展示如何将数据输入到计算图中
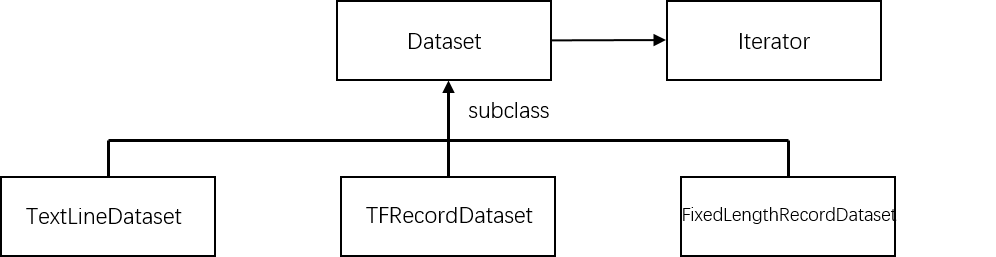
Dataset可以看作是相同类型“元素”的有序列表,在实际使用时,单个元素可以是向量、字符串、图片甚至是tuple或dict。
数据集对象实例化:
dataset=tf.data.Dataset.from_tensor_slice(<data>)
迭代器对象实例化:
iterator=dataset.make_one_shot_iterator()
one_element=iterator.get_next()
读取结束异常:如果一个dataset中的元素被读取完毕,再尝试sess.run(one_element)的话,会抛出tf.errors.OutOfRangeError异常,这个行为与使用队列方式读取数据是一致的。
高维数据集的使用
tf.data.Dataset.from_tensor_slices真正作用是切分传入Tensor的第一个维度,生成相应的dataset,即第一维表明数据集中数据的数量,之后切分batch等操作均以第一维为基础。
dataset=tf.data.Dataset.from_tensor_slices(np.random.uniform((5,2)))
iterator=dataset.make_one_shot_iterator()
one_element=iterator.get_next()
with tf.Session(config=config) as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError as e:
print('end~')
输出:
[0.1,0.2]
[0.3,0.2]
[0.1,0.6]
[0.4,0.3]
[0.5,0.2]
tuple组合数据
dataset=tf.data.Dataset.from_tensor_slices((np.array([1.,2.,3.,4.,5.]),
np.random.uniform(size=(5,2))))
iterator=dataset.make_one_shot_iterator()
one_element=iterator.get_next()
with tf.Session() as sess:
try:
while True:
print(sess.run(one_element))
except tf.errors.OutOfRangeError:
print('end~')
输出:
(1.,array(0.1,0.3))
(2.,array(0.2,0.4))
...
数据集处理方法
Dataset支持一类特殊操作:Transformation。一个Dataset通过Transformation变成一个新的Dataset。常用的Transformation:
mapbatchshufflerepeat
其中,
-
map和python中的map一致,接受一个函数,Dataset中的每个元素都会作为这个函数的输入,并将函数返回值作为新的Datasetdataset=dataset.map(lambda x:x+1)注意:
map函数可以使用num_parallel_calls参数并行化 -
batch就是将多个元素组成batch。dataset=tf.data.Dataset.from_tensor_slices( { 'a':np.array([1.,2.,3.,4.,5.]), 'b':np.random.uniform(size=(5,2)) }) ### dataset=dataset.batch(2) # batch_size=2 ### iterator=dataset.make_one_shot_iterator() one_element=iterator.get_next() with tf.Session() as sess: try: while True: print(one_element) except tf.errors.OutOfRangeError: print('end~')输出:
{'a':array([1.,2.]),'b':array([[1.,2.],[3.,4.]])} {'a':array([3.,4.]),'b':array([[5.,6.],[7.,8.]])} -
shuffle的功能是打乱dataset中的元素,它有个参数buffer_size,表示打乱时使用的buffer的大小,不应设置过小,推荐值1000.dataset=tf.data.Dataset.from_tensor_slices( { 'a':np.array([1.,2.,3.,4.,5.]), 'b':np.random.uniform(size=(5,2)) }) ### dataset=dataset.shuffle(buffer_size=5) ### iterator=dataset.make_one_shot_iterator() one_element=iterator.get_next() with tf.Session() as sess: try: while True: print(one_element) except tf.errors.OutOfRangeError: print('end~') -
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch。假设原先的数据是一个epoch,使用repeat(2)可以使之变成2个epoch.dataset=tf.data.Dataset.from_tensor_slices({ 'a':np.array([1.,2.,3.,4.,5.]), 'b':np.random.uniform(size=(5,2)) }) ### dataset=dataset.repeat(2) # 2epoch ### # iterator, one_element...注意:如果直接调用
repeat()函数的话,生成的序列会无限重复下去,没有结果,因此不会抛出tf.errors.OutOfRangeError异常。
模拟读入磁盘图片及其Label示例
def _parse_function(filename,label): # 接受单个元素,转换为目标
img_string=tf.read_file(filename)
img_decoded=tf.image.decode_images(img_string)
img_resized=tf.image.resize_images(image_decoded,[28,28])
return image_resized,label
filenames=tf.constant(['data/img1.jpg','data/img2.jpg',...])
labels=tf.constant([1,3,...])
dataset=tf.data.Dataset.from_tensor_slices((filenames,labels))
dataset=dataset.map(_parse_function) # num_parallel_calls 并行
dataset=dataset.shuffle(buffer_size=1000).batch_size(32).repeat(10)
更多Dataset创建方法
tf.data.TextLineDataset():函数输入一个文件列表,输出一个Dataset。dataset中的每一个元素对应文件中的一行,可以使用该方法读入csv文件。tf.data.FixedLengthRecordDataset():函数输入一个文件列表和record_bytes参数,dataset中每一个元素是文件中固定字节数record_bytes的内容,可用来读取二进制保存的文件,如CIFAR10。tf.data.TFRecordDataset():读取TFRecord文件,dataset中每一个元素是一个TFExample。
更多Iterator创建方法
最简单的创建Iterator方法是通过dataset.make_one_shot_iterator()创建一个iterator。
除了这种iterator之外,还有更复杂的Iterator:
- initializable iterator
- reinitializable iterator
- feedable iterator
其中,initializable iterator方法要在使用前通过sess.run()进行初始化,initializable iterator还可用于读入较大数组。在使用tf.data.Dataset.from_tensor_slices(array)时,实际上发生的事情是将array作为一个tf.constants保存到了计算图中,当array很大时,会导致计算图变得很大,给传输保存带来不便,这时可以使用一个placeholder取代这里的array,并使用initializable iterator,只在需要时将array传进去,这样即可避免将大数组保存在图里。
features_placeholder=tf.placeholder(<features.dtype>,<features.shape>)
labels_placeholder=tf.placeholder(<labels.dtype>,<labels.shape>)
dataset=tf.data.Dataset.from_tensor_slices((features_placeholder,labels_placeholder))
iterator=dataset.make_initializable_iterator()
next_element=iterator.get_next()
sess.run(iterator.initializer,feed_dict={features_placeholder:features,labels_placeholder:labels})
Tensorflow内部读取机制
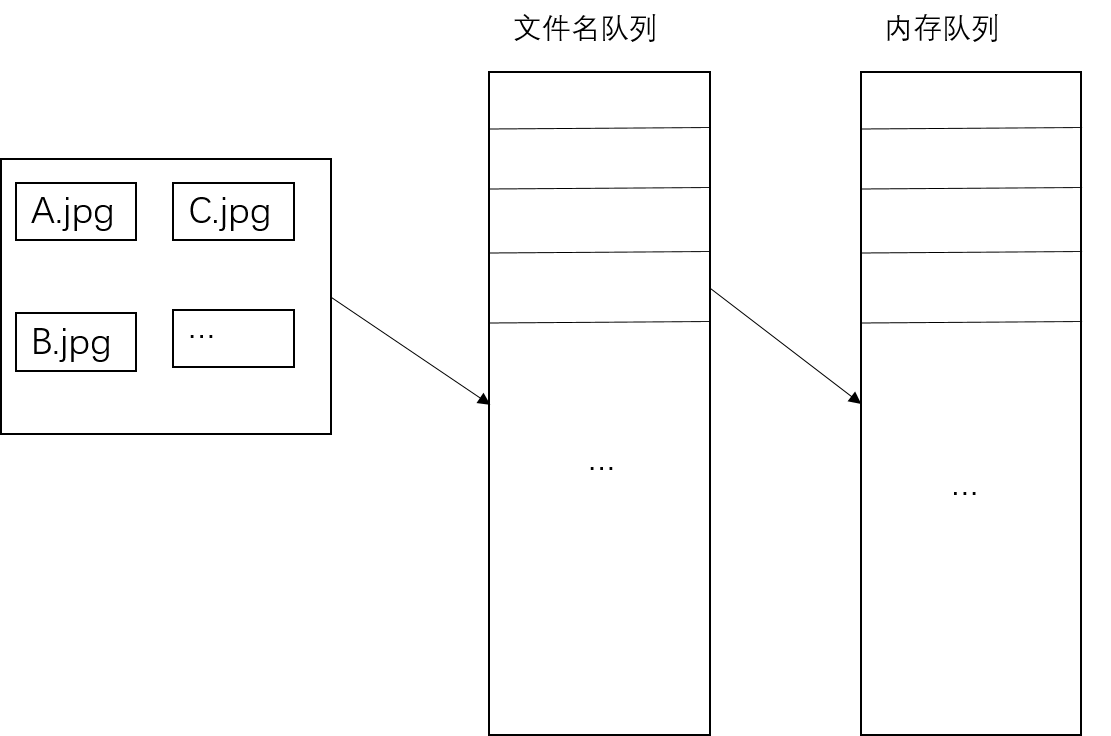
对于文件名队列,使用tf.train.string_input_producer()函数,tf.train.string_input_producer()还有两个重要参数,num_epoches和shuffle
内存队列不需要我们建立,只需要使用reader对象从文件名队列中读取数据即可,使用tf.train.start_queue_runners()函数启动队列,填充两个队列的数据。
with tf.Session() as sess:
filenames=['A.jpg','B.jpg','C.jpg']
filename_queue=tf.train.string_input_producer(filenames,shuffle=True,num_epoch=5)
reader=tf.WholeFileReader()
key,value=reader.read(filename_queue)
# tf.train.string_input_producer()定义了一个epoch变量,需要对其进行初始化
tf.local_variables_initializer().run()
threads=tf.train.start_queue_runners(sess=sess)
i=0
while True:
i+=1
image_data=sess.run(value)
with open('reader/test_%d.jpg'%i,'wb') as f:
f.write(image_data)