机器学习技术的实施方法
特征处理
特征工程的重要性
需要同时掌握理论方法和业务逻辑才能提取有效的特征;
在特征方面拥有最大的自主性和探索性;
指征能力, 该特征的大小变化对最终结果的大小变化会在什么方向起到多大的作用;
用户ID类特征
ID特征, 指为每个用户分配一个唯一ID, 将这组唯一ID作为一组 One-Hot 特征, 每个用户在这组特征中只有一个特征; 具有个性化程度最强;
学习到一个用户整体的点击偏好, 承担学习全局偏置的功能;
将用户ID与物品侧的非ID类特征交叉组合, user_id+user_id×item_attribute;
历史记忆性强, 未来扩展能力差;
行为 ID 类特征
从根本上替换掉用户ID这个具有历史记忆属性的核心元素, 将其替换为可以代表一个用户, 同时还具有扩展性的其他信息, 降维;
有过某个行为的用户对于当前物品的点击概率;
对于用户有过行为的物品 hitory_item 和待预测的物品 current_item 组合特征;
ID 类特征的降维
大规模 ID 类特征, 非常细粒度的描述方法, 对于用户和物品之间的喜好关系有非常强的捕捉能力, 但也有局限性:
-
样本量要求大;
样本量是特征量的 10 倍;
-
数量庞大, 实现要求高;
-
数据稀疏性;
-
特征泛化能力差;
ID 类特征在 bias-variance(偏差-方差)的权衡中选择了偏差较低的一端;
-
模型信息总结提炼难度大;
将用户, 物品的 ID 用更低维, 更稠密的信息来表示;
例如: 用户ID => 属性(性别或年龄), 标签(喜好类别和标签)等;
高维特征(ID 类)用来增强行为丰富的用户的细致体验;
低维特征用来覆盖行为不足的用户和物品;
交叉特征的优选
构造交叉特征有两种方式:
-
笛卡尔积方式
用户特征A和物品特征B中各个特征相互组合成一个特征;
特征量大, 描述能力强; 但工程方面要求高, 压力大;
-
交集方式
用户特征A和物品特征B中通过设置条件进行组合特征;
特征量减少, 性价比更高;
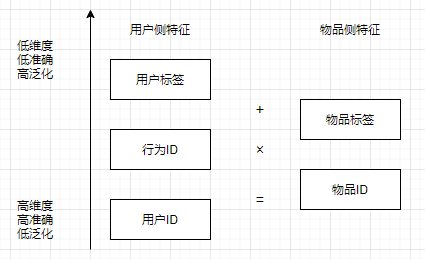
- +: 特征不做交叉, 单独使用
- ×: 笛卡尔积特征交叉;
- =: 交集特征交叉;
常用特征工程方法
-
快速构建基线版本特征(指导原则)
机器学习系统的 MVP(Minimal Viable Product, 最小可行产品, 可满足某一个功能的最简单产品形态)原则: 首先构建整个系统的所有组件和 pipeline, 跑通流程, 然后在这个 pipeline 上进行细致的优化;
-
业务规则特征化
系统中存在的, 参与到与模型决策相同目标中的业务规则, 尽量将其特征化, 尤其是复杂的规则;
-
数值特征缩放(scaling)
取值范围差异较大的数值特征, 将它们的取值映射到同一个范围内([0,1]或[-1,1]);
缩放的好处:
- 提高计算稳定性
- 提高收敛速度
- 提高模型的可解释性
缩放的方法:
-
单位长度缩放
(x_{scaled} = frac{x}{||x||_2}), (||x||_2) 表示特征向量的 L2 Norm;
整个向量长度为 1, 适合特征向量全部或大部分为数值类型
-
标准化
(x_{scaled} = frac{x-overline{x}}{sigma}), (overline{x}) 特征的样本均值, (sigma) 特征的样本标准差;
特征值具有 0 的均值和单位方差;
-
最小最大缩放
(x_{scaled} = frac{x-x_{min}}{x_{max}-x_{min}}),
将原始值映射到 0~1, 同时保持原始的线性关系;
-
百分比化
(x_{scaled} = frac{Sigma I(x_i<x)}{N}), N 为样本总量;
将原始取值变换为该取值在全局取值中的百分位取值;
缩放比前面几种更稳定, 不用特殊处理异常值; 但只保留了排序信息, 去除了具体的数值信息;
-
特征离散化
将一个数值特征根据取值映射到多个离散值上, 最常用的是 One-Hot 编码技术;
离散化的目的: 引入更多的非线性因素, 使模型具有更强的拟合能力;
最核心的问题: 如何决定离散化的映射区间:
-
离散化到多少个区间
经验值;
-
如何决定离散化的分界点
- 等宽, 将区间均匀划分
- 等频, 划分后每个区间的样本数量相等;
- 决策树, 将该特征作为决策树的唯一特征进行训练;
-
-
组合特征的使用
能够引入非组合特征无法描述的信息;
需要注意问题:
- 如果使用A和B的组合特征, A和B本身也要包含在模型中;
- 组合特征需要有可解释的意义;
-
特征稀疏性处理
某个特征只能覆盖少量样本的情况;
出现原因:
- 数据缺失导致;
- 引入类别特征以及大量组合特征导致;
关注特征的显著性和置信区间, 与特征对应的样本量有直接关系;
好特征的特点:
- 每个特征只适用于小部分数据, 但绝对数量不会特别少;
- 整体覆盖率较高, 例如超过90%;
特征的高纬度, 带来两个问题:
- 对模型效果的影响, 维度灾难(curse of dimensionality);
- 对训练性能, 预测性能, 存储量等的影响;
解决方法:
-
借助正则化等训练技术消除一些无用的特征, 减少整体特征量;
-
降维处理
-
基于业务的降维, 例如聚合类
缺点:
- 很多场景下没有明显可用于聚合特征的业务规则;
- 即使有, 聚合能力也有限或不灵活;
- 业务给出的聚合方法不一定能完全捕捉到数据中存在的关系信息, 比如两个不同类之间的关系;
-
基于算法的降维
- PCA
- LDA
- SVD, embeding
-
-
处理位置偏差(position bias)
点击率, 转化率等特征容易受影响;
常用做法: 计算出每个位置 i 上的平均点击率 (ctr_i), 在统计点击数时, 将原本会被计算为 1 的每次点击统计为 (1/ctr_i), 再计算对应的点击率;
对展现位置优越的物品进行惩罚, 对位置不好的物品进行补偿;
-
特征效果查看
在模型训练完成之后进行特征效果查看, 目的有三:
- 查看重要性最高的特征, 是否符合预期, 是否出现意料之外的特征;
- 业务判断的预期重要性高的特征, 是否真的得到了高的重要性;
- 哪些特征有用, 及其意义和目的;
深度学习模型中的特征工程
前向神经网络, 多层感知机(Multi Layer Perceptron, MLP), 重要点在于表征学习和特征降维, 可以提升模型的泛化能力;
特征工程的实现
特征系统要能够同时服务于探索开发, 例行训练和线上预测;
- 探索开发, 需要特征灵活, 快速生成;
- 例行训练, 特征取值正确;
- 线上预测, 特征取值与离线一致;
解决特征和样本的时间对齐问题;
- 长期相对保持固定的特征;
- 对时效比较敏感的短期特征;
解决方法:
- 样本产生时, 立刻计算时效性特征并记录到日志中, 采用 Spark 或 Flink 等实时计算框架;
- 构造服务, 例如用户浏览历史服务, 购买历史服务等;
- 与实时请求记录的日志相结合;
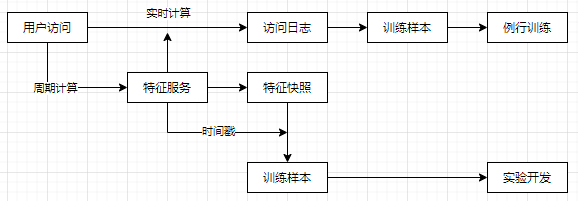
- 例行训练流程中, 尽量实时记录特征, 包括统计类特征和状态类特征, 解决时间对齐问题;
- 实验开发流程中, 定期保存特征的快照, 得到最高的迭代效率;
- 实验开发和例行训练, 采用同一套特征服务(特征生成器), 达到线上线下统一;
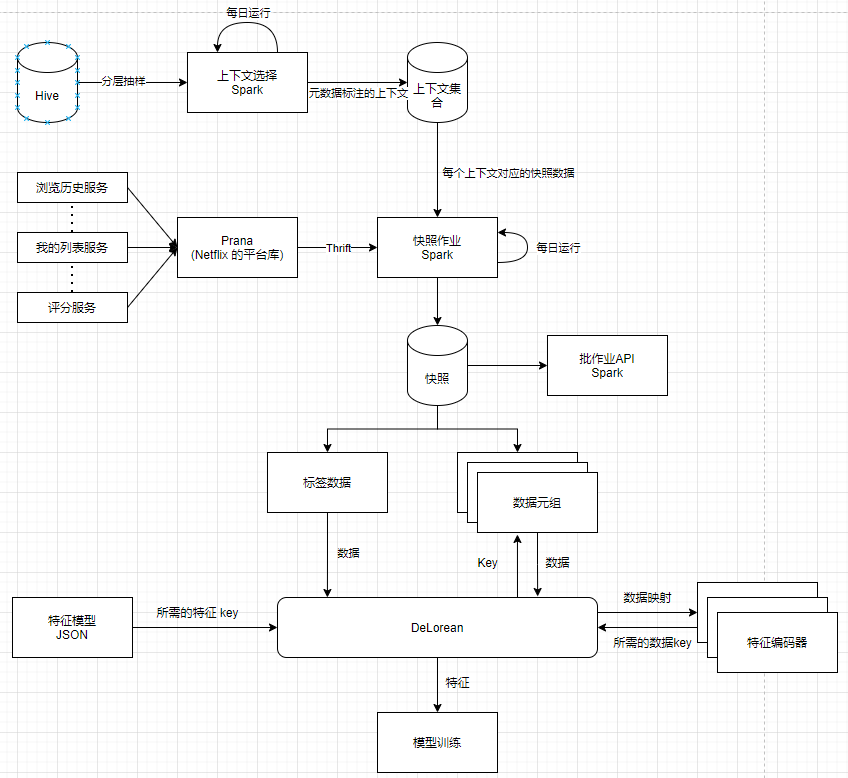
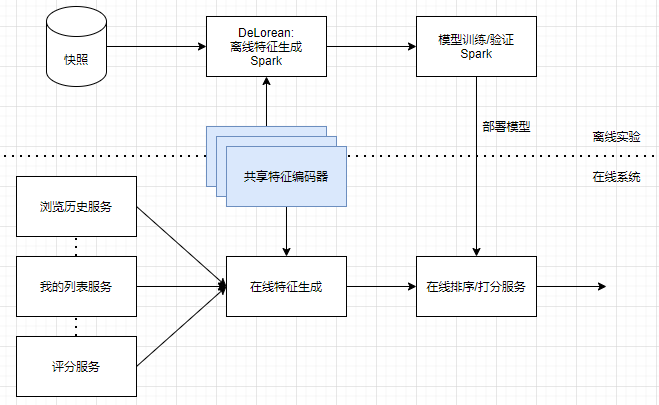
Netflix 特征系统的时间机器:
- 定期运行作业生成特征快照;
- 通过快照系统按需生成特征的 DeLorean 模块;
-
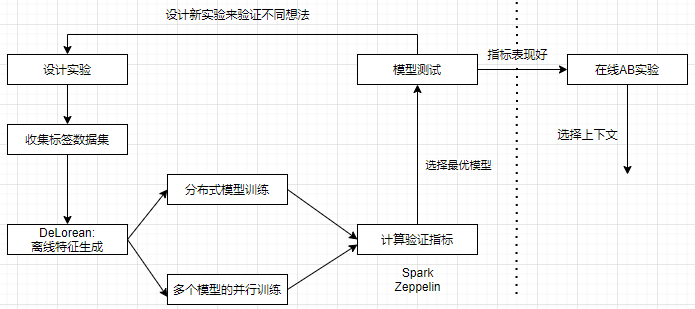
使用 DeLorean 模块进行实验开发;
-
使用 DeLorean 模块结合实时特征记录的方法进行模型部署和线上调用;
样本是通过指定上下文生成, 使用分层抽样(stratified sampling)保证样本具有代表性;
DeLorean 模块: 根据配置信息自动生成所需要的特征;
需要提供:
- 生成样本对应的上下文;
- 含特征编码器的特征模型;
- 库中未包含的新特征的生成方式;
共享特征编码器, 该编码器在离线开发和在线预测中共享;
模型选择与训练
-
搞清楚当前整个系统中投入产出比最高的事情;
第一版系统务必要快速且有效;
-
考虑系统的预期承载能力和性能要求;
系统上线后单位时间内需要处理的请求数; 实时处理的性能要求在100ms一下;
-
评估模型可解释性的重要性;
预测过程和原理可否向非专业人士用通俗语言进行解释;
-
评估可用的训练数据量和可承载的特征量;
训练工具选择:
- 单机工具, liblinear, XGBoost
- 分布式工具, SparkMLlib, 分布式 XGBoost
模型效果评估
- 模型本身评估
准确率(precision), 在召回的文档中应该召回的文档占到的比例;
召回率(recall), 召回的相关文档占全部相关文档的比例;
F值, 准确率和召回率的一个权衡融合;
AUC(Area Under Curve), ROC 曲线下面积;
- (f(x)) 预测函数对于样本 x 计算出的它属于正样本的预测值;
- (x^+), (x^-) 代表正负样本;
- c 代表分类阈值;
离散公式:
- M, N 正样本和负样本的数量;
- (rank_{x_i}) 将所有样本按照预测值从大到小排序后 (x_i) 的排序位置;
- AUC 适合衡量模型排序的效果;
- 电商推荐 AUC 平均到 0.7-0.8, 外卖团购平均到 0.9;
NE(Normalized Entropy)
- 从损失函数优化本身对模型进行评估
- log loss 交叉熵损失
- N 样本数量, (y_i) 是预测值{+1, -1}, (p_i) 是预测为 +1 的概率;
- 当 (y_i=1) 时, 即样本为正, (p_i) 接近 1 越好; 当 (y_i=-1) 时, 样本为负, (p_i) 接近 0 越好;
- 分母选择整体 CTR 的信息熵做归一化处理, 消除训练数据样本分布不均衡的影响;
校准度(Calibration)
衡量模型预测值与真实值之间在整体数值规模上的差异;
- 模型对系统产生的影响的评估
- AB 实验
- 交叉实验
