目录
简介
网络结构
对应代码
网络说明
参考资料
|
简介 |
2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名、VGG获得了第二名,这两类模型结构的共同特点是层次更深了。VGG继承了LeNet以及AlexNet的一些框架结构,而GoogLeNet则做了更加大胆的网络结构尝试,虽然深度只有22层,但大小却比AlexNet和VGG小很多,GoogleNet参数为500万个,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍,因此在内存或计算资源有限时,GoogleNet是比较好的选择;从模型结果来看,GoogLeNet的性能却更加优越。
GoogLeNet是谷歌(Google)研究出来的深度网络结构,为什么不叫“GoogleNet”,而叫“GoogLeNet”,是为了向“LeNet”致敬,因此取名为“GoogLeNet”
GoogLeNet团队要打造一个Inception模块(名字源于盗梦空间),让深度网络的表现更好。

|
网络结构 |
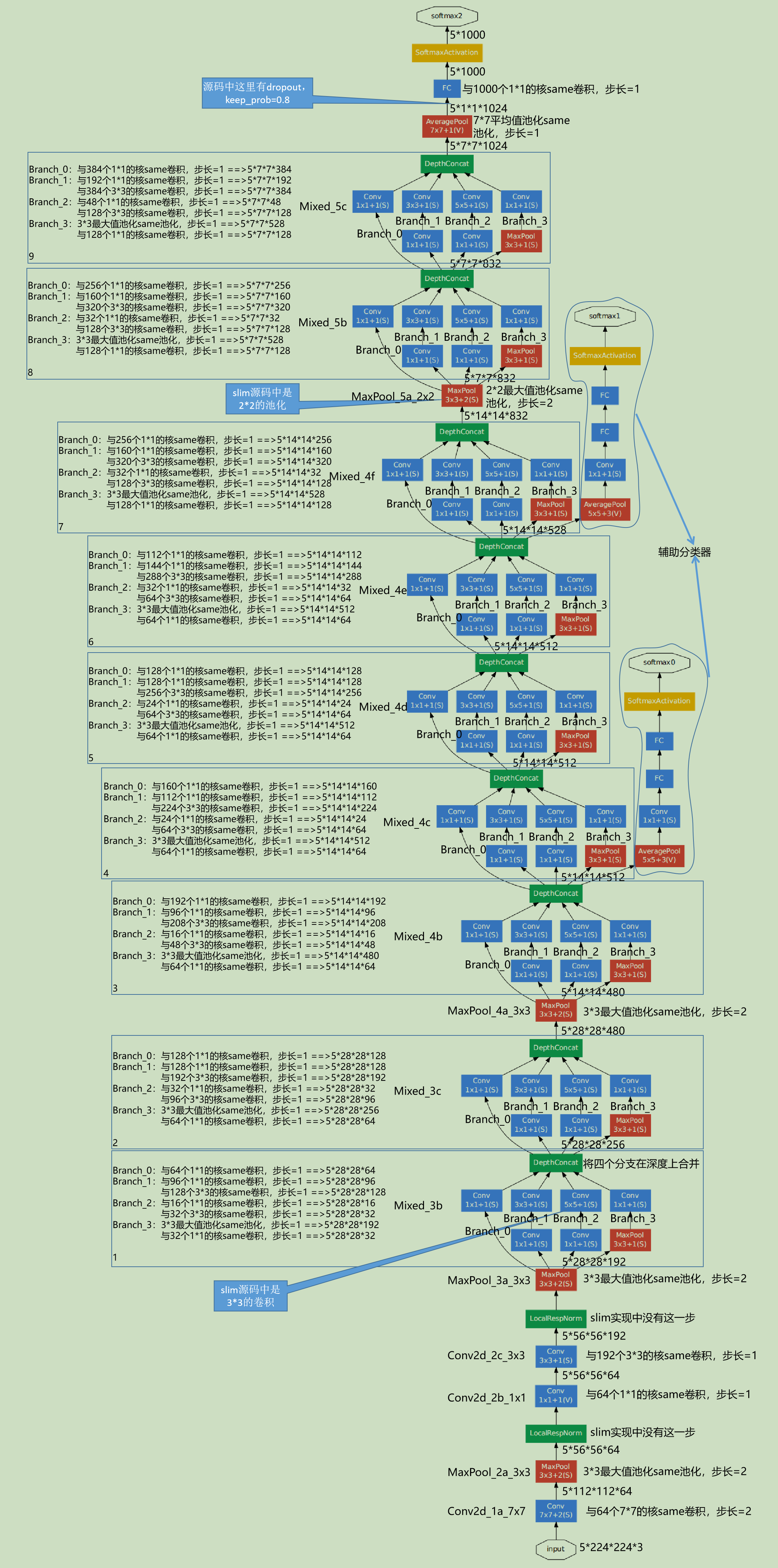
PS:Slim是2016年开发出来的,即使在InceptionV1中,他也没有使用论文里说的5*5的卷积核,而是用的3*3的卷积核。
|
对应代码 |
这里采用的官网的代码tensorflow/models/research/slim/nets/inception_v1.py
下载方式
git clone https://github.com/tensorflow/models.git
这个项目比较大,如果下载很慢的话,可以在qq群:537594183文件中只下载slim的代码即可。


# Copyright 2016 The TensorFlow Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ============================================================================== """Contains the definition for inception v1 classification network.""" from __future__ import absolute_import from __future__ import division from __future__ import print_function import tensorflow as tf from nets import inception_utils slim = tf.contrib.slim trunc_normal = lambda stddev: tf.truncated_normal_initializer(0.0, stddev) def inception_v1_base(inputs, final_endpoint='Mixed_5c', include_root_block=True, scope='InceptionV1'): """Defines the Inception V1 base architecture. This architecture is defined in: Going deeper with convolutions Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. http://arxiv.org/pdf/1409.4842v1.pdf. Args: inputs: a tensor of size [batch_size, height, width, channels]. final_endpoint: specifies the endpoint to construct the network up to. It can be one of ['Conv2d_1a_7x7', 'MaxPool_2a_3x3', 'Conv2d_2b_1x1', 'Conv2d_2c_3x3', 'MaxPool_3a_3x3', 'Mixed_3b', 'Mixed_3c', 'MaxPool_4a_3x3', 'Mixed_4b', 'Mixed_4c', 'Mixed_4d', 'Mixed_4e', 'Mixed_4f', 'MaxPool_5a_2x2', 'Mixed_5b', 'Mixed_5c']. If include_root_block is False, ['Conv2d_1a_7x7', 'MaxPool_2a_3x3', 'Conv2d_2b_1x1', 'Conv2d_2c_3x3', 'MaxPool_3a_3x3'] will not be available. include_root_block: If True, include the convolution and max-pooling layers before the inception modules. If False, excludes those layers. scope: Optional variable_scope. Returns: A dictionary from components of the network to the corresponding activation. Raises: ValueError: if final_endpoint is not set to one of the predefined values. """ end_points = {} with tf.variable_scope(scope, 'InceptionV1', [inputs]): with slim.arg_scope( [slim.conv2d, slim.fully_connected], weights_initializer=trunc_normal(0.01)): with slim.arg_scope([slim.conv2d, slim.max_pool2d], stride=1, padding='SAME'): net = inputs if include_root_block: end_point = 'Conv2d_1a_7x7' net = slim.conv2d(inputs, 64, [7, 7], stride=2, scope=end_point) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'MaxPool_2a_3x3' net = slim.max_pool2d(net, [3, 3], stride=2, scope=end_point) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'Conv2d_2b_1x1' net = slim.conv2d(net, 64, [1, 1], scope=end_point) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'Conv2d_2c_3x3' net = slim.conv2d(net, 192, [3, 3], scope=end_point) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'MaxPool_3a_3x3' net = slim.max_pool2d(net, [3, 3], stride=2, scope=end_point) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'Mixed_3b' with tf.variable_scope(end_point): with tf.variable_scope('Branch_0'): branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1') with tf.variable_scope('Branch_1'): branch_1 = slim.conv2d(net, 96, [1, 1], scope='Conv2d_0a_1x1') branch_1 = slim.conv2d(branch_1, 128, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_2'): branch_2 = slim.conv2d(net, 16, [1, 1], scope='Conv2d_0a_1x1') branch_2 = slim.conv2d(branch_2, 32, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_3'): branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3') branch_3 = slim.conv2d(branch_3, 32, [1, 1], scope='Conv2d_0b_1x1') net = tf.concat( axis=3, values=[branch_0, branch_1, branch_2, branch_3]) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'Mixed_3c' with tf.variable_scope(end_point): with tf.variable_scope('Branch_0'): branch_0 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1') with tf.variable_scope('Branch_1'): branch_1 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1') branch_1 = slim.conv2d(branch_1, 192, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_2'): branch_2 = slim.conv2d(net, 32, [1, 1], scope='Conv2d_0a_1x1') branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_3'): branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3') branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1') net = tf.concat( axis=3, values=[branch_0, branch_1, branch_2, branch_3]) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'MaxPool_4a_3x3' net = slim.max_pool2d(net, [3, 3], stride=2, scope=end_point) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'Mixed_4b' with tf.variable_scope(end_point): with tf.variable_scope('Branch_0'): branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1') with tf.variable_scope('Branch_1'): branch_1 = slim.conv2d(net, 96, [1, 1], scope='Conv2d_0a_1x1') branch_1 = slim.conv2d(branch_1, 208, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_2'): branch_2 = slim.conv2d(net, 16, [1, 1], scope='Conv2d_0a_1x1') branch_2 = slim.conv2d(branch_2, 48, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_3'): branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3') branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1') net = tf.concat( axis=3, values=[branch_0, branch_1, branch_2, branch_3]) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'Mixed_4c' with tf.variable_scope(end_point): with tf.variable_scope('Branch_0'): branch_0 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1') with tf.variable_scope('Branch_1'): branch_1 = slim.conv2d(net, 112, [1, 1], scope='Conv2d_0a_1x1') branch_1 = slim.conv2d(branch_1, 224, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_2'): branch_2 = slim.conv2d(net, 24, [1, 1], scope='Conv2d_0a_1x1') branch_2 = slim.conv2d(branch_2, 64, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_3'): branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3') branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1') net = tf.concat( axis=3, values=[branch_0, branch_1, branch_2, branch_3]) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'Mixed_4d' with tf.variable_scope(end_point): with tf.variable_scope('Branch_0'): branch_0 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1') with tf.variable_scope('Branch_1'): branch_1 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1') branch_1 = slim.conv2d(branch_1, 256, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_2'): branch_2 = slim.conv2d(net, 24, [1, 1], scope='Conv2d_0a_1x1') branch_2 = slim.conv2d(branch_2, 64, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_3'): branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3') branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1') net = tf.concat( axis=3, values=[branch_0, branch_1, branch_2, branch_3]) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'Mixed_4e' with tf.variable_scope(end_point): with tf.variable_scope('Branch_0'): branch_0 = slim.conv2d(net, 112, [1, 1], scope='Conv2d_0a_1x1') with tf.variable_scope('Branch_1'): branch_1 = slim.conv2d(net, 144, [1, 1], scope='Conv2d_0a_1x1') branch_1 = slim.conv2d(branch_1, 288, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_2'): branch_2 = slim.conv2d(net, 32, [1, 1], scope='Conv2d_0a_1x1') branch_2 = slim.conv2d(branch_2, 64, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_3'): branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3') branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1') net = tf.concat( axis=3, values=[branch_0, branch_1, branch_2, branch_3]) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'Mixed_4f' with tf.variable_scope(end_point): with tf.variable_scope('Branch_0'): branch_0 = slim.conv2d(net, 256, [1, 1], scope='Conv2d_0a_1x1') with tf.variable_scope('Branch_1'): branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1') branch_1 = slim.conv2d(branch_1, 320, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_2'): branch_2 = slim.conv2d(net, 32, [1, 1], scope='Conv2d_0a_1x1') branch_2 = slim.conv2d(branch_2, 128, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_3'): branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3') branch_3 = slim.conv2d(branch_3, 128, [1, 1], scope='Conv2d_0b_1x1') net = tf.concat( axis=3, values=[branch_0, branch_1, branch_2, branch_3]) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'MaxPool_5a_2x2' net = slim.max_pool2d(net, [2, 2], stride=2, scope=end_point) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'Mixed_5b' with tf.variable_scope(end_point): with tf.variable_scope('Branch_0'): branch_0 = slim.conv2d(net, 256, [1, 1], scope='Conv2d_0a_1x1') with tf.variable_scope('Branch_1'): branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1') branch_1 = slim.conv2d(branch_1, 320, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_2'): branch_2 = slim.conv2d(net, 32, [1, 1], scope='Conv2d_0a_1x1') branch_2 = slim.conv2d(branch_2, 128, [3, 3], scope='Conv2d_0a_3x3') with tf.variable_scope('Branch_3'): branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3') branch_3 = slim.conv2d(branch_3, 128, [1, 1], scope='Conv2d_0b_1x1') net = tf.concat( axis=3, values=[branch_0, branch_1, branch_2, branch_3]) end_points[end_point] = net if final_endpoint == end_point: return net, end_points end_point = 'Mixed_5c' with tf.variable_scope(end_point): with tf.variable_scope('Branch_0'): branch_0 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1') with tf.variable_scope('Branch_1'): branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1') branch_1 = slim.conv2d(branch_1, 384, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_2'): branch_2 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1') branch_2 = slim.conv2d(branch_2, 128, [3, 3], scope='Conv2d_0b_3x3') with tf.variable_scope('Branch_3'): branch_3 = slim.max_pool2d(net, [3, 3], scope='MaxPool_0a_3x3') branch_3 = slim.conv2d(branch_3, 128, [1, 1], scope='Conv2d_0b_1x1') net = tf.concat( axis=3, values=[branch_0, branch_1, branch_2, branch_3]) end_points[end_point] = net if final_endpoint == end_point: return net, end_points raise ValueError('Unknown final endpoint %s' % final_endpoint) def inception_v1(inputs, num_classes=1000, is_training=True, dropout_keep_prob=0.8, prediction_fn=slim.softmax, spatial_squeeze=True, reuse=None, scope='InceptionV1', global_pool=False): """Defines the Inception V1 architecture. This architecture is defined in: Going deeper with convolutions Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. http://arxiv.org/pdf/1409.4842v1.pdf. The default image size used to train this network is 224x224. Args: inputs: a tensor of size [batch_size, height, width, channels]. num_classes: number of predicted classes. If 0 or None, the logits layer is omitted and the input features to the logits layer (before dropout) are returned instead. is_training: whether is training or not. dropout_keep_prob: the percentage of activation values that are retained. prediction_fn: a function to get predictions out of logits. spatial_squeeze: if True, logits is of shape [B, C], if false logits is of shape [B, 1, 1, C], where B is batch_size and C is number of classes. reuse: whether or not the network and its variables should be reused. To be able to reuse 'scope' must be given. scope: Optional variable_scope. global_pool: Optional boolean flag to control the avgpooling before the logits layer. If false or unset, pooling is done with a fixed window that reduces default-sized inputs to 1x1, while larger inputs lead to larger outputs. If true, any input size is pooled down to 1x1. Returns: net: a Tensor with the logits (pre-softmax activations) if num_classes is a non-zero integer, or the non-dropped-out input to the logits layer if num_classes is 0 or None. end_points: a dictionary from components of the network to the corresponding activation. """ # Final pooling and prediction with tf.variable_scope(scope, 'InceptionV1', [inputs], reuse=reuse) as scope: with slim.arg_scope([slim.batch_norm, slim.dropout], is_training=is_training): net, end_points = inception_v1_base(inputs, scope=scope) with tf.variable_scope('Logits'): if global_pool: # Global average pooling. net = tf.reduce_mean(net, [1, 2], keep_dims=True, name='global_pool') end_points['global_pool'] = net else: # Pooling with a fixed kernel size. net = slim.avg_pool2d(net, [7, 7], stride=1, scope='AvgPool_0a_7x7') end_points['AvgPool_0a_7x7'] = net if not num_classes: return net, end_points net = slim.dropout(net, dropout_keep_prob, scope='Dropout_0b') logits = slim.conv2d(net, num_classes, [1, 1], activation_fn=None, normalizer_fn=None, scope='Conv2d_0c_1x1') if spatial_squeeze: logits = tf.squeeze(logits, [1, 2], name='SpatialSqueeze') end_points['Logits'] = logits end_points['Predictions'] = prediction_fn(logits, scope='Predictions') return logits, end_points inception_v1.default_image_size = 224 inception_v1_arg_scope = inception_utils.inception_arg_scope
|
网络说明 |
(1)GoogLeNet采用了模块化的结构(Inception结构),方便增添和修改;
(2)网络最后采用了average pooling(平均池化)来代替全连接层,,事实证明这样可以将准确率提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
(3)虽然移除了全连接,但是网络中依然使用了Dropout ;
(4)辅助分类器的两个分支有什么用呢?
作用一:可以把他看做inception网络中的一个小细节,它确保了即便是隐藏单元和中间层也参与了特征计算,他们也能预测图片的类别,他在inception网络中起到一种调整的效果,并且能防止网络发生过拟合。
作用二:给定深度相对较大的网络,有效传播梯度反向通过所有层的能力是一个问题。通过将辅助分类器添加到这些中间层,可以期望较低阶段分类器的判别力。在训练期间,它们的损失以折扣权重(辅助分类器损失的权重是0.3)加到网络的整个损失上。
Inception V1的参数量=5607184,约为560w
|
参考资料 |
《图解深度学习与神经网络:从张量到TensorFlow实现》_张平
inceptionV1-Going Deeper with Convolutions
http://noahsnail.com/2017/07/21/2017-07-21-GoogleNet%E8%AE%BA%E6%96%87%E7%BF%BB%E8%AF%91%E2%80%94%E2%80%94%E4%B8%AD%E8%8B%B1%E6%96%87%E5%AF%B9%E7%85%A7/
《深-度-学-习-核-心-技-术-与-实-践》
大话CNN经典模型:GoogLeNet(从Inception v1到v4的演进)
https://my.oschina.net/u/876354/blog/1637819