1 背景
自然语言处理(NLP)过程可以分为自然语言理解(NLU)和自然语言生成(NLG),NLU负责理解文本内容,而NLG负责根据信息生成文本内容,该内容可以是语音、视频、图片、文字等。本文内容承接于前面两次的内容,在从训练集得到seq2seq模型后,需要对模型的性能进行评估。其中,评估的一个重要过程就是,根据对模型生成的内容进行评估,即NLG过程。
2 NLG简介
2.1 如何进行文本生成?
文本生成可大体分为三个步骤:
- 在时间步\(t\),我们的模型(LM)为词汇表中每个词,输出一个分数值
- 将词汇表长度的分数值输入到\(softmax\)函数,得到词汇表长度的概率分布
- 根据解码算法,依据概率分布选择下一个时间不\(t + 1\)的词汇

2.2 如何进行解码?
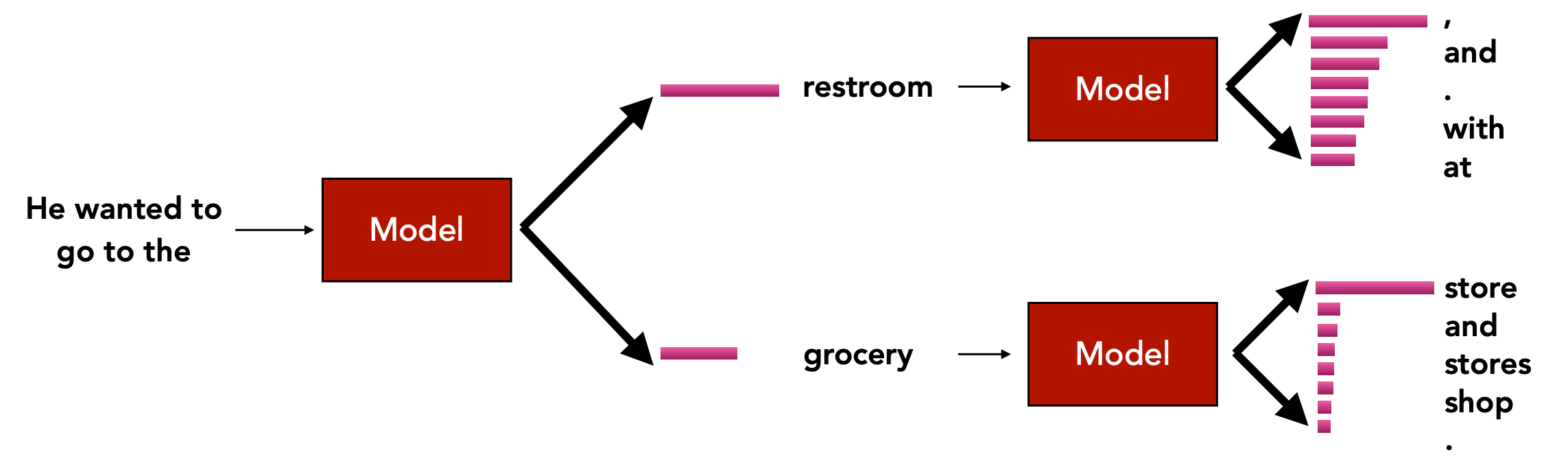
我们的解码算法可以看作是一个函数,该函数根据概率分布,输出一个符合一定条件的token。
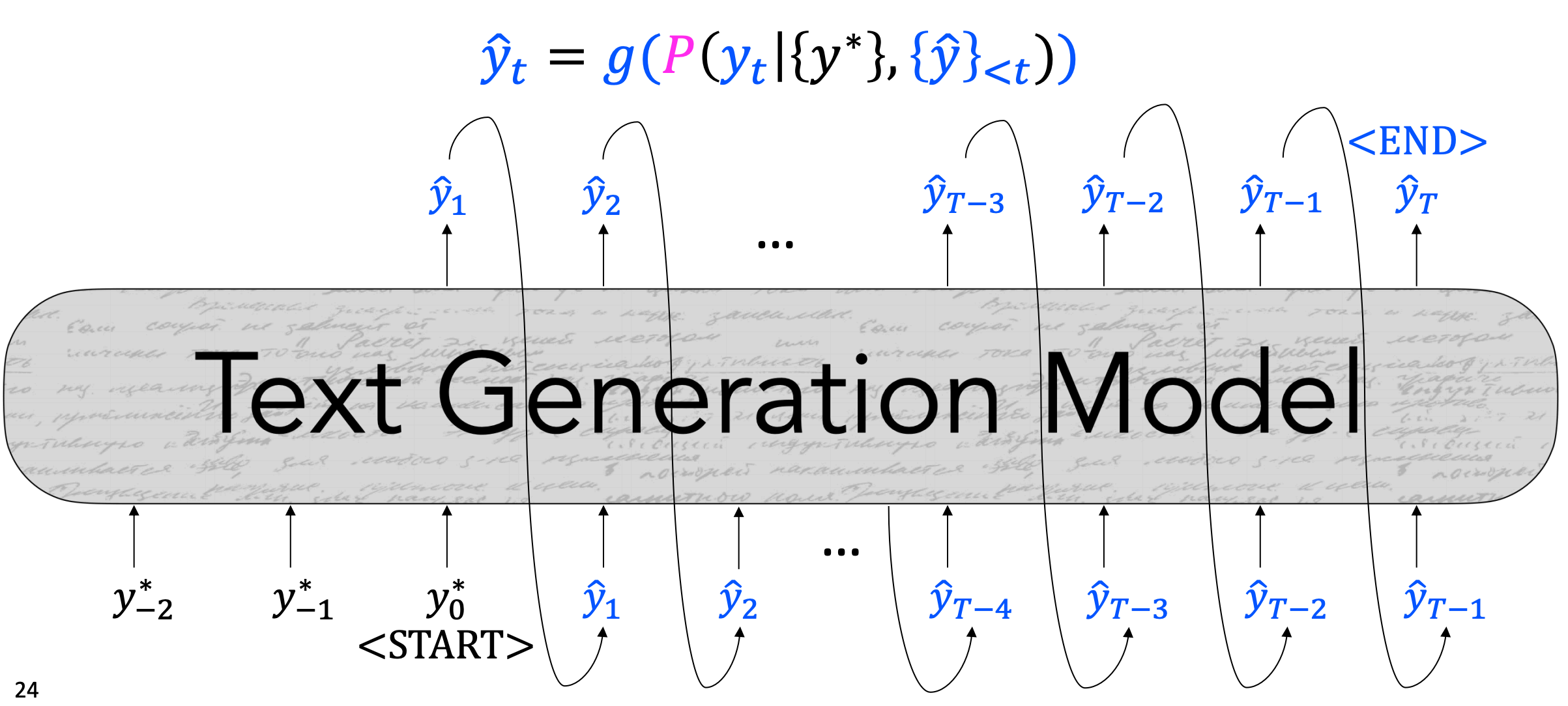
如上图,生成模型根据输入的token,输出一个下一个时间步的token,重复过程,直到满足一定的停止条件。
函数g可看作为解码算法,其参数为LM模型输出的概率分布。
2.3 基于穷举搜索的解码算法
理想状态下,我们期望得到一个长度为\(T\)的翻译结果\(y\),\(y\)满足在每个时间步\(t\)都是最优的选择。如下:
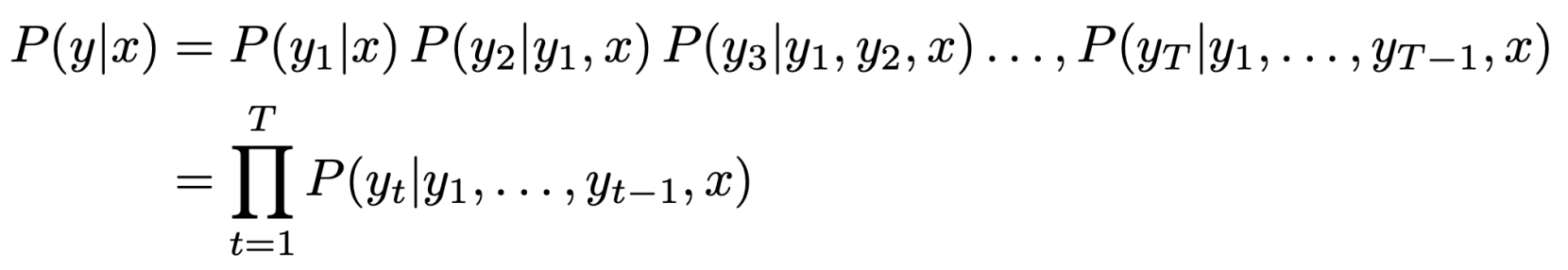
我们可以尝试对上述条件概率进行优化,以得到所有可能的序列结果\(y\),这意味着,在每个时间步\(t\)进行解码时,我们都有\(v\)种可能的选择,\(v\)为词汇表长度。因此,整个计算计算复杂度为\(O(v^{t})\),计算成本很高。
3 NLG解码策略和tricks
理想状态下(2.3)的时间成本和计算成本对于寻找最优子序列\(y\)来说都比较高,因此尝试寻找一直高效率的解码方式。
3.1 Greedy Decoding
Greedy Decoding的原理较简单,即每个时间步\(t\),依据概率分布,选择概率最大的词,作为生成的结果,数学表达如下:

具体过程如下:
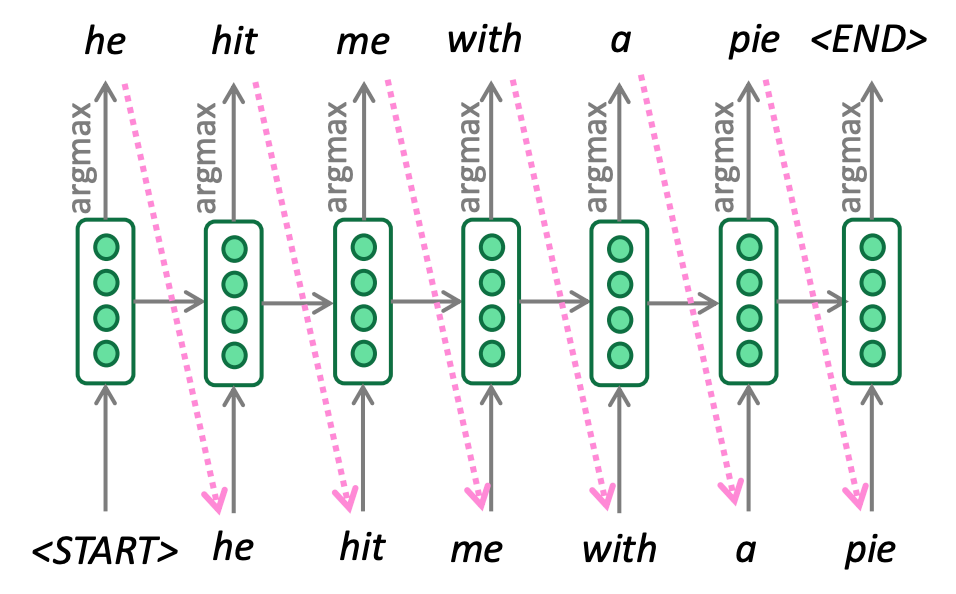
贪心解码的停止条件为当模型生成了表示结束的token
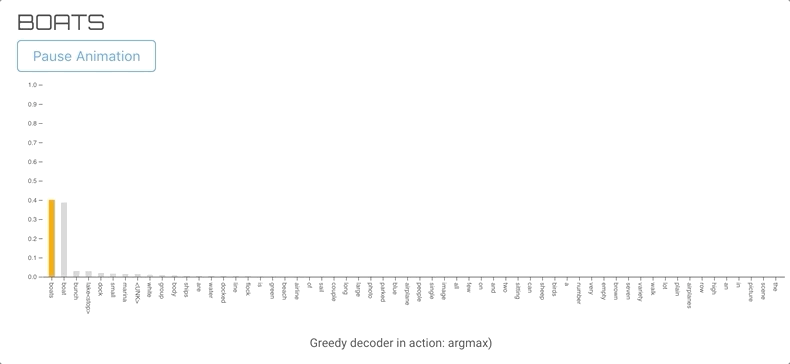
贪心解码的问题在于,当词汇表中只有某几个词汇的概率占很大比例时,生成的结果可能会一直选择那几个词,结果不断生成重复的词汇。
3.2 Beam Search Decoding
Beam Search的核心思想在于,它不是在每一步选择概率最大的一个词,而是选择概率最大的K的词,并依据其每一个step的概率乘积(往往转化为log的加法形式)作为当前步的打分,在最终生成的子序列中选择分数值最大的K个。其数学表述如下:
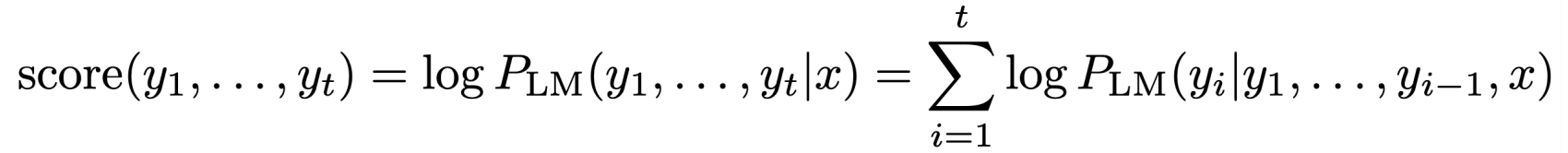
Beam Search不保证一定能找到最优解,但是相对与穷举,它极大的提升了效率;相对于Greedy Search来说,它增大了寻找到最优子序列的概率。

Beam Search算法在每个时间步\(t\)都可能产生停止迭代的符号(hypothesis)产生该符号时,认为已经生成一个完整的序列,并继续生成其他子序列。
一般情况下,Beam Search的停止条件为达到停止生成时间步长T的序列,或这生成若干个hypothesis时,不在继续迭代。
Beam Search中不同K的大小对生成结果有什么影响呢?
- 当
K=1时,Beam Search算法退化为Greedy Search算法 - 当
K较小时,往往和Greedy Search具有类似的问题,例如不符合语法、不通顺甚至错误字符等等。 - 当
K较大时,意味着生成更多的Hypothesis,因此增加K值能够一定程度上缓解上述问题,但也因此需要更多的计算资源。 - 同时,
K值的增大,也可能带来其他问题。如NMT问题中,K值增大可能较弱BLEU分数,这是因为Large K使得生成的结果往往较短。

上图表示在对话系统中,随着K值的增大,生成的语义越来越符合语法结构等,但是也往往偏离主题;而在K较小时,会出现一语法的错误,但是还能一定程度上和主题相关。
Beam Search产生的结果中,主要存在两个问题:重复和短句。因此,也有一些针对这两个问题的解决方案。
如何处理生成句子较短的问题呢?
减小对生成长句子的惩罚!!

在原来的目标函数中,短句子往往能得到较高的分数,因此可以考虑从目标函数入手,减弱对生成长句子的惩罚。
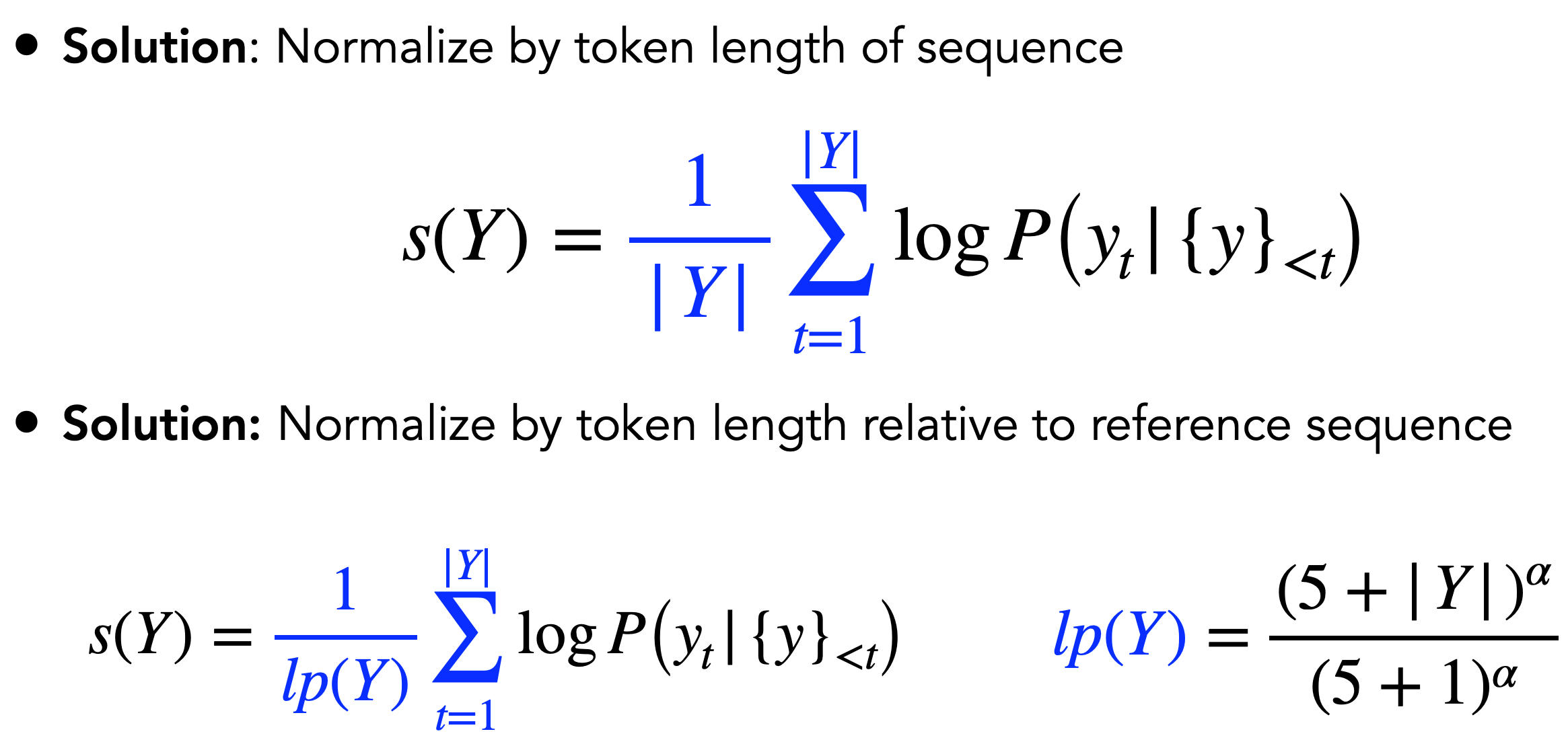
如何处理生成句子中重复较多的问题?
重复时语句生成过程中的一个比较严重的问题。那么,为什么会出现这种问题呢?有文章表明,是因为随着时间步的增长,负的log概率值,会逐步衰减。
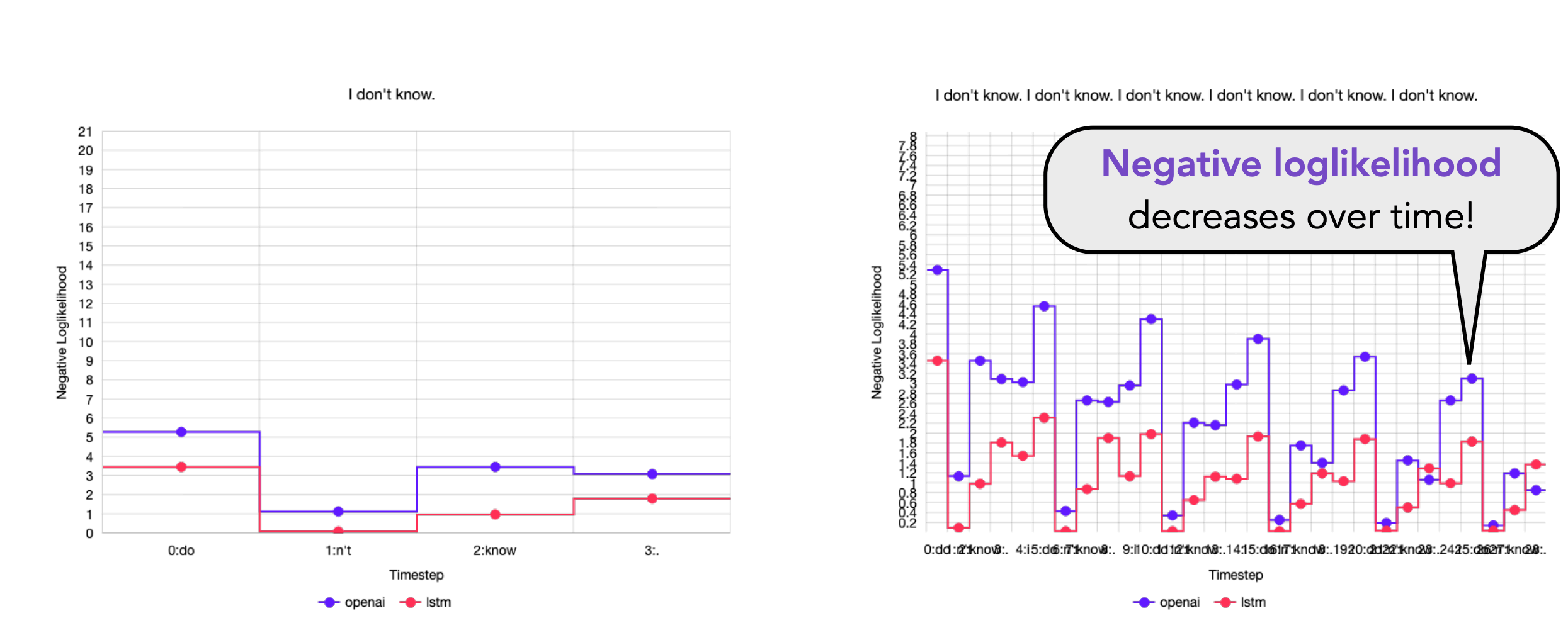
因此,有研究者提出以下方法解决该问题。

方法1旨在较少n-grams元组的出现;方法2在原损失函数中添加惩罚项,对隐变量的相似度进行惩罚,使得隐变量尽可能具有区分度。

该方法对已出现过的tokens进行惩罚,其损失函数如下:

该方法和前面三种方法类似,也是在训练过程中,对目标函数进行了一定的修改。前面两种方法,分别是对损失值取均值、取标准化、减去隐变量的相似度;而该方法时惩罚已出现过词的似然概率。公式中\(y_{neg}\)代表已出现过的词,希望降低这些词在文本中出现的概率。
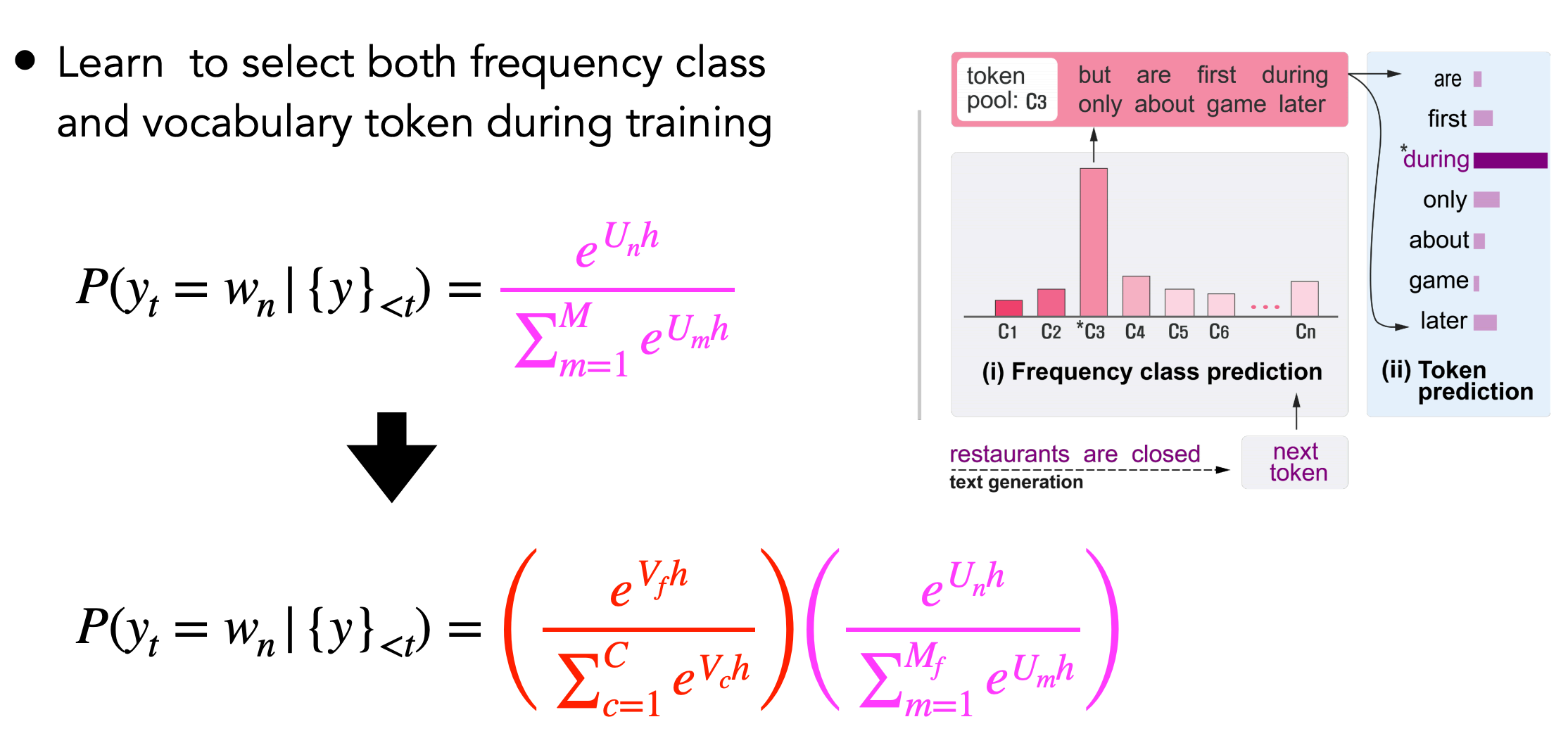
其他方法如\(F^{2} softmax(Frequency Factorized Softmax)\)是借鉴了矩阵分解的思路,对训练过程中的频率分布进行调控。
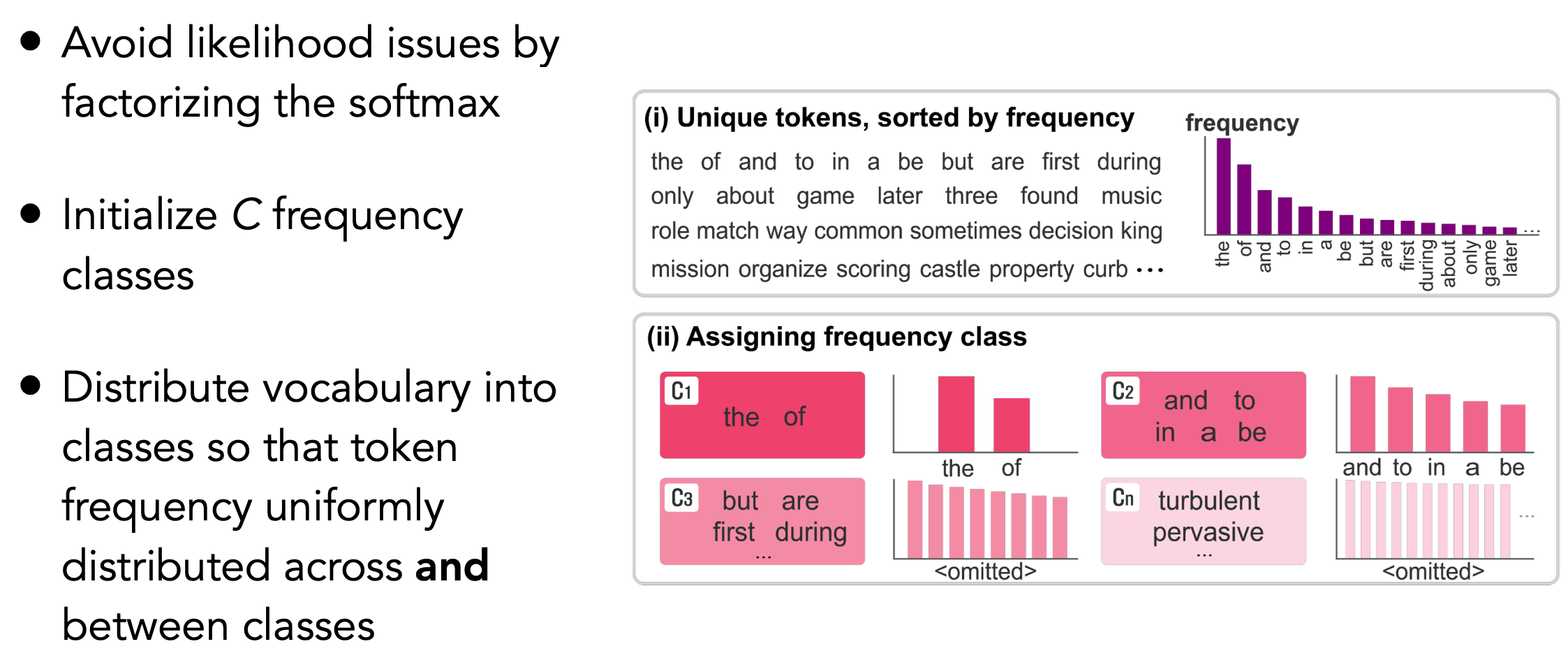
该方法的思路是:
- step1,将词汇表中所有词,按照出现频率进行从高到底进行排序
- step2,将排序后频率表,分为\(C\)类,\(C\)为手动设定的类别
- step3,将分成\(C\)类后的词汇表送入到\(softmax\)中,得到不同类别的概率分布
- step4,最后对每个不同类别中的不同词汇取一次\(softmax\)。
因此,在进行生成时,首先根据类别的概率分布确定属于哪一个类别;然后根据类别中各个词汇的分布,确定取哪一个词。
4 采样策略
尽管以上方法分别从解码算法和损失函数的角度对文本生成进行了改进和提升,但是依然存在很多问题。例如,Beam Search中,我们期待每一步都得到最大的的可能性,但是人类在做生成的过程时,往往并不是这样。
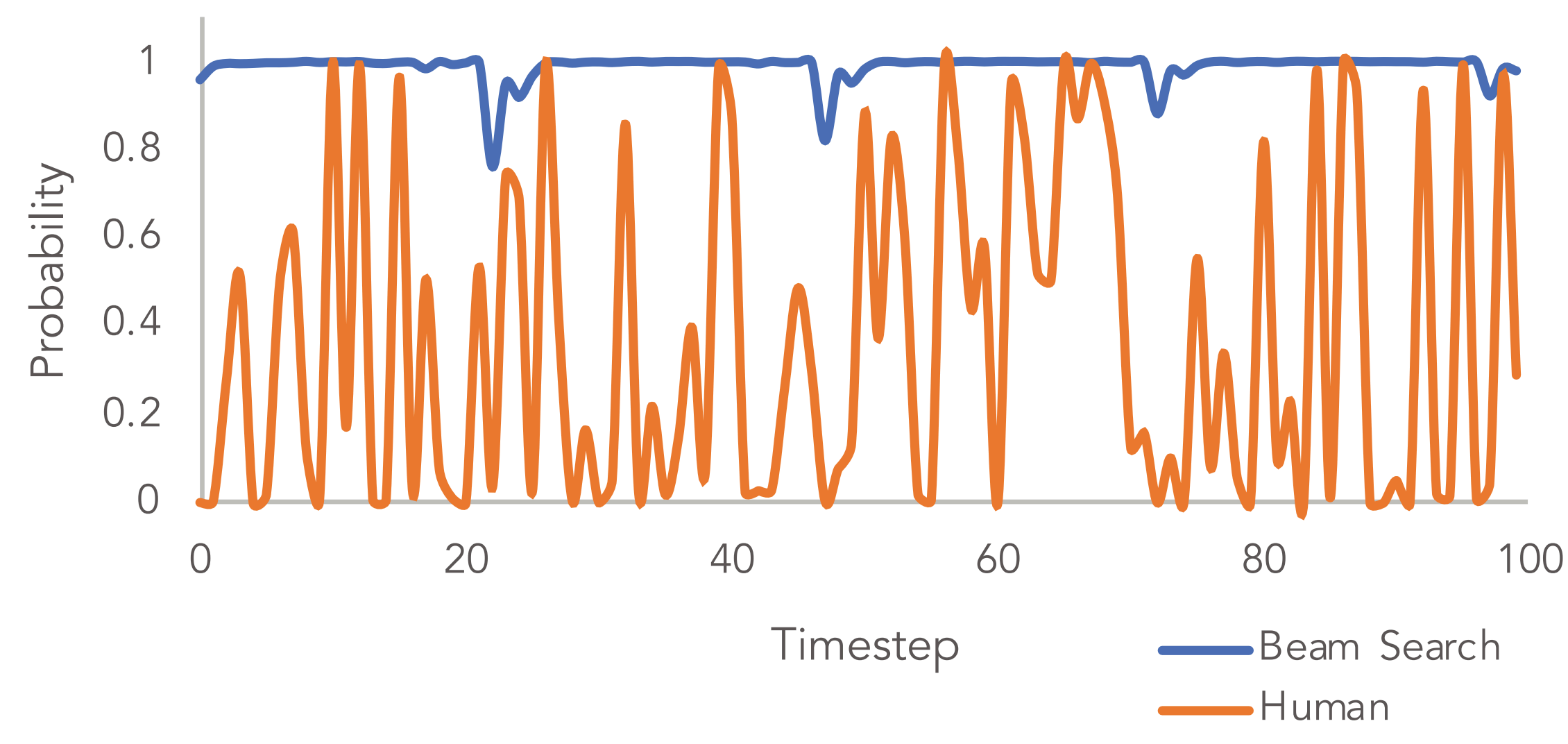
从上图中可以看出,人类在每一个step时,生成的结果更具有随机性,而不是beam search中每个step都期望可能性最大。因此,引出了基于随机性采样(sampling)的生成方式。
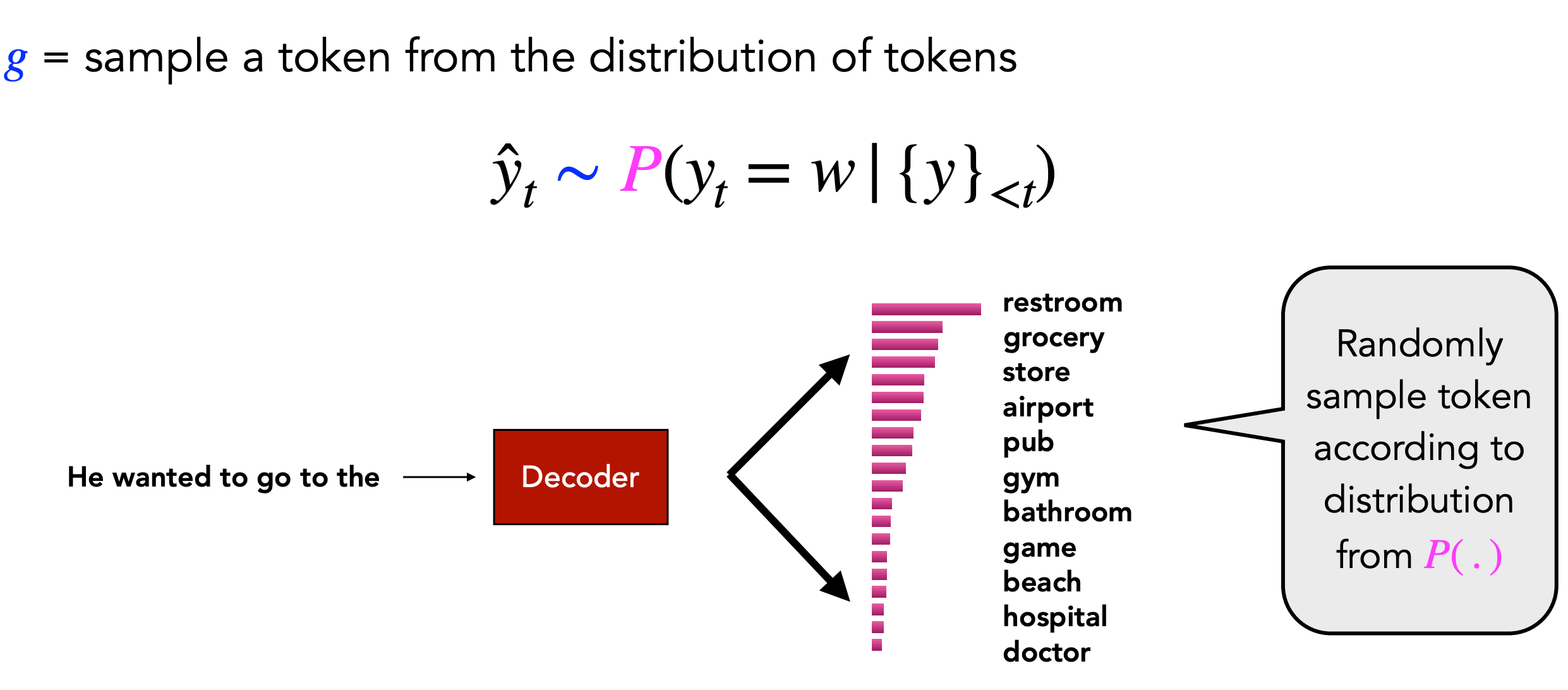
基于采样的思想是指,从生成的词汇表的概率分布中,依据一定的策略,来得到生成结果。
4.1 Temperature Sampling
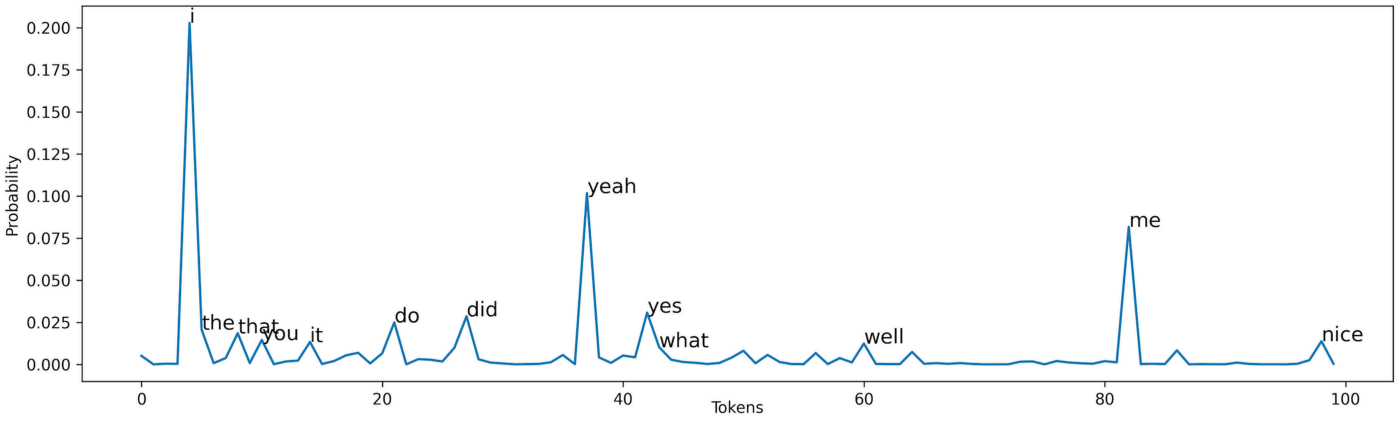
    基于随机采样的生成方式,往往需要在随机性和生成结果之间平衡。当随机性过高时,意味着分布的不确定(entropy)较高。 temperature sampling的方法时对概率分布的概率值进行放大,使得概率越大的词,越容易被采样到。

其数学表述为:
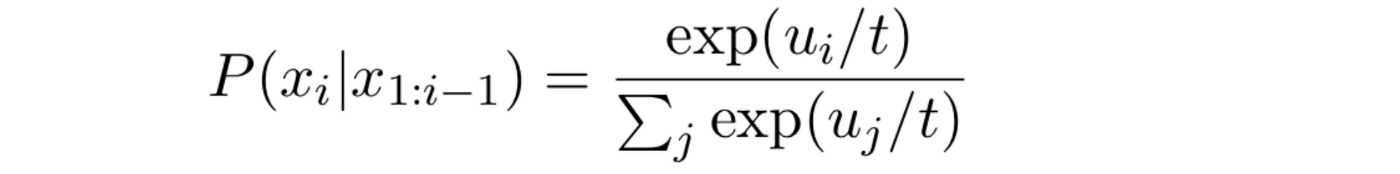
上述函数的意思是,将LM输出的概率分布中,每个分数值\(u_{i}\)再除以一个特定参数\(t\),得到的结果重新计算一下\(softmax\),然后依据此分布进行采样。
当\(t\) > 1时,P的分布会变得更加均匀,生成结果更具有多样性;当\(t<1\)时,P的分布会变得更加毛刺,生成的词汇会集中出现再处于毛刺尖尖的上单词,因此生成的多样性会降低。
4.2 Top k sampling

Top k算法认为,每一步的生成结果,只需要集中再概率分布较大的区域就行。因此,该算法首先将概率分布中前K个概率所对应的词汇,而丢弃其他部分的词汇;然后对前K个概率值进一步通过一个softmax函数,得到新的概率分布;最后,从新的概率分布中采样得到最终生成的词汇。
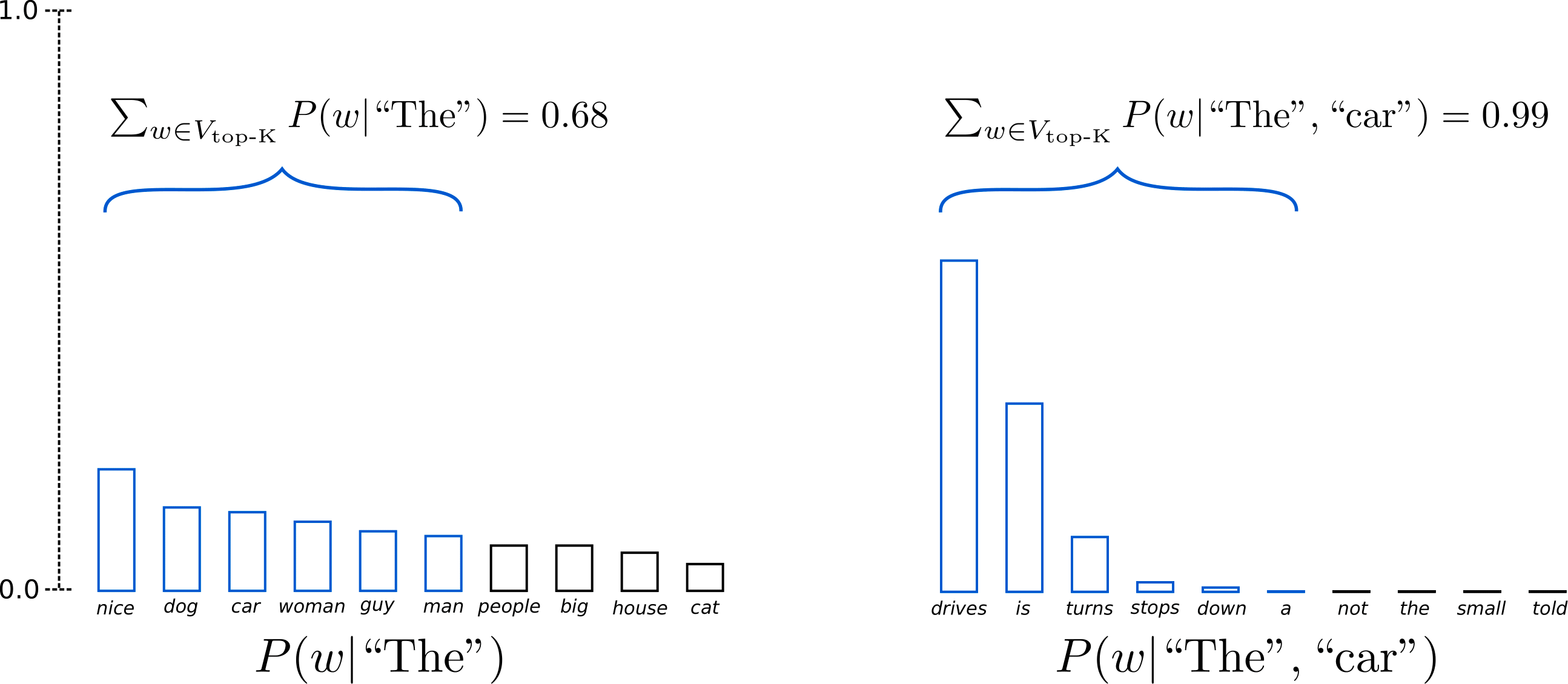
该算法的一个主要问题在于,当概率分布中,不同词汇概率分布相近时,丢弃的词汇就会较多,导致可选择的词汇较少。
4.3 Top P sampling

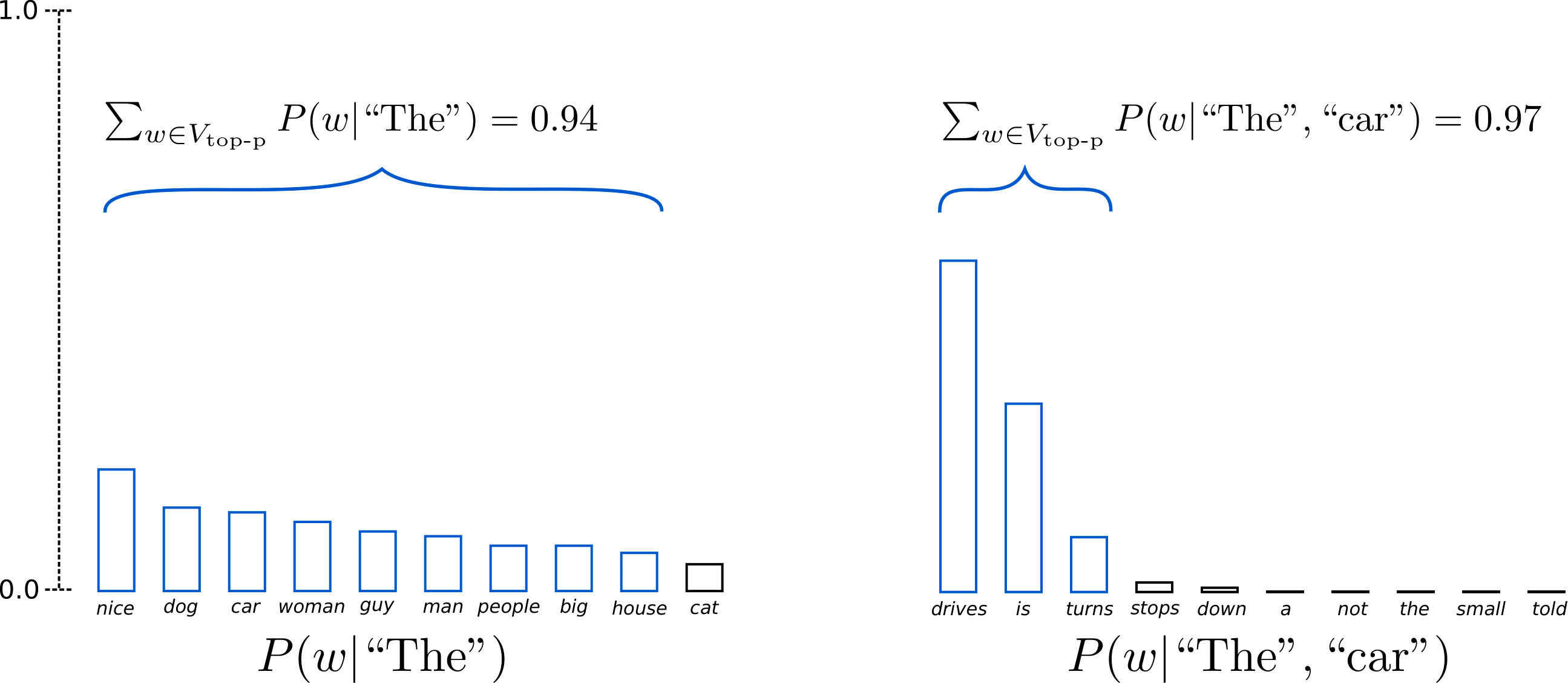
top p算法认为无法确定生成过程中,多少个可供选择的词汇是合适的,因此使用累计概率进行选择。该算法的思路是,选择累计概率达到一定阈值的词汇,作为候选词。然后对这些词重新进行概率分配,得到新的概率分布,并依据新的概率分布进行词的生成。
5 模型评估
模型评估是指,对模型生成的文本内容的质量进行衡量。
5.1 Rouge-N评估
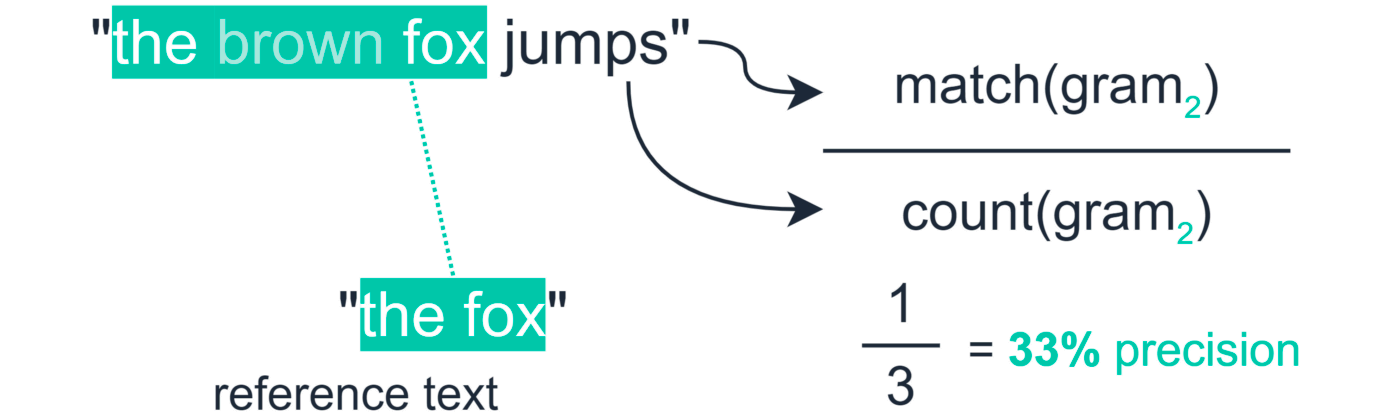
Rouge-N测量的是模型生成的文本,与inference文本之间生成的n-grams匹配的数量。

其准确率(precision定义为在模型生成的文本和inference文本中同时出现的n-grams数量与模型生成的n-grams数量的比值。


其召回率(recall)定义为在模型生成的文本和inference文本中同时出现的n-grams数量与inference文本中的n-grams数量的比值。


F1-score定义如下:
5.2 Rouge-L评估
Rouge-L评估衡量的是模型生成结果与inference文本中共同出现的最长子序列的数量。
准确率(precision)计算:
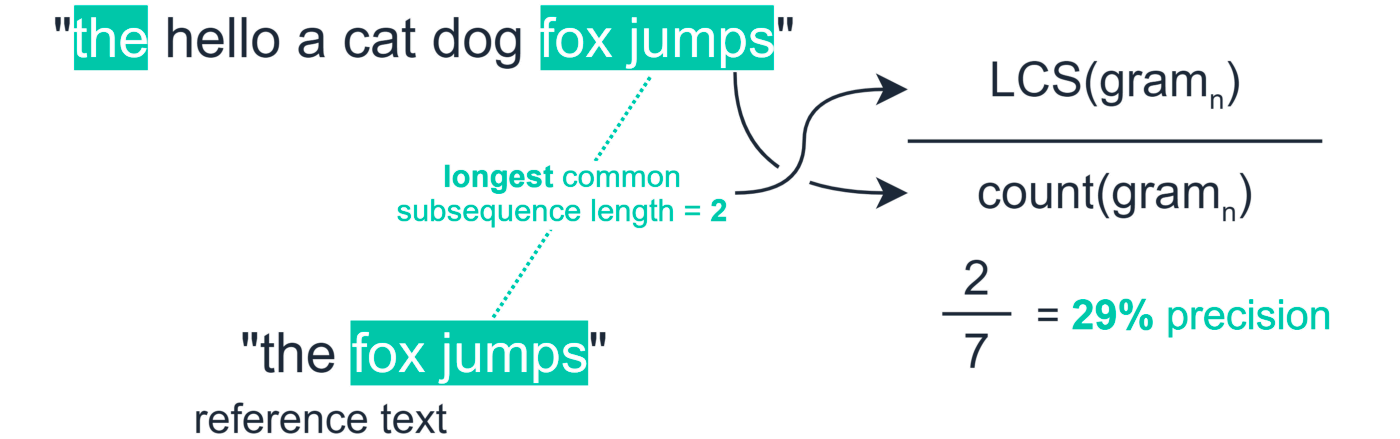
其中,分母为生成的序列的长度,分子为最长共同序列的长度。其他如recall、F1-score类似指标计算类似。
5.3 Rouge-S
即利用skip-gram,不要求gram之间必须是连续的,可以跳过几个词。例如,skip-bigram,在产生grams时,允许最多跳过两个词。
比如'cat in the hat',那么'cat in ,cat the, in the, in hat, the hat'都认为是正确的bi-gram。