hive -- 自定义函数和Transform
UDF操作单行数据,
UDAF:聚合函数,接受多行数据,并产生一个输出数据行
UDTF:操作单个数据
使用udf方法:
第一种:
add jar xxx.jar
cteate temporary function 方法名;
注销一个jar方法:drop temporay function 方法名;
第二种:写一个脚本
vi cat hive_init
add jar /home/data/xxx.jar
create temporary fucntion 方法名 as '类的全限定名'
hive -i hive_init
第三种:
自定义UDF注册为hive的内置函数
自定义函数:(UDF)
数据:
package UDF;
import java.util.HashMap;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
*
* @author huhu_k
*
*/
public class ToLowerCase extends UDF {
public static HashMap<String, String> provinceMap = new HashMap<>();
static {
provinceMap.put("136", "beijing");
provinceMap.put("137", "shanghai");
provinceMap.put("138", "shenzhen");
}
// 必须是public
public String evaluate(String field) {
String lowerCase = field.toLowerCase();
return lowerCase;
}
// 必须是public
public String evaluate(int field) {
String pn = String.valueOf(field);
return provinceMap.get(pn.substring(0, 3)) == null ? "huoxing" : provinceMap.get(pn.substring(0, 3));
}
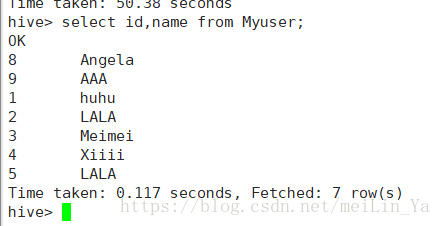
}1.将name大写变为小写:
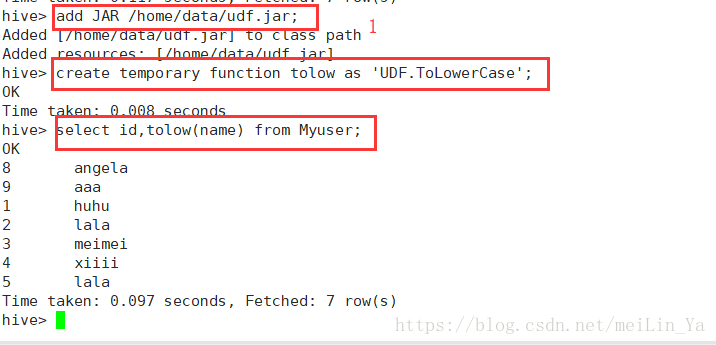
2.数据:

通过手机号获取手机地址:
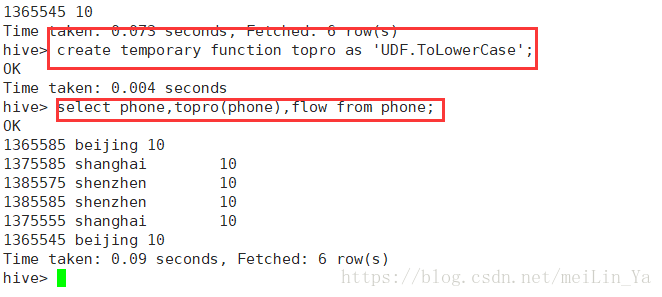
当你在一个类中再次写了方法时,再次导入jar时,要先推出hive,然后在进入hive,然后进行add JAR XXXXX;
3.数据:
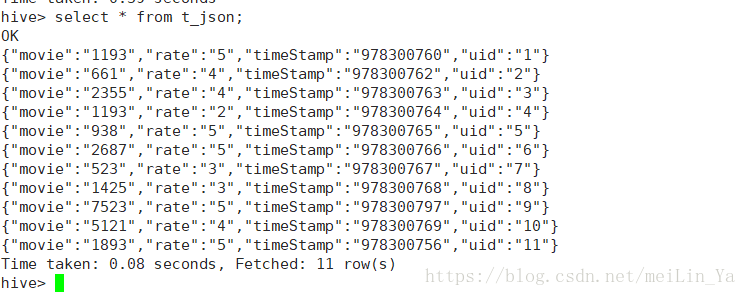
使用json数据
package UDF;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.codehaus.jackson.map.ObjectMapper;
public class JsonParser extends UDF {
public String evaluate(String json) {
ObjectMapper objectMapper = new ObjectMapper();
try {
Moive readValue = objectMapper.readValue(json, Moive.class);
return readValue.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
package UDF;
public class Moive {
private String movie;
private String rate;
private String timeStamp;
private String uid;
public String getMovie() {
return movie;
}
public void setMovie(String movie) {
this.movie = movie;
}
public String getRate() {
return rate;
}
public void setRate(String rate) {
this.rate = rate;
}
public String getTimeStamp() {
return timeStamp;
}
public void setTimeStamp(String timeStamp) {
this.timeStamp = timeStamp;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
@Override
public String toString() {
return movie + " " + rate + " " + timeStamp + " " + uid;
}
}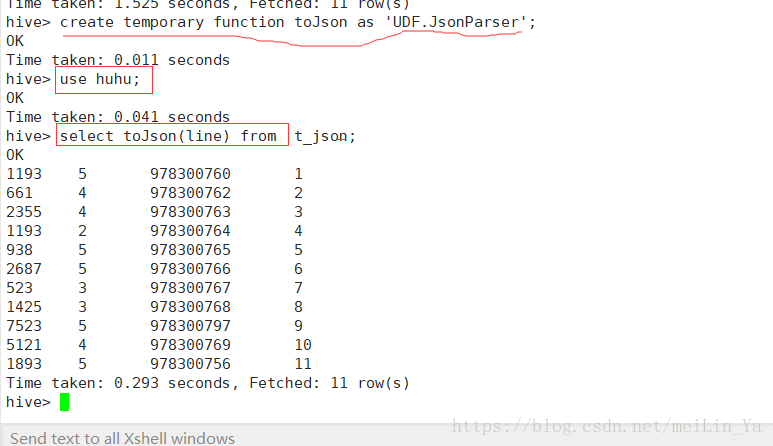
然后将查询出来的数据插入到一张表中
1.使用hive中的自带函数可以解析简单的json数据格式
create table t_json2 as select get_json_object(line,'$.movie')as movie,get_json_object(line,'$.rate')as rate,get_json_object(line,'$.timeStamp')as timeStamps,get_json_object(line,'$.uid')as uid from t_json;
2.使用自定义函数
create table t_json1 as select split(toJson(line),' ')[0]as movieid,split(toJson(line),' ')[1]as,split(toJson(line),' ')[2]as timestring,split(toJson(line),' ')[3]as uid from t_json;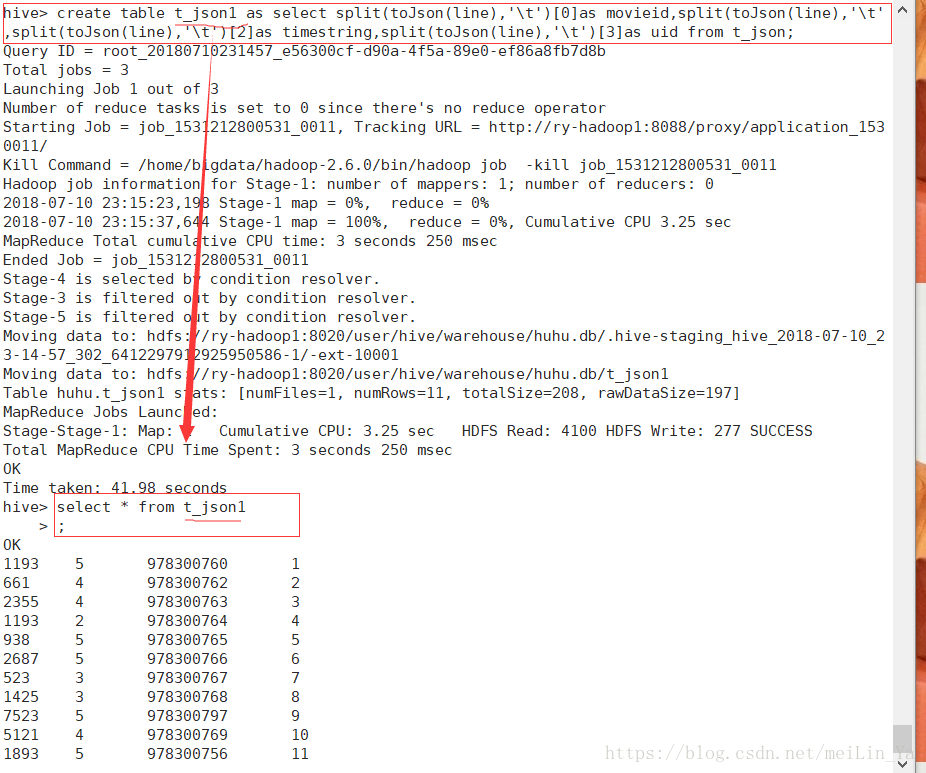
ok!!!
Transform:
Hive的Transform关键字提供了在SQL中调用自写脚本的功能
例子:
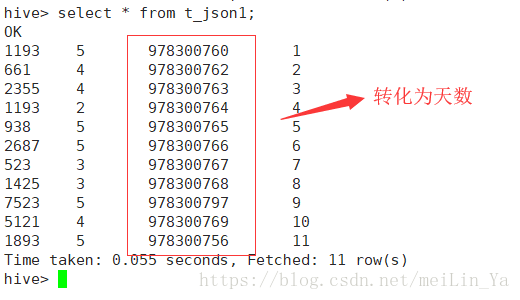
先编辑一个python脚本文件
#!/bin/python
import sys
import datetime
for line in sys.stdin:
line = line.strip()
movieid, rating, unixtime,userid = line.split(' ')
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print ' '.join([movieid, rating, str(weekday),userid])将文件加入hive的路径classpath
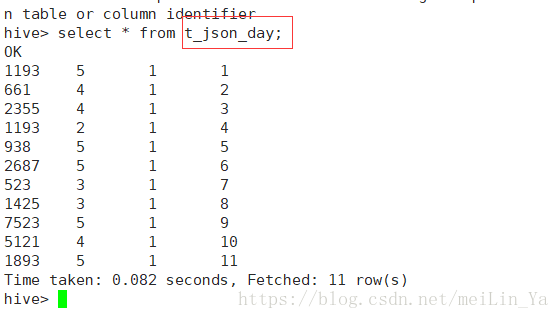
add file /home/data/weekday_mapper.py;创建一个表:
create table t_json_day as select transform (movieid,rate,timestring,uid) using 'python weekday_mapper.py' as (movieid,rate,weekday,uid) from t_json1;