抽象的艺术才有生命力 高层与底层组件之间都应该依赖于抽象的组件。这一条深刻揭示了抽象的生命力,抽象的对象才是最有表达能力的对象,因为它通常是“无形”的,可以随时填充相关的细节。
英文缩写DIP(Dependence Inversion Principle)。
原始定义:High level modules should depend upon low level modules. Both should depend upon abstractions. Abstractions should not depend upon details. Details www.szihome.netshould depend upon abstractions.
翻译过来就三层含义:
高层模块不应该依赖低层模块,两者都应该依赖其抽象;
抽象不应该依赖细节;
细节应该依赖抽象。
抽象:即抽象类或接口,两者是不能够实例化的。
细节:即具体的实现类,实现接口或者继承抽象类所产生的类,两者可以通过关键字new直接被实例化。
现在我们来通过实例还原开篇问题的场景,以便更好的来理解。下面代码描述了一个简单的场景,Jim作为人有吃的方法,苹果有取得自己名字的方法,然后实现Jim去吃苹果。
问题由来:类A直接依赖类B,假如要将类A改为依赖类C,则必须通过修改类A的代码来达成。这种场景下,类A一般是高层模块,负责复杂的业务逻辑:类B和类C是低层模块,负责基本的原子操作;假如修改类A,会给程序带来不必要的风险。
解决方案:将类A修改为依赖接口I,类B和类C各自实现接口I,类A通过接口I间接与类B或者类C发生联系,则会大大降低修改类A的几率。
依赖倒置原则基于这样一个事实:相对于细节的多变性,抽象的东西要稳定的多。以抽象为基础搭建起来的架构比以细节为基础搭建起来的架构要稳定的多。在java中,抽象指的是接口或者抽象类,细节就是具体的实现类,使用接口或者抽象类的目的是制定好规范和契约,而不去涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成。
*依赖倒置原则针对的是接口编程。
*对于容易发生的变化的地方,提供接口,接口具有高度抽象性,让其进行接收,这样就可以极大的减少修改高层模块中的代码。
● 低层模块尽量都要有抽象类或接口,或者两者都有。
● 变量的声明类型尽量是抽象类或接口。
● 使用继承时遵循里氏替换原则。
依赖倒置原则的核心就是要我们面向接口编程,理解了面向接口编程,也就理解了依赖倒置。
举例说明:
假设计算机有3大重要部件:cpu,硬盘,内存条
为了能够让计算机能够和三大部件进行解耦合,意思就是计算机可以安装任何型号的cpu,硬盘,内存条。设计原则就是让计算机依赖三大部件(高层依赖于抽象层),让实现层依赖于抽象层,各种类型的cpu去继承抽象层,这样达到了高层和实现层的解耦合,也让实现层和实现层之间解耦合。
下面这个例子不错(https://blog.csdn.net/dengjili/article/details/79456019):
情景描述
当前有一家饮料店,里面卖着很多饮料
设计如下

问题描述
- 这里箭头符号表示BeverageStore依赖Juice,及高层依赖于低层
- 在BeverageStore中,对应的是具体的饮料实现,具体代码如下
package headfirst.hd.dep; public class BeverageStore { //卖果汁 public Juice saleBeverage() { //果汁的具体实现 Juice juice = new Juice(); return juice; } }
修改设计,为饮料提供统一接口
备注:这是网上很多教程讲的例子,根据我自己的理解,这不是依赖倒置的体现,后来我会给出原因
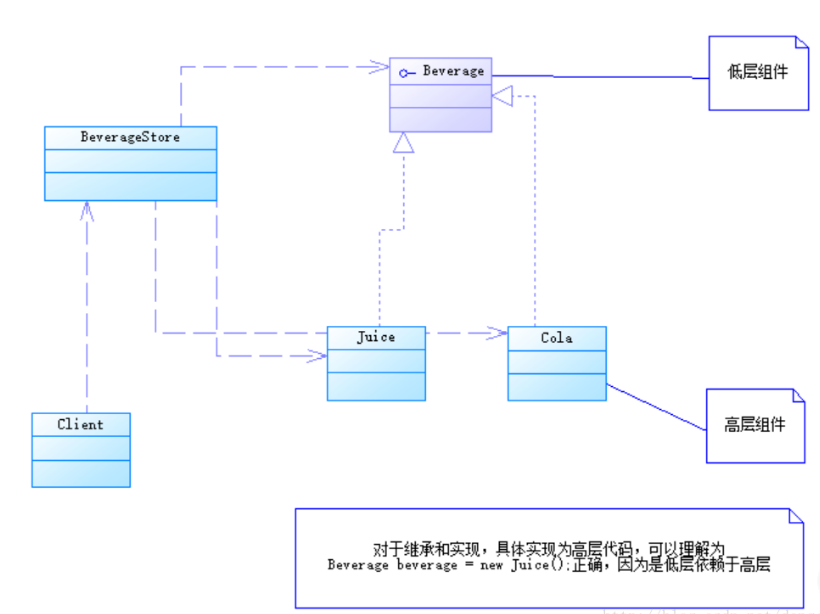
核心代码变为一下代码,依赖变为不仅依赖低层组件的实现,而且还依赖低层组件的抽象,比之前还更糟糕
package headfirst.hd.dep; public class BeverageStore { //卖果汁 public Beverage saleBeverage() { //果汁的具体实现 Beverage beverage = new Juice(); return beverage; } }
对这个代码再优化一下
package headfirst.hd.dep; //这是网上最常见方式 public class BeverageStore { //卖果汁 public Beverage saleBeverage(Beverage beverage) { //做一些其他操作 return beverage; } }
客户端Client
package headfirst.hd.dep; public class Client { public static void main(String[] args) { BeverageStore store = new BeverageStore(); store.saleBeverage(new Juice()); } }
对应设计变化为

- 高层依赖低层还是曾在,并且由更高层依赖了低层模块
- 我个人觉得这应该叫依赖转移
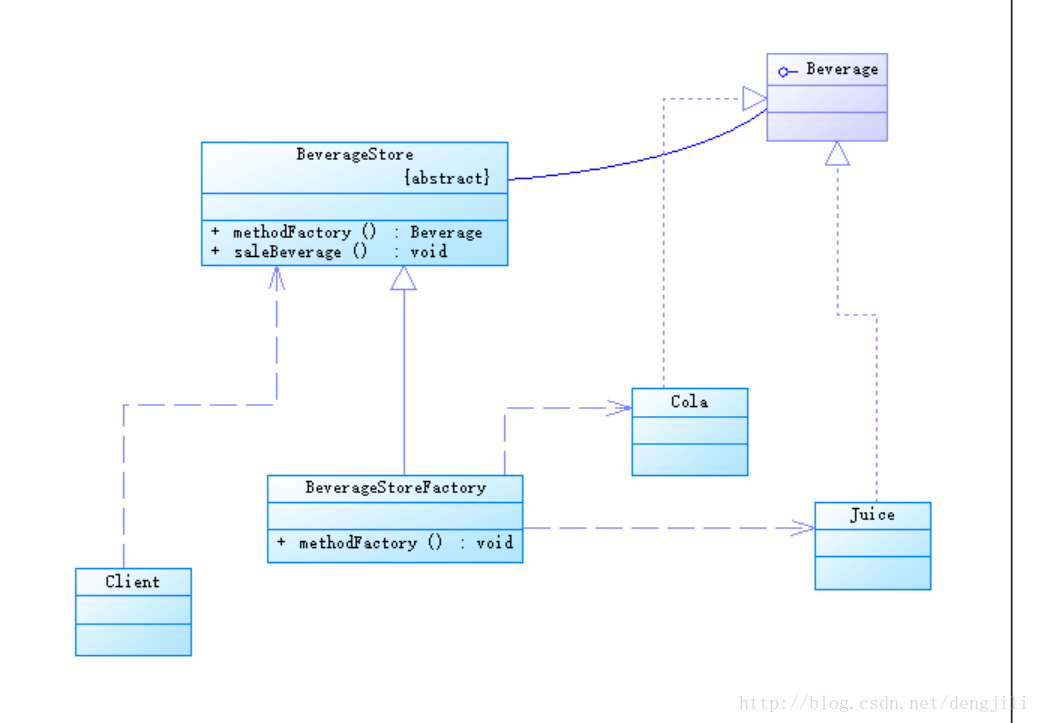
引入工厂方法模式改进以上例子
工厂模式设计图
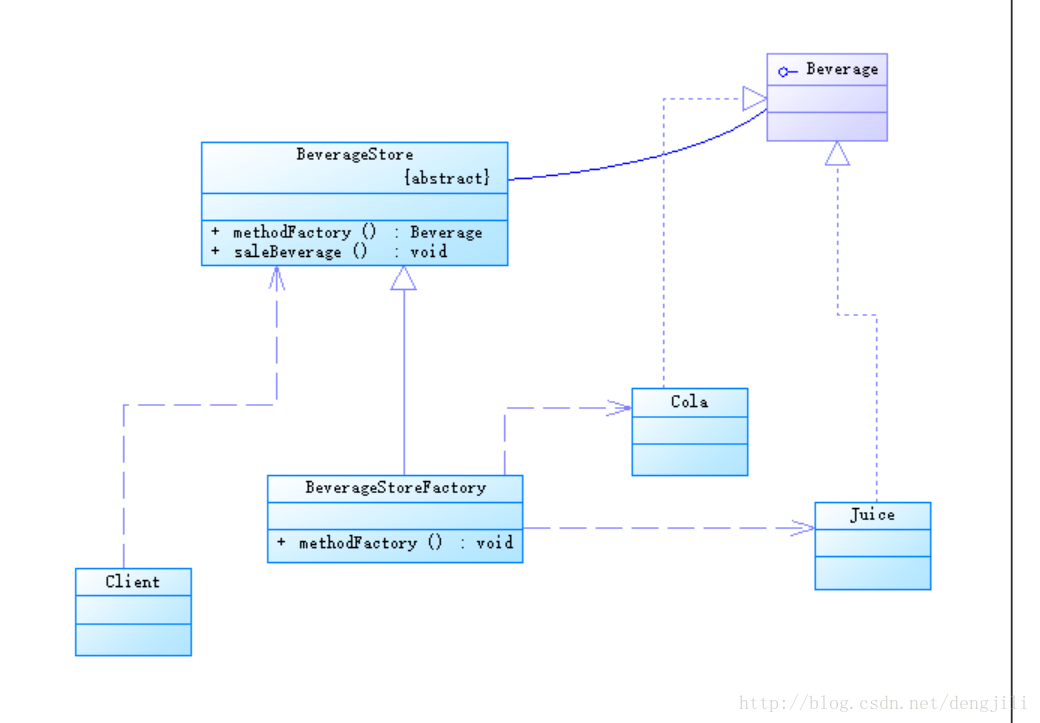
核心代码
BeverageStore
package headfirst.hd.dep; //工厂方法模式 public abstract class BeverageStore { //卖果汁 public Beverage saleBeverage() { //直接使用自身定义的抽象方法 Beverage beverage = createBeverage(); //做一些其他操作 return beverage; } /** * 抽象类BeverageStore抽象方法定义,Beverage createBeverage() * 表明createBeverage与BeverageStore为一体,关系为一根横线, * 两者没有实质依赖关系,因为在BeverageStore中,直接使用自身 * 定义方法createBeverage,在类BeverageStore的其他方法中, * 直接使用该类型,具体实现具体类,延迟到子类 */ abstract Beverage createBeverage(); }
BeverageStoreFactory
package headfirst.hd.dep; //工厂方法模式 public class BeverageStoreFactory extends BeverageStore{ @Override Beverage createBeverage() { //可传入参数,得到更多实例, //或者BeverageStoreFactory2,多个工厂方法,都可以 return new Juice(); } }
测试Client
package headfirst.hd.dep; public class Client { //优秀啦,一点都没有低层模块代码 public static void main(String[] args) { BeverageStore store = new BeverageStoreFactory(); store.saleBeverage(); } }
理解加入模式前后的不同
加入前
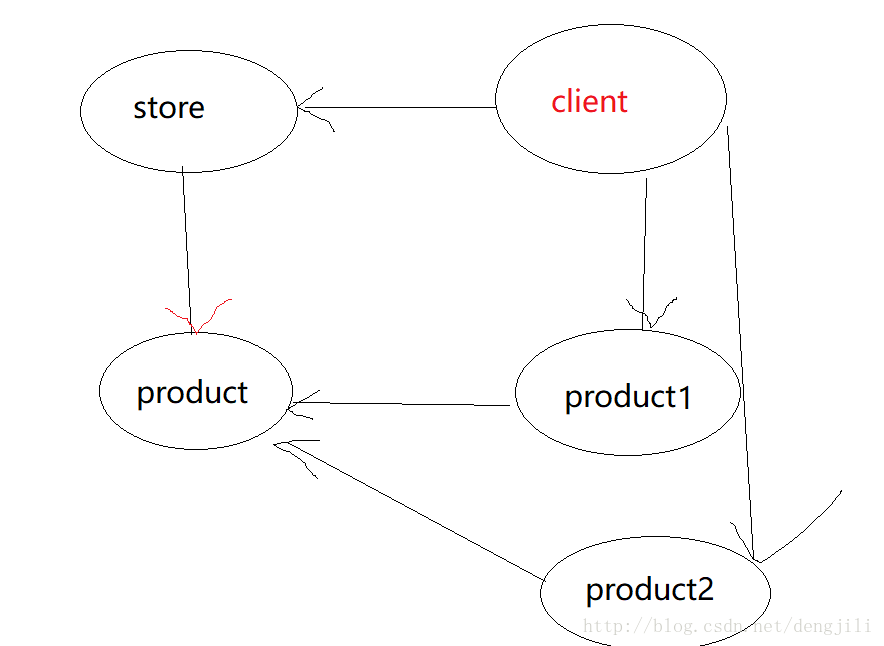
加入后

主要区别体现在两点
- store与product关系
加入工厂前,实际上还是具有依赖关系,实质上将依赖关系往更高层转移
package headfirst.hd.dep; //这是网上最常见方式 public class BeverageStore { //卖果汁 public Beverage saleBeverage(Beverage beverage) { //做一些其他操作 return beverage; } }
//工厂方法模式 public abstract class BeverageStore { //卖果汁 public Beverage saleBeverage() { //直接使用自身定义的抽象方法 Beverage beverage = createBeverage(); //做一些其他操作 return beverage; } /** * 抽象类BeverageStore抽象方法定义,Beverage createBeverage() * 表明createBeverage与BeverageStore为一体,关系为一根横线, * 两者没有实质依赖关系,因为在BeverageStore中,直接使用自身 * 定义方法createBeverage,在类BeverageStore的其他方法中, * 直接使用该类型,具体实现具体类,延迟到子类 */ abstract Beverage createBeverage(); }
所有加入前还是具有依赖关系,所以是箭头,加入工厂模式之后,为接口定义,为一体,所以属于直线
2. storefactory取代了Client位置
加入前层级关系

加入后层级关系

倒置的两种理解
第一种,从设计上理解

如果所示,正常都是高层调用低层,简单推理一下
- product1(具体的实现)依赖于product(抽象)
- 由于引入工厂模式后,store与product为同一关系(同时存在)
- 推理出,product1(具体的实现)依赖于store
因此,形成了依赖倒置的现象
第二种,从思想上理解
没有引入工厂方法模式之前,我们需要一杯果汁(Juice),我们的思路时候这样的
先有一个饮料店(BeverageStore),然后才会有果汁(Juice),简单的说就是先有饮料店,最后决定卖什么饮料
引入工厂方法模式之前,我们需要一杯果汁(Juice),我们的思路时候这样的
先定义饮料接口,后实现具体的饮料店,这些我们可以理解为,我们先选择什么要的饮料,最后决定开什么样的饮料店
因此,形成了依赖倒置的现象