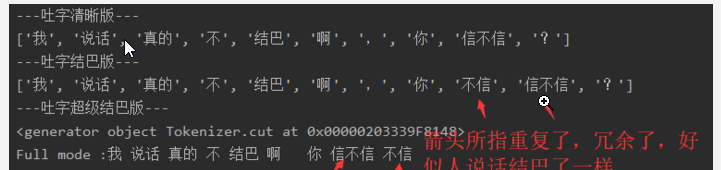
# jieba库概述 .jieba是优秀的中文分词第三方库。需要额外安装。 pip install jieba # jieba库三种分词模式 精确模式:把文本精确的切分开,不存在冗余单词。 全模式:把文本中所有可能的词语都扫描出来,有冗余。 搜素引擎模式:在精确模式基础上,对长词再次切分。 # jieba库常用函数 jieba.cut(s) 精确模式,返回一个可迭代的数据类型 jieba.cut(s,cut_all=True) 全模式,输出文本S中所有可能单词 jieba.cut_for_search(s) 搜素引擎模式,适合搜素引擎建立索引的分词结果 jieba.lcut(s) 精确模式,返回一个列表类型,建议使用 jieba.lcut(s,cut_all=true) 全模式,返回一个列表类型,建议使用 jieba.lcut_for_search(s) 搜素引擎模式,返回一个列表类型,建议使用 jieba.add_word(w) 向分词词典中增加新词w # jieba实例 ```python import jieba txt_1 = "我说话真的不结巴啊,你信不信?" res = jieba.lcut(txt_1) #精确模式,返回一个列表类型,其中参数txt是表示文本的名字,吐字清晰版。 print('吐字清晰版') print(res) res_1 = jieba._lcut_for_search(txt_1)#搜素引擎模式,返回一个列表类型,其中参数txt是表示文本的名字,吐字结巴版 print('吐字结巴版') print(res_1) res_2 = jieba.cut(txt_1.cut_all = True) print('吐字超级结巴版') print(res_2) #可以看到返回了一个生成器 fullmode = 'full mode:'+''.join(res_2) #全模式(不能解决歧义) print(fullmode) ```