实验五 环境变量与文件查找
(环境变量的作用与用法,及几种搜索文件的方法)
一、环境变量
1.变量
(1)常变量与值是一对一的关系
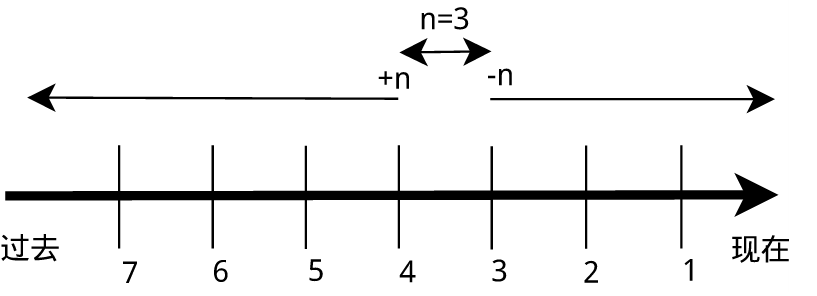
(2)变量的作用域即变量的有效范围(比如一个函数中、一个源文件中或者全局范围),在该范围内只能有一个同名变量。一旦离开则该变量无效,如同不存在这个变量一般。
这里是一个例子:
declare命令创建一个变量名为 tmp 的变量: $ declare tmp
使用=号赋值运算符为变量 tmp 赋值为 shiyanlou:$ tmp=shiyanlou
读取变量的值,使用echo命令和$符号($符号用于表示引用一个变量的值,初学者经常会忘记输入):$ echo $tmp、
*变量名只能是英文字母,数字或者下划线,且不能以数字作为开头。
2.环境变量
通常我们会涉及到的环境变量有三种:
(1)当前 Shell 进程私有用户自定义变量,如上面我们创建的 temp 变量,只在当前 Shell 中有效。
(2)Shell 本身内建的变量。
(3)从自定义变量导出的环境变量
环境变量相关命令:
| 命令 | 说明 |
|---|---|
set |
显示当前 Shell 所有环境变量,包括其内建环境变量(与 Shell 外观等相关),用户自定义变量及导出的环境变量 |
env |
显示与当前用户相关的环境变量,还可以让命令在指定环境中运行 |
export |
显示从 Shell 中导出成环境变量的变量,也能通过它将自定义变量导出为环境变量 |

可以简单的理解成在当前进程的子进程是否有效,有效则为环境变量
3.命令的查找路径与顺序
这个PATH里面就保存了Shell中执行的命令的搜索路径。
创建一个 Shell 脚本文件: $ vim hello_shell.sh

为文件添加可执行权限: $ chmod 755 hello_shell.sh
执行脚本 $ ./hello_shell.sh
创建一个 C 语言"hello world"程序: $ vim hello_world.c

使用 gcc 生成可执行文件: $ gcc -o hello_world hello_world.c
gcc 生成二进制文件默认具有可执行权限,不需要修改
在 shiyanlou 家目录创建一个mybin目录,并将上述 hello_shell.sh 和 hello_world 文件移动到其中:
$ mkdir mybin
$ mv hello_shell.sh hello_world mybin/
现在你可以在mybin目录中分别运行你刚刚创建的两个程序:
$ cd mybin
$ ./hello_shell.sh
$ ./hello_world
4.添加自定义路径到“PATH”环境变量
在前面我们应该注意到PATH里面的路径是以:作为分割符,所以我们可以这样添加自定义路径: $ PATH=$PATH:/home/shiyanlou/mybin
4.添加自定义路径到“PATH”环境变量
在前面我们应该注意到PATH里面的路径是以:作为分割符,所以我们可以这样添加自定义路径: $ PATH=$PATH:/home/shiyanlou/mybin
在每个用户的 home 目录中有一个 Shell 每次启动时会默认执行一个配置脚本,以初始化环境,包括添加一些用户自定义环境变量等等。
zsh 的配置文件是.zshrc,相应 Bash 的配置文件为.bashrc。它们在etc下还都有一个或多个全局的配置文件,不过我们一般只修改用户目录下的配置文件。
我们可以简单的使用下面命令直接添加内容到.zshrc中: $ echo "PATH=$PATH:/home/shiyanlou/mybin" >> .zshrc
上述命令中>>表示将标准输出以追加的方式重定向到一个文件中,注意前面用到的>是以覆盖的方式重定向到一个文件中,使用的时候一定要注意分辨。在指定文件不存在的情况下都会创建新的文件。
5.修改和删除已有变量
5.修改和删除已有变量
变量修改
变量的修改有以下几种方式:
| 变量设置方式 | 说明 |
|---|---|
${变量名#匹配字串} |
从头向后开始匹配,删除符合匹配字串的最短数据 |
${变量名##匹配字串} |
从头向后开始匹配,删除符合匹配字串的最长数据 |
${变量名%匹配字串} |
从尾向前开始匹配,删除符合匹配字串的最短数据 |
${变量名%%匹配字串} |
从尾向前开始匹配,删除符合匹配字串的最长数据 |
${变量名/旧的字串/新的字串} |
将符合旧字串的第一个字串替换为新的字串 |
${变量名//旧的字串/新的字串} |
将符合旧字串的全部字串替换为新的字串 |
比如要修改我们前面添加到 PATH 的环境变量。为了避免操作失误导致命令找不到,我们先将 PATH 赋值给一个新的自定义变量 path:
$ path=$PATH
$ echo $path
$ path=${path%/home/shiyanlou/mybin}
# 或使用通配符,*表示任意多个任意字符
$ path=${path%*/mybin}
变量删除
可以使用unset命令删除一个环境变量:$ unset temp
6.如何让环境变量立即生效
使用source命令来让其立即生效,如:$ source .zshrcsource命令还有一个别名就是.,注意与表示当前路径的那个点区分开,虽然形式一样,但作用和使用方式一样,上面的命令如果替换成.的方式就该是$ . ./.zshrc

locate快而全
通过"/var/lib/mlocate/mlocate.db"数据库查找,不过这个数据库也不是实时更新的,系统会使用定时任务每天自动执行updatedb命令更新一次,所以有时候你刚添加的文件,它可能会找不到,需要手动执行一次updatedb命令(在我们的环境中必须先执行一次该命令)。它可以用来查找指定目录下的不同文件类型,如查找 /etc 下所有以 sh 开头的文件: $ locate /etc/sh
*注意,它不只是在 etc 目录下查找并会自动递归子目录进行查找
查找 /usr/share/ 下所有 jpg 文件: $ locate /usr/share/*.jpg
*注意要添加
*号前面的反斜杠转义,否则会无法找到which小而精
which本身是 Shell 内建的一个命令,我们通常使用which来确定是否安装了某个指定的软件,因为它只从PATH环境变量指定的路径中去搜索命令:
$ which man
find精而细
它不但可以通过文件类型、文件名进行查找而且可以根据文件的属性
在指定目录下搜索指定文件名的文件:
$ find /etc/ -name interfaces
*注意 find 命令的路径是作为第一个参数的, 基本命令格式为 find [path] [option] [action]
与时间相关的命令参数:
| 参数 | 说明 |
|---|---|
-atime |
最后访问时间 |
-ctime |
创建时间 |
-mtime |
最后修改时间 |
下面以-mtime参数举例:
-mtime n: n 为数字,表示为在n天之前的”一天之内“修改过的文件
-mtime +n: 列出在n天之前(不包含n天本身)被修改过的文件
-mtime -n: 列出在n天之前(包含n天本身)被修改过的文件
newer file: file为一个已存在的文件,列出比file还要新的文件名
列出 home 目录中,当天(24 小时之内)有改动的文件:$ find ~ -mtime 0

列出用户家目录下比Code文件夹新的文件:$ find ~ -newer /home/shiyanlou/Code

作业:数字雨
需要先安装,因为 Ubuntu 没有预装:$ sudo apt-get update;sudo apt-get install cmatrix
实验六 文件打包与压缩
Linux 上常用的 压缩/解压 工具,介绍了 zip,rar,tar 的使用。
一、文件打包和解压缩
| 文件后缀名 | 说明 |
|---|---|
*.zip |
zip程序打包压缩的文件 |
*.rar |
rar程序压缩的文件 |
*.7z |
7zip程序压缩的文件 |
*.tar |
tar程序打包,未压缩的文件 |
*.gz |
gzip程序(GNU zip)压缩的文件 |
*.xz |
xz程序压缩的文件 |
*.bz2 |
bzip2程序压缩的文件 |
*.tar.gz |
tar打包,gzip程序压缩的文件 |
*.tar.xz |
tar打包,xz程序压缩的文件 |
*tar.bz2 |
tar打包,bzip2程序压缩的文件 |
*.tar.7z |
tar打包,7z程序压缩的文件 |
1.zip压缩打包程序
使用zip打包文件夹:
$ zip -r -q -o shiyanlou.zip /home/shiyanlou
$ du -h shiyanlou.zip
$ file shiyanlou.zip

第一行命令中,-r参数表示递归打包包含子目录的全部内容,-q参数表示为安静模式,即不向屏幕输出信息,-o,表示输出文件,需在其后紧跟打包输出文件名。后面使用du命令查看打包后文件的大小(后面会具体说明该命令)
设置压缩级别为9和1(9最大,1最小),重新打包:
$ zip -r -9 -q -o shiyanlou_9.zip /home/shiyanlou -x ~/*.zip
$ zip -r -1 -q -o shiyanlou_1.zip /home/shiyanlou -x ~/*.zip
这里添加了一个参数用于设置压缩级别-[1-9],1表示最快压缩但体积大,9表示体积最小但耗时最久。最后那个-x是为了排除我们上一次创建的 zip 文件,否则又会被打包进这一次的压缩文件中,注意:这里只能使用绝对路径,否则不起作用。
我们再用du命令分别查看默认压缩级别、最低、最高压缩级别及未压缩的文件的大小:$ du -h -d 0 *.zip ~ | sort

- 创建加密zip包
使用-e参数可以创建加密压缩包:$ zip -r -e -o shiyanlou_encryption.zip /home/shiyanlou
如果你想让你在 Linux 创建的 zip 压缩文件在 Windows 上解压后没有任何问题,那么你还需要对命令做一些修改:
$ zip -r -l -o shiyanlou.zip /home/shiyanlou
需要加上-l参数将LF转换为CR+LF来达到以上目的
2.使用unzip命令解压缩zip文件
将shiyanlou.zip解压到当前目录: $ unzip shiyanlou.zip
使用安静模式,将文件解压到指定目录: $ unzip -q shiyanlou.zip -d ziptest
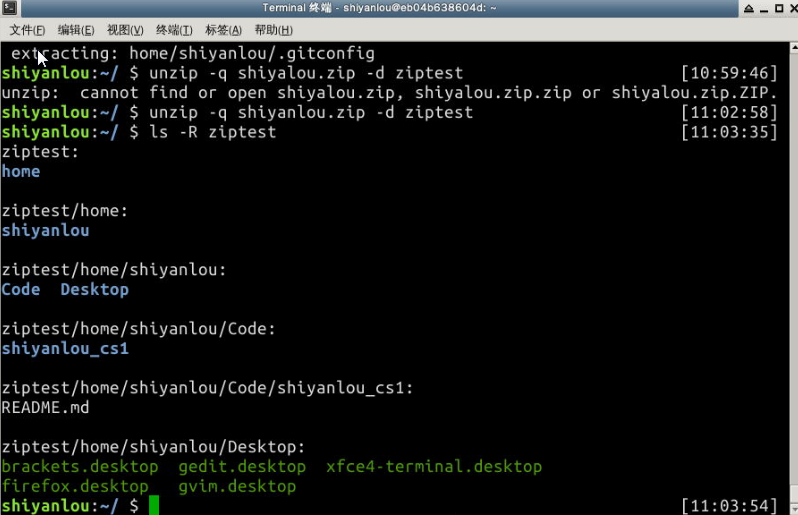
上述指定目录不存在,将会自动创建。如果你不想解压只想查看压缩包的内容你可以使用-l参数:$ unzip -l shiyanlou.zip
如果有有包含中文的文档或以中文作为文件名的文件时默认会采用 GBK 或其它编码,而 Linux 上面默认使用的是 UTF-8 编码,如果不加任何处理,直接解压的话可能会出现中文乱码的问题(有时候它会自动帮你处理),为了解决这个问题,我们可以在解压时指定编码类型。
使用-O(英文字母,大写o)参数指定编码类型:
unzip -O GBK 中文压缩文件.zip
3.rar打包压缩命令
rar也是 Windows 上常用的一种压缩文件格式,在 Linux 上可以使用rar和unrar工具分别创建和解压 rar 压缩包。
安装rar和unrar工具:
$ sudo apt-get update
$ sudo apt-get install rar unrar
从指定文件或目录创建压缩包或添加文件到压缩包:
$ rm *.zip
$ rar a shiyanlou.rar .
上面的命令使用a参数添加一个目录~到一个归档文件中,如果该文件不存在就会自动创建。
注意:rar 的命令参数没有-,如果加上会报错。
从指定压缩包文件中删除某个文件:
$ rar d shiyanlou.rar .zshrc
查看不解压文件:
$ rar l shiyanlou.rar
使用unrar解压rar文件
全路径解压:
$ unrar x shiyanlou.rar
去掉路径解压:
$ mkdir tmp
$ unrar e shiyanlou.rar tmp/
4.tar打包工具
创建一个 tar 包:
$ tar -cf shiyanlou.tar ~

上面命令中,-c表示创建一个 tar 包文件,-f用于指定创建的文件名,注意文件名必须紧跟在-f参数之后,比如不能写成tar -fc shiyanlou.tar,可以写成tar -f shiyanlou.tar -c ~。你还可以加上-v参数以可视的的方式输出打包的文件。上面会自动去掉表示绝对路径的/,你也可以使用-P保留绝对路径符。
解包一个文件(-x参数)到指定路径的已存在目录(-C参数):
$ mkdir tardir
$ tar -xf shiyanlou.tar -C tardir
只查看不解包文件-t参数:
$ tar -tf shiyanlou.tar
保留文件属性和跟随链接(符号链接或软链接),有时候我们使用tar备份文件当你在其他主机还原时希望保留文件的属性(-p参数)和备份链接指向的源文件而不是链接本身(-h参数):
$ tar -cphf etc.tar /etc
对于创建不同的压缩格式的文件,对于tar来说是相当简单的,需要的只是换一个参数,这里我们就以使用gzip工具创建*.tar.gz文件为例来说明。
我们只需要在创建 tar 文件的基础上添加-z参数,使用gzip来压缩文件:
$ tar -czf shiyanlou.tar.gz ~
解压*.tar.gz文件:
$ tar -xzf shiyanlou.tar.gz
现在我们要使用其他的压缩工具创建或解压相应文件只需要更改一个参数即可:
| 压缩文件格式 | 参数 |
|---|---|
*.tar.gz |
-z |
*.tar.xz |
-J |
*tar.bz2 |
-j |
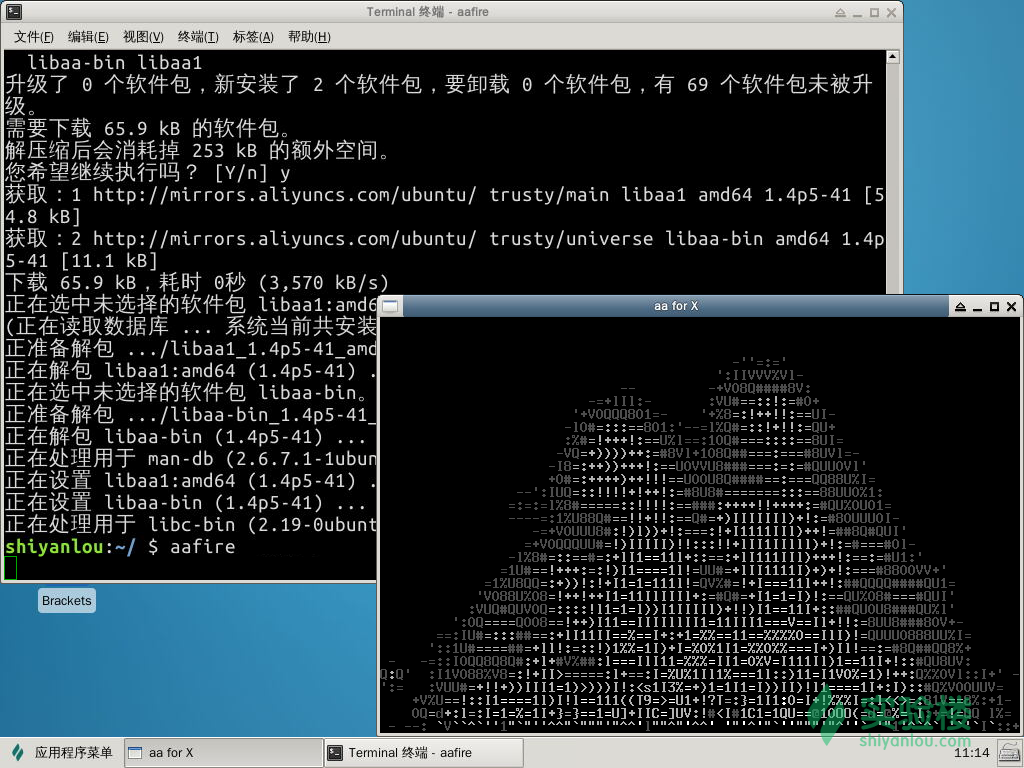
作业:小火苗!
$ sudo apt-get install libaa-bin
# 提示command not found,请自行解决
$ aafire
实验七:文件系统操作与磁盘管理
一、简单文件系统操作
1.查看磁盘和目录的容量
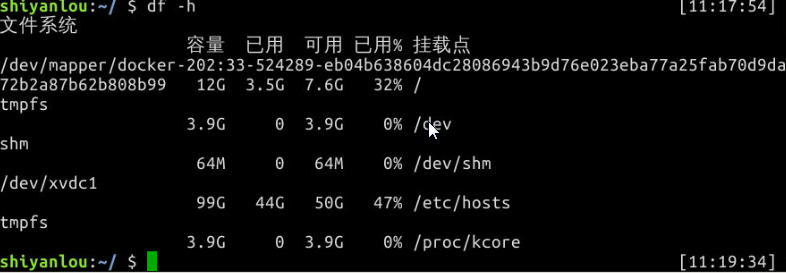
使用 df 命令查看磁盘的容量

第一行的内容也就是环境中的rootfs或者物理主机上的/dev/sda2
"rootfs" : (Root File System)它是 Ramfs(Ramfs 是一个非常简单的 Linux 文件系统用于实现磁盘缓存机制作为动态可调整大小的基于 ram 的文件系统)或者 tmpfs 的一个特殊实例,它作为系统启动时内核载入内存之后,在挂载真正的的磁盘之前的一个临时文件系统。通常的主机会在系统启动后用磁盘上的文件系统替换,只是在一些嵌入式系统中会只存在一个 rootfs ,或者像我们目前遇到的情况运行在虚拟环境中共享主机资源的系统也可能会采用这种方式。
物理主机上的 /dev/sda2 是对应着主机硬盘的分区,后面的数字表示分区号,数字前面的字母 a 表示第几块硬盘(也可能是可移动磁盘),
1k-blocks表示以磁盘块大小的方式显示容量,
df -h
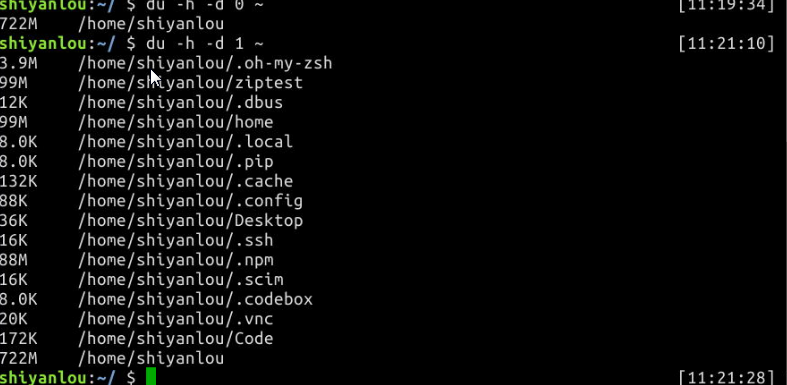
使用 du 命令查看目录的容量
这个命令前面其实已经用了很多次了:
# 默认同样以 blocks 的大小展示
$ du
# 加上`-h`参数,以更易读的方式展示
$ du -h
-d参数指定查看目录的深度
# 只查看1级目录的信息
$ du -h -d 0 ~
# 查看2级
$ du -h -d 1 ~
二、简单的磁盘管理
1.创建虚拟磁盘
dd 命令简介(部分说明来自dd (Unix) wiki))
dd命令用于转换和复制文件,不过它的复制不同于cp。
之前提到过关于 Linux 的很重要的一点,一切即文件,在 Linux 上,硬件的设备驱动(如硬盘)和特殊设备文件(如/dev/zero和/dev/random)都像普通文件一样,只要在各自的驱动程序中实现了对应的功能,dd 也可以读取自和/或写入到这些文件。这样,dd也可以用在备份硬件的引导扇区、获取一定数量的随机数据或者空数据等任务中。dd程序也可以在复制时处理数据,例如转换字节序、或在 ASCII 与 EBCDIC 编码间互换。
dd的命令行语句与其他的 Linux 程序不同,因为它的命令行选项格式为选项=值,而不是更标准的--选项 值或-选项=值。dd默认从标准输入中读取,并写入到标准输出中,但可以用选项if(input file,输入文件)和of(output file,输出文件)改变。

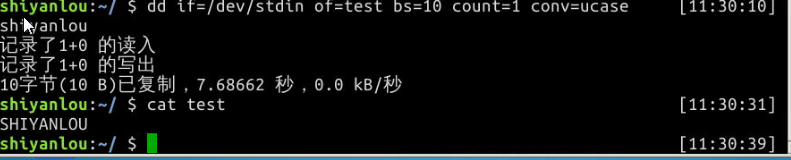
将输出的英文字符转换为大写再写入文件:$ dd if=/dev/stdin of=test bs=10 count=1 conv=ucase
使用 dd 命令创建虚拟镜像文件
从/dev/zero设备创建一个容量为 256M 的空文件:
$ dd if=/dev/zero of=virtual.img bs=1M count=256
$ du -h virtual.img

使用 mkfs 命令格式化磁盘(我们这里是自己创建的虚拟磁盘镜像)
你可以在命令行输入 mkfs 然后按下Tab键,你可以看到很多个以 mkfs 为前缀的命令,这些不同的后缀其实就是表示着不同的文件系统,可以用 mkfs 格式化成的文件系统

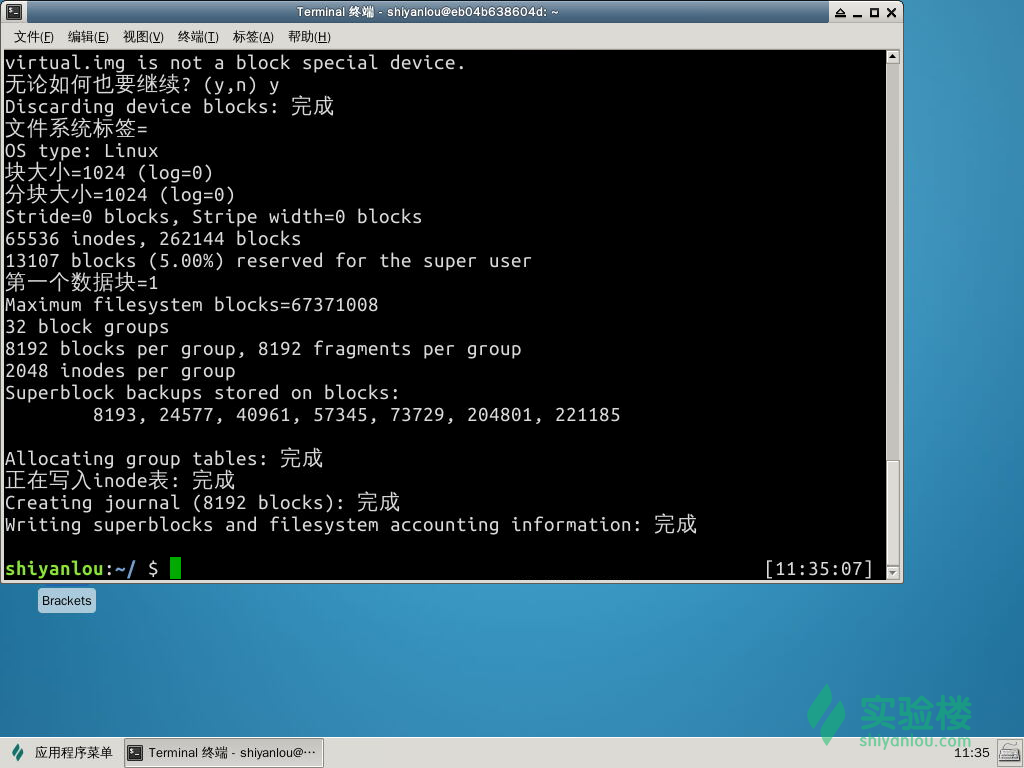
虚拟磁盘镜像格式化为ext4文件系统:
$ mkfs.ext4 virtual.img
使用 mount 命令挂载磁盘到目录树
用户在 Linux/UNIX 的机器上打开一个文件以前,包含该文件的文件系统必须先进行挂载的动作,此时用户要对该文件系统执行 mount 的指令以进行挂载。因为 Linux/UNIX 文件系统可以对应一个文件而不一定要是硬件设备,所以可以挂载一个包含文件系统的文件到目录树
使用mount来查看下主机已经挂载的文件系统: $ sudo mount
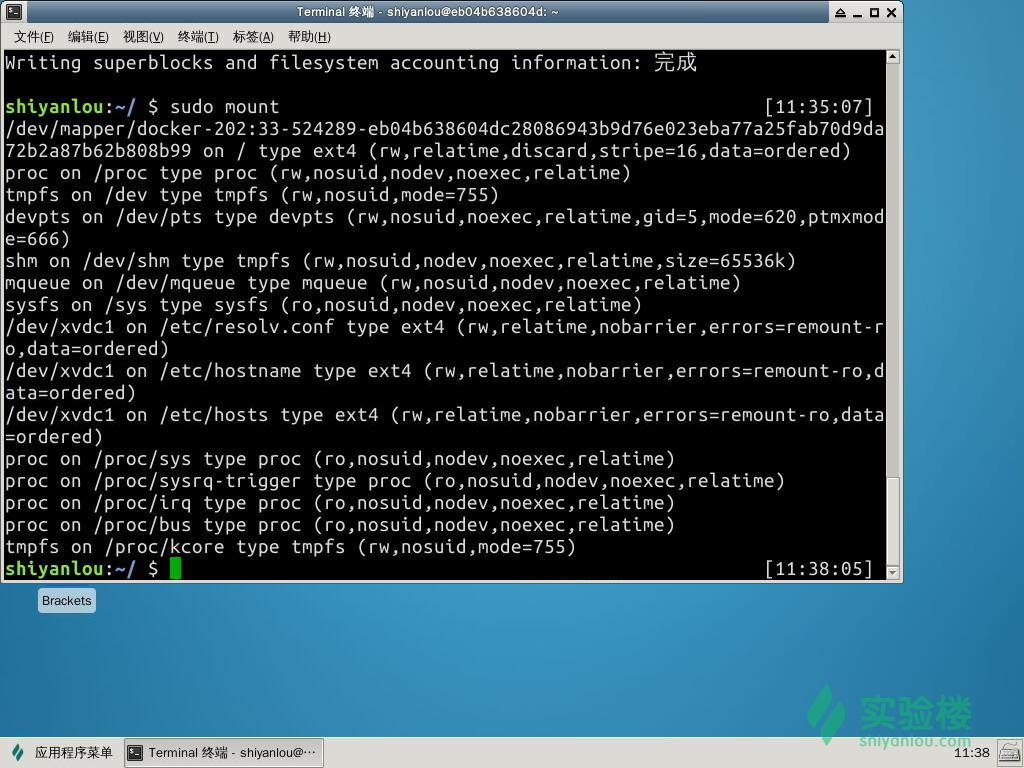
输出的结果中每一行表示一个设备或虚拟设备,每一行最前面是设备名,然后是 on 后面是挂载点,type 后面表示文件系统类型,再后面是挂载选项(比如可以在挂载时设定以只读方式挂载等等)
mount命令的一般格式如下: mount [options] [source] [directory]
一些常用操作:
mount [-o [操作选项]] [-t 文件系统类型] [-w|--rw|--ro] [文件系统源] [挂载点]
直接来挂载我们创建的虚拟磁盘镜像到/mnt目录:$ mount -o loop -t ext4 virtual.img /mnt
# 也可以省略挂载类型,很多时候 mount 会自动识别
# 以只读方式挂载
$ mount -o loop --ro virtual.img /mnt
# 或者mount -o loop,ro virtual.img /mnt
使用 umount 命令卸载已挂载磁盘
# 命令格式 sudo umount 已挂载设备名或者挂载点,如:
$ sudo umount /mnt
使用 fdisk 为磁盘分区(关于分区的一些概念不清楚的用户请参看主引导记录)
# 查看硬盘分区表信息 :$ sudo fdisk -l
# 进入磁盘分区模式 $ sudo fdisk virtual.img
使用 losetup 命令建立镜像与回环设备的关联
$ sudo losetup /dev/loop0 virtual.img
# 如果提示设备忙你也可以使用其它的回环设备,"ls /dev/loop*"参看所有回环设备
# 解除设备关联
$ sudo losetup -d /dev/loop0
然后再使用mkfs格式化各分区(前面我们是格式化整个虚拟磁盘镜像文件或磁盘),不过格式化之前,我们还要为各分区建立虚拟设备的映射,用到kpartx工具,需要先安装:
$ sudo apt-get install kpartx
$ sudo kpart kpartx -av /dev/loop0
# 取消映射
$ sudo kpart kpartx -dv /dev/loop0
接着再是格式化,我们将其全部格式化为 ext4:
$ sudo mkfs.ext4 -q /dev/mapper/loop0p1
$ sudo mkfs.ext4 -q /dev/mapper/loop0p5
$ sudo mkfs.ext4 -q /dev/mapper/loop0p6
格式化完成后在/media目录下新建四个空目录用于挂载虚拟磁盘:
$ mkdir -p /media/virtualdisk_{1..3}
# 挂载磁盘分区
$ sudo mount /dev/mapper/loop0p1 /media/virtualdisk_1
$ sudo mount /dev/mapper/loop0p5 /media/virtualdisk_2
$ sudo mount /dev/mapper/loop0p6 /media/virtualdisk_3
# 卸载磁盘分区
$ sudo umount /dev/mapper/loop0p1
$ sudo umount /dev/mapper/loop0p5
$ sudo umount /dev/mapper/loop0p6
然后: $ df -h
作业:说话的动物orz
# 安装
$ sudo apt-get install cowsay
# 默认是一只牛
$ cowsay hello shiyanlou
# 加上'-l'参数打印所有支持的动物(其实不只是动物)种类
$ cowsay -l
# 使用'-f'参数选择动物种类
$ cowsay -f elephant hello shiyanlou
# 此外它还可以结合我们之前的作业讲过的 fortune 命令一起使用
$ fortune | cowsay -f daemon
实验八:命令执行顺序控制与管道
顺序执行、选择执行、管道、cut 命令、grep 命令、wc 命令、sort 命令等,高效率使用 Linux 的技巧。
一、命令执行顺序的控制
1.顺序执行多条命令
$ sudo apt-get update;sudo apt-get install some-tool;some-tool
# 让它自己运行
2.有选择的执行命令
用which来查找是否安装某个命令,如果找到就执行该命令,否则什么也不做$ which cowsay>/dev/null && cowsay -f head-in ohch~

上面的&&就是用来实现选择性执行的,它表示如果前面的命令执行结果(不是表示终端输出的内容,而是表示命令执行状态的结果)返回0则执行后面的,否则不执行,你可以从$?环境变量获取上一次命令的返回结果。
还有一个||表示逻辑或,同样 Shell 也有一个||,它们的区别就在于,shell中的这两个符号除了也可用于表示逻辑与和或之外,就是可以实现这里的命令执行顺序的简单控制。||在这里就是与&&相反的控制效果,当上一条命令执行结果为≠0($?≠0)时则执行它后面的命令:
$ which cowsay>/dev/null || echo "cowsay has not been install, please run 'sudo apt-get install cowsay' to install"
结合这&&和||来实现一些操作,比如:
$ which cowsay>/dev/null && echo "exist" || echo "not exist"

流程图来解释一下上面的流程:

二、管道
管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),它表现出来的形式就是将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。管道又分为匿名管道和具名管道(这里将不会讨论在源程序中使用系统调用创建并使用管道的情况,它与命令行的管道在内核中实际都是采用相同的机制。
查看/etc目录下有哪些文件和目录,使用ls命令:$ ls -al /etc

太多内容,屏幕不能完全显示
使用管道:
$ ls -al /etc | less

通过管道将前一个命令(ls)的输出作为下一个命令(less)的输入,然后就可以一行一行地看
2.cut 命令,打印每一行的某一字段
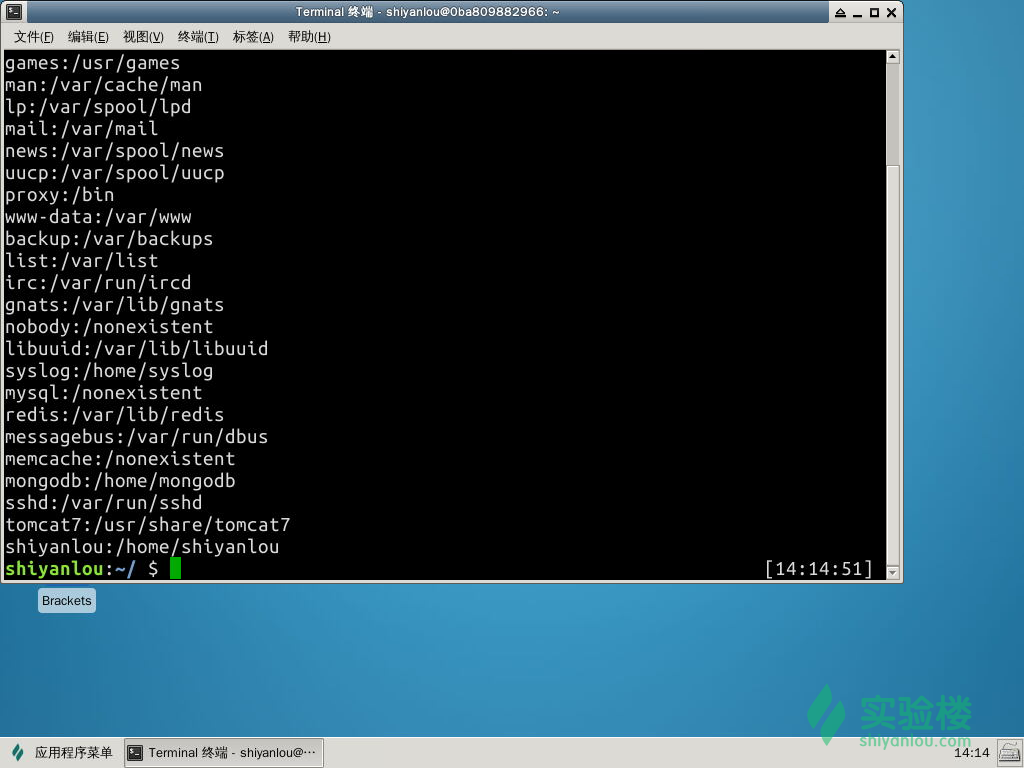
打印/etc/passwd文件中以:为分隔符的第1个字段和第6个字段分别表示用户名和其家目录: $ cut /etc/passwd -d ':' -f 1,6
打印/etc/passwd文件中每一行的前N个字符:
# 前五个(包含第五个)
$ cut /etc/passwd -c -5
# 前五个之后的(包含第五个)
$ cut /etc/passwd -c 5-
# 第五个
$ cut /etc/passwd -c 5
# 2到5之间的(包含第五个)
$ cut /etc/passwd -c 2-5
3.grep 命令,在文本中或 stdin 中查找匹配字符串
grep命令的一般形式为:
grep [命令选项]... 用于匹配的表达式 [文件]...
搜索/home/shiyanlou目录下所有包含"shiyanlou"的所有文本文件,并显示出现在文本中的行号:
$ grep -rnI "shiyanlou" ~

-r 参数表示递归搜索子目录中的文件,-n表示打印匹配项行号,-I表示忽略二进制文件
当然也可以在匹配字段中使用正则表达式,下面简单的演示:
# 查看环境变量中以"yanlou"结尾的字符串
$ export | grep ".*yanlou$"

其中$就表示一行的末尾。
4. wc 命令,简单小巧的计数工具
wc 命令用于统计并输出一个文件中行、单词和字节的数目,比如输出/etc/passwd文件的统计信息:
$ wc /etc/passwd
分别只输出行数、单词数、字节数、字符数和输入文本中最长一行的字节数:
# 行数
$ wc -l /etc/passwd
# 单词数
$ wc -w /etc/passwd
# 字节数
$ wc -c /etc/passwd
# 字符数
$ wc -m /etc/passwd
# 最长行字节数
$ wc -L /etc/passwd

再来结合管道来操作一下,下面统计 /etc 下面所有目录数:
$ ls -dl /etc/*/ | wc -l

5.sort 排序命令
默认为字典排序: $ cat /etc/passswd | sort反转排序: $ cat /etc/passwd | sort -r
按特定字段排序: $ cat /etc/passwd | sort -t':' -k 3
上面的-t参数用于指定字段的分隔符,这里是以":"作为分隔符;-k 字段号用于指定对哪一个字段进行排序。这里/etc/passwd文件的第三个字段为数字,默认情况下是一字典序排序的,如果要按照数字排序就要加上-n参数:
$ cat /etc/passwd | sort -t':' -k 3 -n

6. uniq 去重命令
uniq命令可以用于过滤或者输出重复行。
(1)过滤重复行
我们可以使用history命令查看最近执行过的命令(实际为读取${SHELL}_history文件,如我们环境中的~/.zsh_history文件)
$ history | cut -c 8- | cut -d ' ' -f 1 | uniq
因为uniq命令只能去连续重复的行,不是全文去重,所以要达到预期效果,我们先排序:
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq
# 或者$ history | cut -c 8- | cut -d ' ' -f 1 | sort -u
(2)输出重复行
# 输出重复过的行(重复的只输出一个)及重复次数
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -dc
# 输出所有重复的行
$ history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -D
作业
显示图片:
参考
使用apt-get方式下载:

*效果不太好?
