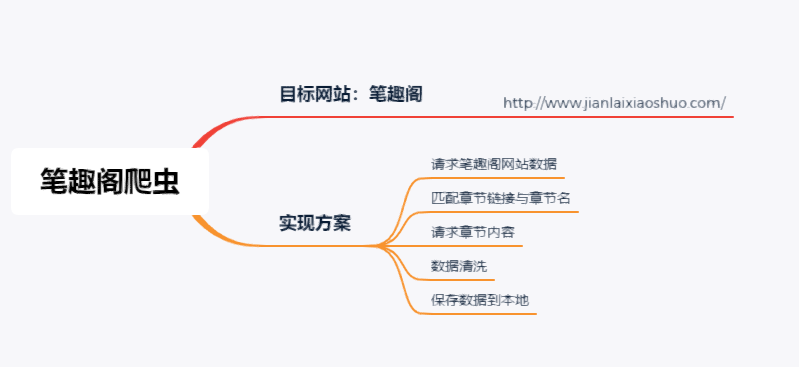
1、目的
爬取笔趣阁网站的剑来小说正文内容,并保存到本地中。

2、实现方案
首先,请求目标网站的网页数据,通过分析找出章节地址的特点,并通过xpath获取到章节链接;
其次,请求每一章节的内容,通过数据清洗去除脏数据,得到剑来文章正文;
最后,保存数据到本地。
3、程序设计
3.1 请求数据模块
请求模块,负责请求网站数据,主要使用requests的get方法获取网页内容。使用方法:request.get(url ,headers= headers) ,url表示请求的网络地址,headers表示请求头。请求到的网页数据需要指定格式读取,可以选择文本(text)格式,也可以选择content(二进制)格式。
#请求网页内容 def get_html(self,url): html =requests.get(url,headers=self.headers).content.decode() return html
3.2 解析网页模块
1、请求到目标网站的html源码,还需要从中找出你需要的数据,如章节url地址与章节名,因此需要使用正则表达式,或者xpath方法,解析数据获取到章节url地址,以及章节名。
下图是我使用xpath_help工具匹配到的章节名与章节url地址。


通过分析可以发现:章节名获取完整,url地址得到的只有一部分,通过查询每个章节的地址发现:每个章节的地址为爬取到的url地址+http://www.jianlaixiaoshuo.com,组成完整的章节地址,如 http://www.jianlaixiaoshuo.com/book/9.html。
2、获取到章节地址,然后需要请求每个章节的网页内容,并从中获取到正文数据。依然使用xpath_help工具,获取到正文数据。如下图:
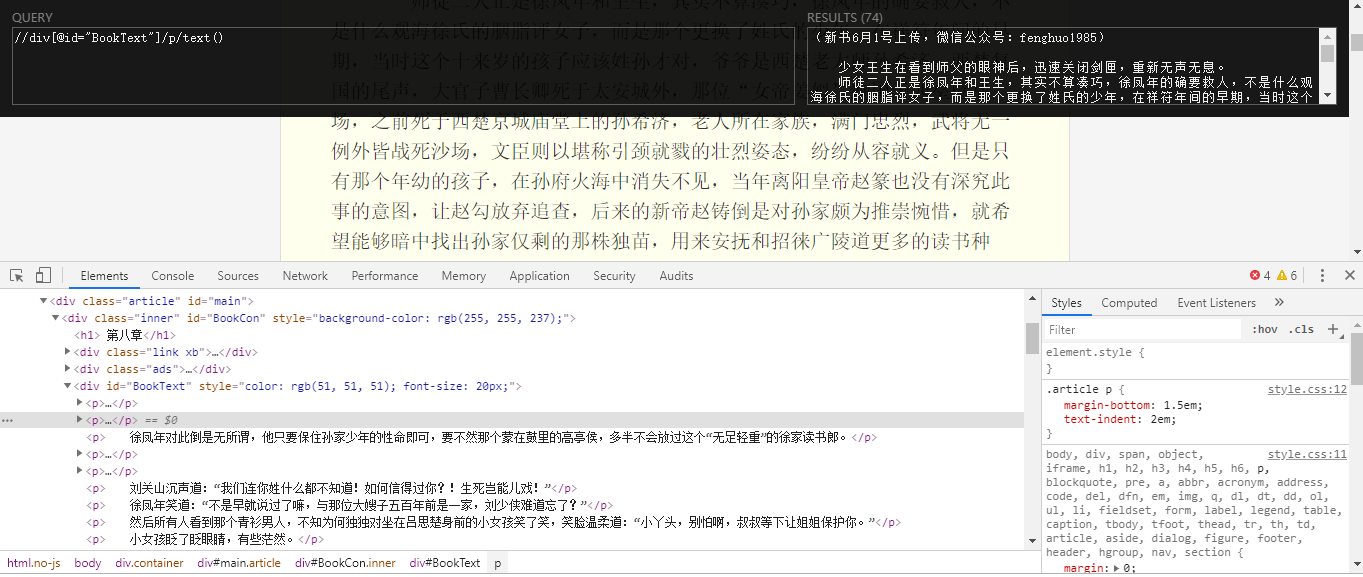
#下载数据 def down_load(self,url): html = self.get_html(self.url) # print(html) pattern1 = '//dl[@class="chapterlist"]/dd/a/@href' pattern2 = '//dl[@class="chapterlist"]/dd/a/text()' #获取每一章的链接地址 book_lists = self.get_xpath(html, pattern1) #获取每一章的章节名 book_name_lists = self.get_xpath(html, pattern2) print(book_lists) for book_name, url in zip(book_name_lists, book_lists): #完整的章节url地址 book_url = self.base_url + url book_html = self.get_html(book_url) #数据清洗 pattern = '//div[@id="BookText"]/p/text()' book_data = self.get_xpath(book_html, pattern) #将列表转换为str book_data = ''.join(book_data) book_data = book_data+' ' book_text = book_name+' '+book_data print('正在下载',book_name) print(book_text) # self.save_data(book_text)
3.3 保存数据
保存下载的数据,需要重复写入,因此设置写入格式为“a”,编码为‘utf-8“。
#保存数据 def save_data(self, data): with open('剑来.txt','a',encoding='utf-8')as f: f.write(data)
4、总程序代码:
# -*- coding: utf-8 -*- import requests from lxml import etree class BookSpider(object): def __init__(self): self.url = "http://www.jianlaixiaoshuo.com/" self.base_url = "http://www.jianlaixiaoshuo.com/" self.headers = { "Use_Agent": "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"} #请求网页内容 def get_html(self,url): html = requests.get(url,headers = self.headers).content.decode() return html #封装xpath def get_xpath(self,html,pattern): p = etree.HTML(html) result = p.xpath(pattern) return result #保存数据 def save_data(self, data): with open('剑来.txt','a',encoding='utf-8')as f: f.write(data) #下载数据 def down_load(self,url): html = self.get_html(self.url) # print(html) pattern1 = '//dl[@class="chapterlist"]/dd/a/@href' pattern2 = '//dl[@class="chapterlist"]/dd/a/text()' #获取每一章的链接地址 book_lists = self.get_xpath(html, pattern1) #获取每一章的章节名 book_name_lists = self.get_xpath(html, pattern2) print(book_lists) for book_name, url in zip(book_name_lists, book_lists): #完整的章节url地址 book_url = self.base_url + url book_html = self.get_html(book_url) #数据清洗 pattern = '//div[@id="BookText"]/p/text()' book_data = self.get_xpath(book_html, pattern) #将列表转换为str book_data = ''.join(book_data) book_data = book_data+' ' book_text = book_name+' '+book_data print('正在下载',book_name) print(book_text) # self.save_data(book_text) #运行程序 def run(self): self.down_load(self.url) if __name__ == "__main__": p = BookSpider() p.run()