Problem:
Describe the difference between process and project metrics in your own words.
Answer:
Software process and project metrics are quantitative measures that enable software engineers to gain insight into the efficacy of the software process and projects that are conducted using the process as a frame work.
Process metrics are used to make strategic decisions about how to complete common process frame work activities. And also it is used to assess the activities that are used to engineer and build computer software.
Project metrics are used to monitor progress during a software development project and to control product quality. And it is also used to assess the status of a software project
Metric of project allows.
- Of the state of the project in court evaluates
- Of finds the risk potential
- To adjust the work flow
Problem:
Why should some software metrics be kept “private”? Provide examples of three metrics that should be private. Provide examples of three metrics that should be public.
Answer:
Metric:-
The extent or degree to which a product possesses and exhibits a quality, a property or an attribute.
Private metrics are used to measure the efficiency of an individual.
Private metrics:-
1) Defect rates by individual
2) Defect rates by module
3) Errors found during development.
The personal software process is a structured set process descriptions. Measurements and methods that can help engineers to improved scripts and standards that help them estimate and plan their work. It shows them how to define processes and how to measure their quality and productivity.
Private process data can serve as an important drivers as the individual software engineer works to improve.
Public metrics:-
Public metrics generally assimilate information that originally was private to individuals and teams.
Project level defect rates, effort, calendar times and related data re collected and evaluated in an attempt to uncover indicators that can improve organizational process performance.
Problem:
What is an indirect measure, and why are such measures common in software metrics work?
Answer:
Indirect measure:-
An indirect measure is the product includes functionality, quality, complexity, efficiency, reliability, maintainability, and many other quality attributes.
It is used when the characteristic to be assessed cannot be measured directly. For example, "quality" cannot be measured directly, but only by measuring other software characteristics.
Many metrics in software work are indirect because software is not a tangible entity where direct dimensional or physical measures (e.g., length or weight) can be applied.
Some examples:
Indirect measures:
1. Readability (use the FOG index)
2. Completeness (count the number of "help desk" questions that you receive)
3. Maintainability (time to make a documentation change)
However the quality and functionality of the software or its efficiency or maintainability are more difficult to assess and hence are measured indirectly.
Problem:
Grady suggests an etiquette for software metrics. Can you add three more rules to those noted in Section 32.1.1?
Answer:
Additional rules of etiquette:
(i) The metrics must be used as data on the experiment of a team in a history of the project.
(ii) Be sure to measure consistently so that you are not comparing apples and oranges
(iii) Don’t look for the perfect metric ... it doesn’t exist;
Problem:
Team A found 342 errors during the software engineering process prior to release. Team B found 184 errors. What additional measures would have to be made for projects A and B to determine which of the teams eliminated errors more efficiently? What metrics would you propose to help in making the determination? What historical data might be useful?
Answer:
Additional measures for project A&B are
In size – oriented metrics the lines of code may be chores as normalization value.
1) Size Oriented metrics are:
-Errors per KLOC
-Defects per KLOC
-$ per LOC
-Page of documentation per KLOC
Size oriented metrics are not universally accepted as the best way to measure the process of software development.
2) Function oriented software metrics.
Use a measure of the functionality delivered by application as a normalization.
Errors per function poun’t
Defects per FP
$ per FP
Pages of documentation per FP
FP per person month
It would have been important to know how much person worked in each beam and how long this work their took, to able to determine which beam was most effective.
I would add the number of lines of code through the proposed below metrics for making the determination.
Equip | LOC | effort | nobody
With A – 342
B - 184
Problem:
Present an argument against lines of code as a measure for software productivity. Will your case hold up when dozens or hundreds of projects are considered?
Answer:
Lines of code, it’s about the differences between languages, different counting styles, and differences due to formatting conventions. But even if use a consistent counting standard on programs in the same language, all auto – formatted to a single style –
A line of code still doesn’t measure output properly.
Problem:
Compute the function point value for a project with the following information domain characteristics:

Assume that all complexity adjustment values are average. Use the algorithm noted in Chapter 30.
Answer:
To compute function points (FP), the following relationship is used:
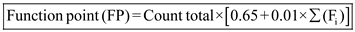
Where count total is the sum of all FP (Function point) entries obtained from the table
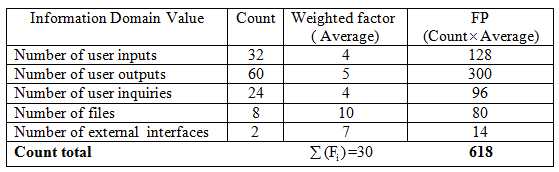
As it is given that, all complexity adjustment values are average we take, [above table contain weight factor as average].
Value adjustment factors  = total of average
= total of average
Therefore,  = 30
= 30
Now we calculate the function point using,
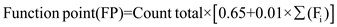
=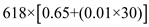
=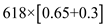
=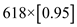
=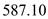
Therefore, the function point = 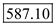
Problem:
Using the table presented in Section 32.2.3, make an argument against the use of assembler language based on the functionality delivered per statement of code. Again referring to the table, discuss why C++ would present a better alternative than C.
Answer:
From the table presented in Section 22.2.3, number of lines of assembly language code required to implement a function point ranges for 91 to 694 with an average of 337.
And median lines of code are assembler is 315.
Here, a Low line of code in assembler is 91 and High lines of code in assembles is 694.
These are among the largest values in the table.
Some industry analysts have claimed that most programmers deliver the e number of debugged lines of code per day regardless of the language used.
If this were true implementing a project using assembly language would take more time than almost any other language. A similar argument could be made for using C++ (average LOC/FP = 66) rather than C (average LOC/FP = 162).
Problem:
The software used to control a photocopier requires 32,000 lines of C and 4,200 lines of Smalltalk. Estimate the number of function points for the software inside the copier.
Answer:
The software used to control a photo copier requires - 32,000 of C
The software used to control a photo copier requires - 4200 of small tall.
Take the data from the table in Section 22.2.3,
for C = 162 LOC/FP
for Smalltalk = 26 LOC/FP
Therefore,
= 32,000/162 + 4,200/26
= 197.53 + 161.54
= 359 FP (approximate)
Problem:
A Web engineering team has built an e-commerce WebApp that contains 145 individual pages. Of these pages, 65 are dynamic; that is, they are internally generated based on end-user input. What is the customization index for this application?
Answer:
A web engineering team has built an E-Commerce web App that contains 145 individual pages and 65 are dynamic.
That is static pages = total # of pages - # dynamic pages
# static pages = 145 – 65 = 80
Customization index for this web application is
C = # static pages / total # pages
= 80 / 145
= 0.55
Problem:
A WebApp and its support environment have not been fully fortified against attack. Web engineers estimate that the likelihood of repelling an attack is only 30 percent. The system does not contain sensitive or controversial information, so the threat probability is 25 percent. What is the integrity of the WebApp?
Answer:
Integrity:-
Software integrity has become increasingly important in the age of cyber terrorists and hackers. This attribute measures a system’s ability to with stand attacks to its security. Attacks can be made on all three components of software programs data and documents.
To measure integrity, two additional attributes must be defined.
Threat and security.
Threat is the probability that an attack of a specific type will occur with in a given time security is the probability that the attack of a specific type will be repelled.
The integrity of a system can be defined as
Integrity: 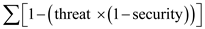
Repelling attack: 30%
Probability: 25 %
Integrity 
Integrity = 1 – [0.25 * (1 – 0.3)]
= 1 – [0.25 * 0.7]
= 1 – 0.18
= 0.83 approx
Problem:
At the conclusion of a project, it has been determined that 30 errors were found during the modeling phase and 12 errors were found during the construction phase that were traceable to errors that were not discovered in the modeling phase. What is the DRE for these two phases?
Answer:
The DRE or defect removal efficiency is used to assess he ability of a team to determine errors before the errors are passes o the upcoming engineering activity. DRE is thus defined as:
DREi = Ei / Ei + Ei+1
Here, Ei represent the errors found in an engineering task i, and Ei+1 represent the errors found in engineering task i+1, that were not discovered during task i.
Given that Ei = 30 and Ei+1 = 12, DRE can be calculated as:
DRE = 30 / 30 + 12
Or, DRE = 30 / 42
There fore DRE is 0.7143.
Problem:
A software team delivers a software increment to end users. The users uncover eight defects during the first month of use. Prior to delivery, the software team found 242 errors during formal technical reviews and all testing tasks. What is the overall DRE for the project after one month’s usage?
Answer:
4633-25-13P SA: 9420
SR: 6376
Given that,
Defects found during the first month of use = 8
The errors found during formal technical reviews = 242
That means,
Errors uncovered during work to make change, 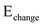 = 242
= 242
Defects uncovered after change is released to the customer base, 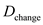 = 8
= 8
Therefore, Defect Removal Effectiveness (DRE) can be computed as

= 242 / 242 + 8
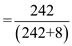
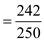
= 0.968
Hence the overall DRE for the project after one month’s usage = 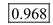
Solution: Chapter32:PROCESS AND PROJECT METRICS
32.1 A process metric is used to assess the activities that are used to engineer and build computer software (with the intent of improving those activities on subsequent projects). A project metric is used to assess the status of a software project
32.2 Metrics should NOT be used as rewards or punishments at an individual level. Hence, any metric that measures individual productivity or quality should be private. Group and process metrics may be public, as long as they are not used for reprisals.
32.3 An indirect measure is used when the characteristic to be assessed cannot be measured directly. For example, "quality" cannot be measured directly, but only by measuring other software characteristics. Many metrics in software work are indirect because software is not a tangible entity where direct dimensional or physical measures (e.g., length or weight) can be applied. Some examples:
Direct metrics:
- number of pages
- number of figures
- number of distinct documents
Indirect measures:
- readability (use the FOG index)
- completeness (count the number of "help desk" questions that you receive)
- maintainability (time to make a documentation change)
32.4 Additional rules of etiquette:
-
- don’t look for the perfect metric ... it doesn’t exist;
- be sure to measure consistently so that you are not comparing apples and oranges
- focus on quality, it’s safer!
32.5 The "size" or "functionality" of the software produced by both teams would have to be determined. For example, errors/FP would provide a normalized measure. In addition, a metric such as DRE would provide an indication of the efficiency of SQA within both teams’ software process.
32.6 LOC is weak because it rewards "verbose" programs. It is also difficult to use in a world where visual programming, 4GLs, code generators and other 4GTs are moving development away from 3GLs.
32.7 Using the algorithm noted in Chapter 23 with average values for complexity and average values for each CAF, FP = 661.
32.8 The number of lines of assembly language code required to implement a function point ranges for 91 to 694 with an average of 337. These are among the largest values in the table. Some industry analysts have claimed that most programmers deliver the same number of debugged lines of code per day regardless of the language used. If this were true implementing a project using assembly language would take more time than almost any other language. A similar argument could be made for using C++ (average LOC/FP = 66) rather than C (average LOC/FP = 162).
32.9 From the table in Section 32.2.3,
for C = 162 LOC/FP
for Smalltalk = 26 LOC/FP
Therefore, 32,000/162 + 4,200/26 = 197.53 + 161.54 = 359 FP (approximate)
32.10 # static pages = total # of pages - # dynamic pages
# static pages = 145 – 65 = 80
C = # static pages / total # pages = 80 / 145 = 0.55
32.11 integrity = 1 – [threat * (1 – security)]
integrity = 1 – [0.25 * (1 – 0.3)] = 1 – [0.25 * 0.7] = 1 – 0.18 = 0.83 approx.
32.12 DRE = E / (E + D) = 30 / (30 + 12) = 30 / 42 = 0.71 approx.
32.13 DRE = E / (E + D) = 242 / (242 + 8) = 242 / 250 = 0.97 approx.