目录
1、Python的发展
2、Python特性介绍及其它语言对比
3、Python安装及环境准备
4、编程风格要求
5、Python的数据类型和运算符
6、单行和多行注释
7、理解ASSIC、Unicode、UTF-8编码
8、使用和导入模块
9、用户交互和格式化输出
10、流程控制if for循环
11、while 循环及中断控制
12、作业需求、作业展示
1、Python的发展
Python是著名的“龟叔”Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言。
Python就为我们提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池(batteries included)”。用Python开发,许多功能不必从零编写,直接使用现成的即可。
除了内置的库外,Python还有大量的第三方库,也就是别人开发的,供你直接使用的东西。当然,如果你开发的代码通过很好的封装,也可以作为第三方库给别人使用。
许多大型网站就是用Python开发的,例如YouTube、Instagram,还有国内的豆瓣。很多大公司,包括Google、Yahoo等,甚至NASA(美国航空航天局)都大量地使用Python。
龟叔给Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是简单易懂,初学者学Python,不但入门容易,而且将来深入下去,可以编写那些非常非常复杂的程序。
2、Python特性介绍
Python的优点:
*简单、优雅、明确
*强大的模块三方库
*易移植
*面向对象
*可扩展(cjavac#...)
Python的缺点:
*代码不能加密
*速度慢
3、Python安装及环境准备
CentOs6.7 python2.6升级到2.7.11
Python安装
4、编程风格要求
语法要求:
- 统一缩进
- 变量
* 标识符的第一个字符必须是字母表中的字母(大写或小写)或者一个下划线('_')
* 标识符名称的其他部分可以由字母(大写或小写)、下划线或数字
* 标识符名称是对大小写敏感的。例如,myname和myName不是一个标识符
5、Python的数据类型和运算符
参看:http://www.runoob.com/python/python-operators.html
6、单行和多行注释
单行注释
单行注释以#开头,例如:
print 6 #输出6
多行注释
(Python的注释只有针对于单行的注释(用#),这是一种变通的方法)
多行注释用三引号'''将注释括起来,例如:
'''
多行注释
多行注释
'''
7、理解ASSIC、Unicode、UTF-8编码
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
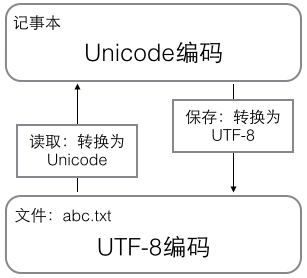
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
8、使用和导入模块
方法一: import sys
方法二: from sys import argv
方法三: import multiprocessing as multi
方法四: from sys import * #不建议使用此方法
输出
print sys.argv
print sys.argv[2]
9、用户交互和格式化输出
[xiaorui@xiaorui python]$ cat ex3.py #!/usr/bin/env python #_*_ coding:utf-8 _*_ #如果使用中文加上此行 #用户交互 name = raw_input('Please input your name:') age = input('age:') job = raw_input('Job:') salary = raw_input('Salary:') real_age = 29 #raw_input不管用户输入什么类型都会转变为字符型 #input用户输入的是什么类型就是什么类型,如果输入字符和字符串必须用引号包起来 #查看输出的类型 print type(name) print type(age) print type(salary) #流程控制 for i in range(10): age = input('age:') if age > 29: print 'think smaller!' elif age == 29: print '�33[31;1mGood! 10 RMB !�33[0m' #给字体添加颜色(30、31、32、33、34、35、36、37等) break else: print 'think bigger!' if i < 9: print 'You still got %s shorts!' % (9-i) elif i == 9: print 'your think error !' print 'The real_age is %s' % real_age age = 29 #流程控制满足第一条if后结束,如果第一条不匹配则继续往下匹配,直到else # %代表shell的$ print ''' Personal information of %s: Name: %s Age : %s Job : %s Salary : %s ''' %(name,name,age,job,salary) #此乃格式化输出
10、流程控制if for循环
if...else
age = 3 if age >= 18: print('adult') elif age >= 6: print('teenager') else: print('kid')
Python的循环有两种,一种是for...in循环,依次把list或tuple中的每个元素迭代出来,看例子:
names = ['Michael', 'Bob', 'Tracy'] for name in names: print(name)
如果要计算1-100的整数之和,从1写到100有点困难,幸好Python提供一个range()函数,可以生成一个整数序列,再通过list()函数可以转换为list。比如range(5)生成的序列是从0开始小于5的整数:
>>> list(range(5)) [0, 1, 2, 3, 4]
range(101)就可以生成0-100的整数序列
第二种循环是while循环,只要条件满足,就不断循环,条件不满足时退出循环。比如我们要计算100以内所有奇数之和,可以用while循环实现:
sum = 0 n = 99 while n > 0: sum = sum + n n = n - 2 print(sum)
在循环内部变量n不断自减,直到变为-1时,不再满足while条件,循环退出。
11、中断控制
break语句用来终止循环语句,即循环条件没有False条件或者序列还没被完全递归完,也会停止执行循环语句。
break语句用在while和for循环中。
如果您使用嵌套循环,break语句将停止执行最深层的循环,并开始执行下一行代码。
continue 语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
continue语句用在while和for循环中。