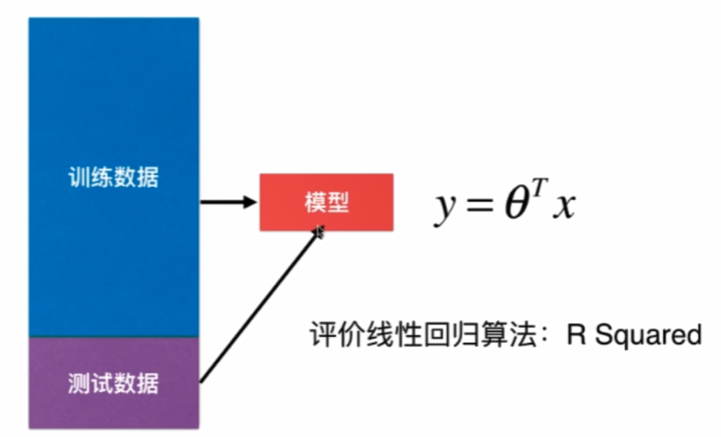
简单线性回归与最小二乘法
解决回归问题,思想简单、实现容易,许多强大的非线性模型的基础,结果具有很好的可解释性,蕴含机器学习的很多重要思想。
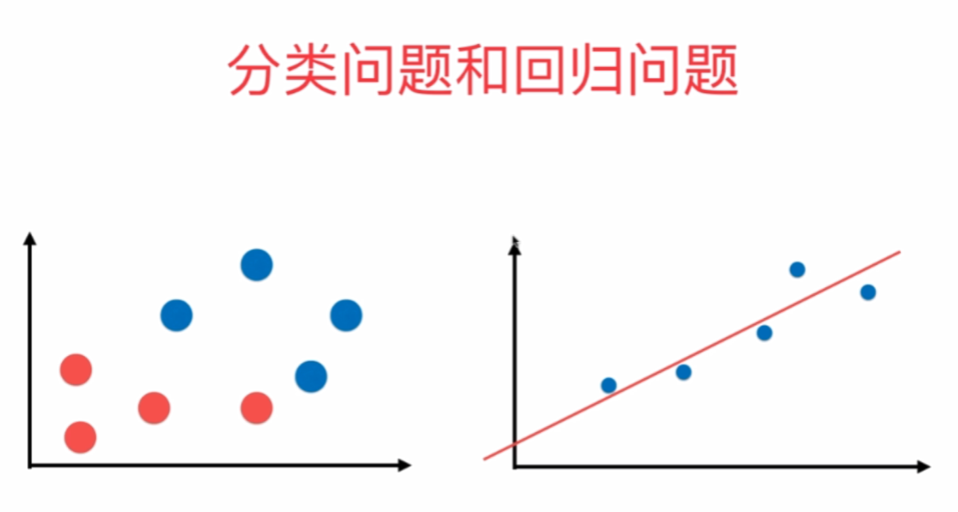
回归问题的横轴为特征,纵轴为输出标记,分类问题的横纵轴均为特征,颜色为输出标记。
样本特征只有一个称为简单线性回归。

因为y=|x|不是处处可导,所以我们不选择取绝对值计算差距,而是取差值的平方。
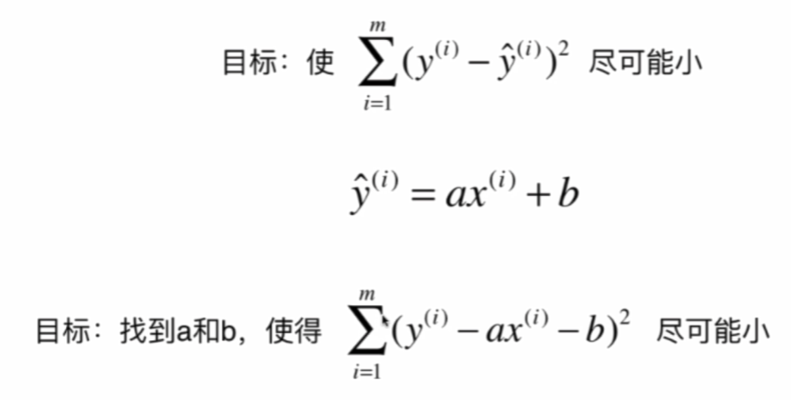
一类机器学习算法的基本思路:

近乎所有参数学习算法都是这样的套路,如线性回归、多项式回归、逻辑回归、SVM、神经网络……
这里是典型的最小二乘法问题:最小化误差的平方
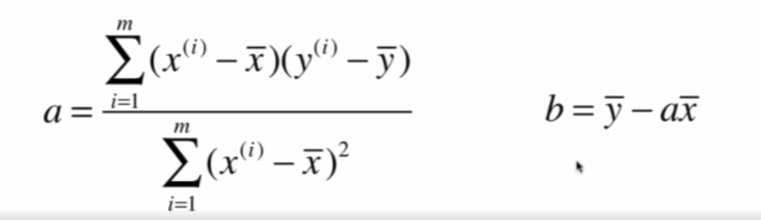
推导过程:
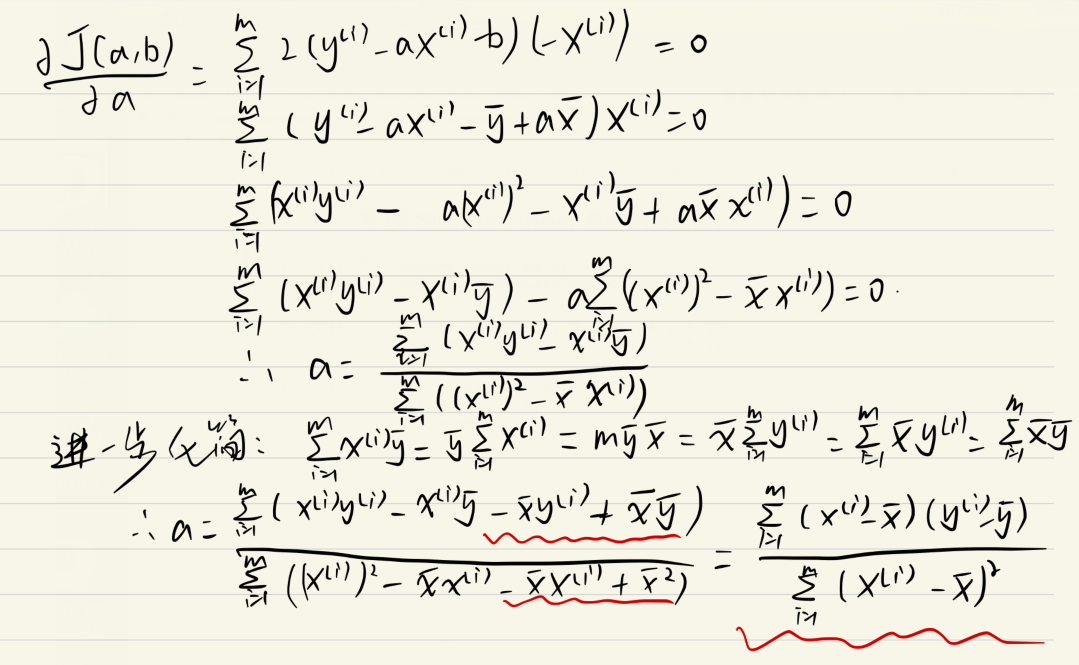
简单线性回归类写法
import numpy as np
class SimpleLinearRegression1:
def __init__(self):
"""初始化Simple Linear Regression 模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train,y_train训练Simple Linear Regression模型"""
assert x_train.ndim == 1,
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train),
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
for x, y in zip(x_train, y_train):
num += (x - x_mean) * (y - y_mean)
d += (x - x_mean) ** 2
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回表示x_predict的结果向量"""
assert x_predict.ndim == 1,
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None,
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x,返回x的预测结果值"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression1()"
向量化
numpy里的向量运算是比用for循环效率高很多的,容易看出上面化简的a和b的式子都可以表示成∑wi*vi,而这其实就是两个向量的点积,所以优化后的类写法:
class SimpleLinearRegression2:
def __init__(self):
"""初始化Simple Linear Regression模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train,y_train训练Simple Linear Regression模型"""
assert x_train.ndim == 1,
"Simple Linear Regressor can only solve single feature training data."
assert len(x_train) == len(y_train),
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
self.a_ = (x_train - x_mean).dot(y_train - y_mean) / (x_train - x_mean).dot(x_train - x_mean)
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待预测数据集x_predict,返回表示x_predict的结果向量"""
assert x_predict.ndim == 1,
"Simple Linear Regressor can only solve single feature training data."
assert self.a_ is not None and self.b_ is not None,
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict])
def _predict(self, x_single):
"""给定单个待预测数据x_single,返回x_single的预测结果值"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "SimpleLinearRegression2()"
衡量线性回归的标准
均方误差MSE(mean squared error)

均方根误差RMSE(root mean squared error)
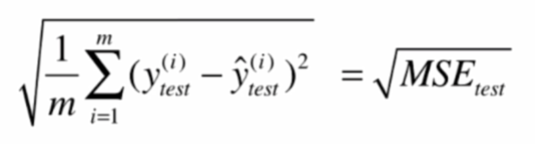
平均绝对误差MAE(mean absolute error)
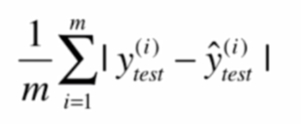
代码
以下代码均是在jupyter notebook中运行
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston=datasets.load_boston()
x=boston.data[:,5] #只使用房间数量RM这个特征
y=boston.target
plt.scatter(x,y)
plt.show()
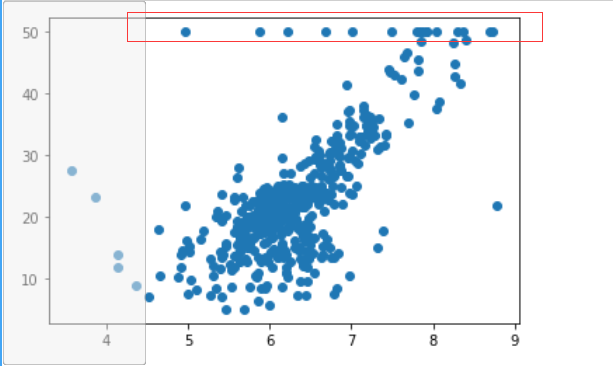
可以发现最上面的一些点很奇怪,所有大于的可能都被写成了50,可能计量仪器有最大值(或者问卷填写时大于50的都写成50了),所以我们要把y>50的点去掉。
x=x[y<50]
y=y[y<50]
plt.scatter(x,y)
plt.show()

这样才是正确的。
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=666)
%run F:python3玩转机器学习线性回归SimpleLinearRegression.py
reg = SimpleLinearRegression2()
reg.fit(x_train,y_train)
reg.a_
reg.b_
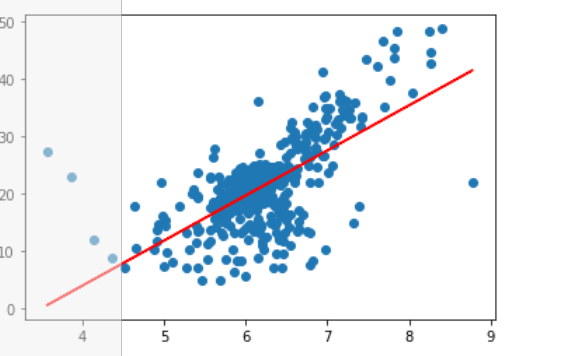
plt.scatter(x_train,y_train)
plt.plot(x_train,reg.predict(x_train),color="r")
plt.show()
y_predict=reg.predict(x_test)
mse_test=np.sum((y_predict-y_test)**2)/len(y_test)
mse_test
from math import sqrt
rmse_test=sqrt(mse_test)
rmse_test
mae_test=np.sum(np.absolute(y_predict-y_test))/len(y_test)
mae_test
sklearn中的mse和mae:
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
#没有rmse,需要自己手动开根
mean_squared_error(y_test,y_predict)
mean_absolute_error(y_test,y_predict)
可以发现mae比rmse要小一点,但他们的量纲都是一样的(和y单位相同),这是因为rmse中的平方会把较大的误差放大,而mae不会。所以我们尽量让rmse尽可能小才是有意义的。
R Squared
分类的准确度最好为1,最差为0,而rmse和mae都不能满足。

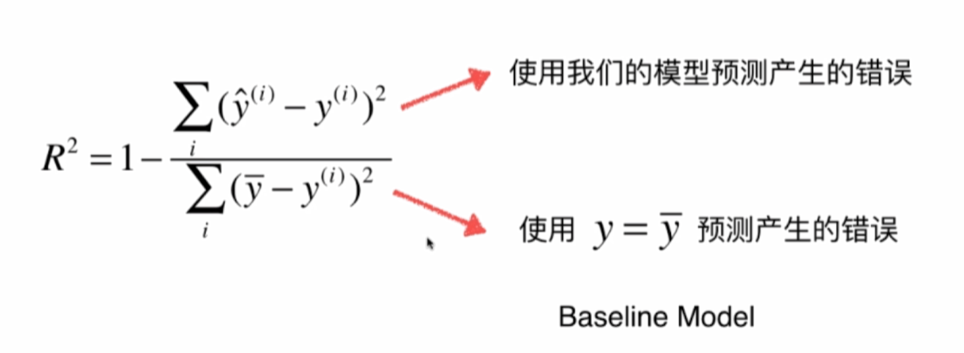

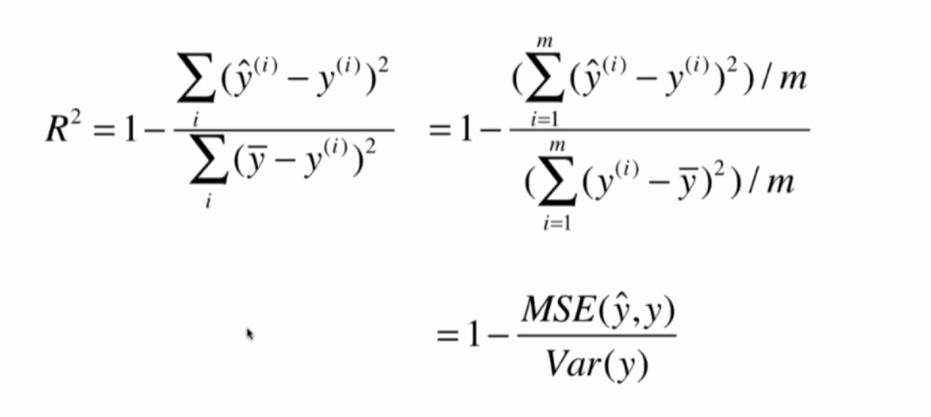
代码:
1-mean_squared_error(y_test,y_predict)/np.var(y_test)
封装成函数
def mean_squared_error(y_true, y_predict):
"""计算y_true和y_predict之间的MSE"""
assert len(y_true) == len(y_predict),
"the size of y_true must be equal to the size of y_predict"
return np.sum((y_true - y_predict)**2) / len(y_true)
def root_mean_squared_error(y_true, y_predict):
"""计算y_true和y_predict之间的RMSE"""
return sqrt(mean_squared_error(y_true, y_predict))
def mean_absolute_error(y_true, y_predict):
"""计算y_true和y_predict之间的MAE"""
assert len(y_true) == len(y_predict),
"the size of y_true must be equal to the size of y_predict"
return np.sum(np.absolute(y_true - y_predict)) / len(y_true)
def r2_score(y_true, y_predict):
"""计算y_true和y_predict之间的R Square"""
return 1 - mean_squared_error(y_true, y_predict)/np.var(y_true)
多元线性回归和正规方程解
多元线性回归:
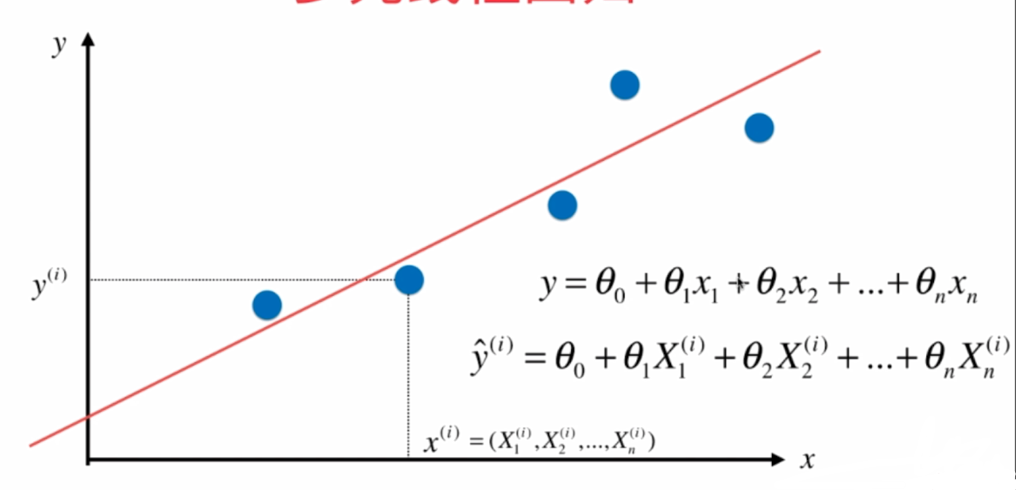
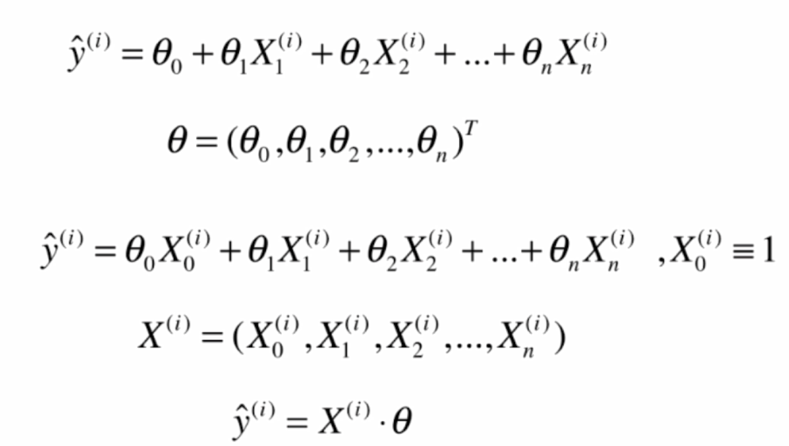

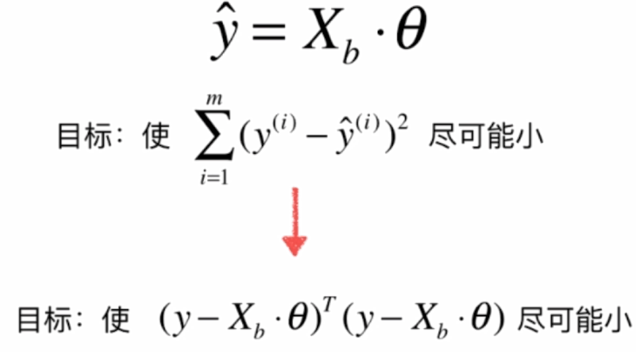


正规方程推导:https://blog.csdn.net/zoe9698/article/details/82419330
线性回归类:
import numpy as np
from sklearn.metrics import r2_score
class LinearRegression:
def __init__(self):
"""初始化Linear Regression模型"""
self.coef_ = None #系数
self.intercept_ = None #截距
self._theta = None
def fit_normal(self, X_train, y_train):
"""根据训练数据集X_train, y_train训练Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0],
"the size of X_train must be equal to the size of y_train"
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train)
self.intercept_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self.intercept_ is not None and self.coef_ is not None,
"must fit before predict!"
assert X_predict.shape[1] == len(self.coef_),
"the feature number of X_predict must be equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return X_b.dot(self._theta)
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return r2_score(y_test, y_predict)
def __repr__(self):
return "LinearRegression()"
%run f:python3玩转机器学习线性回归LinearRegression.py
boston=datasets.load_boston()
X=boston.data #全部特征
y=boston.target
X=X[y<50]
y=y[y<50]
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=666)
reg=LinearRegression()
reg.fit_normal(X_train,y_train)
reg.coef_
reg.intercept_
reg.score(X_test,y_test)
scikit-learn中的线性回归
from sklearn.linear_model import LinearRegression
lin_reg=LinearRegression()
lin_reg.fit(X_train,y_train)
lin_reg.intercept_
lin_reg.coef_
lin_reg.score(X_test,y_test)
KNN Regressor
from sklearn.neighbors import KNeighborsRegressor
knn_reg=KNeighborsRegressor()
knn_reg.fit(X_train,y_train)
knn_reg.score(X_test,y_test)
#网格搜索最优参数
param_grid =[
{
'weights':['uniform'],
'n_neighbors':[i for i in range(1,11)],
},
{
'weights':['distance'],
'n_neighbors':[i for i in range(1,11)],
'p':[i for i in range(1,6)]
}]
knn_reg=KNeighborsRegressor()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(knn_reg,param_grid)
grid_search.fit(X_train,y_train)
grid_search.best_params_
grid_search.best_score_ #此方法不能用,因为评价标准和前面不同,采用了CV
grid_search.best_estimator_.score(X_test,y_test) #这样才是真正的和前面相同的评价标准
线性回归的可解释性
boston=datasets.load_boston()
X=boston.data #全部特征
y=boston.target
X=X[y<50]
y=y[y<50]
from sklearn.linear_model import LinearRegression
lin_reg=LinearRegression()
lin_reg.fit(X,y)
lin_reg.coef_
np.argsort(lin_reg.coef_)
boston.feature_names[np.argsort(lin_reg.coef_)]
可以发现对系数按从小到大对下标排序后,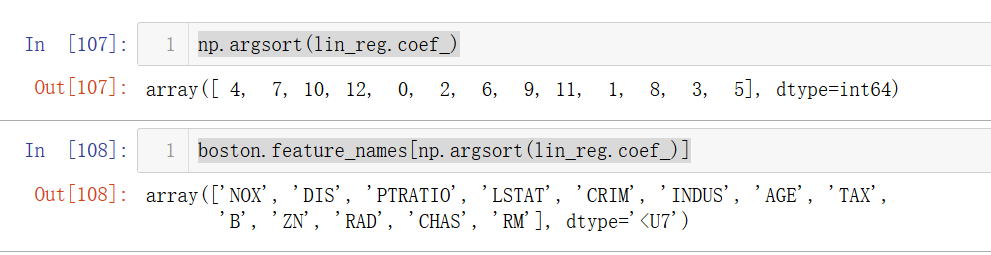
查看DESC里面对特征的描述,可以发现房价和RM(房间数量)、CHAS(是否靠河)等等成正相关,和NOX(一氧化碳浓度)等成负相关。
线性回归总结