协程:比线程更加轻量级的“微线程”,协程不被操作系统内核管理,而是由用户自己执行。这样的好处就是极大的提升了调度效率,不会像线程那样切换浪费资源。
子程序在所有语言里都是层级调用(栈实现),即A调用B,B又调用C,C完了B完了最后A才能完。一个线程就是调用一个子程序。而协程不同,用户可以任意在执行A时暂停去执行B,过一会儿再来执行A。
协程的优势在于:由于是程序自己控制子程序切换,所以相比线程可以节省大量不必要的切换,对于IO密集型任务来说协程更优。而且不需要线程的锁机制。
协程是在单线程上执行的,那么如何利用多核CPU呢?方法就是多进程+协程。