反爬虫
反爬虫:就是使用任何技术手段阻止批量获取网站信息的方式;其实我们做的就是了解反爬虫的技术,继而反反爬虫。
反爬虫的方式
(1)不返回网页;
- 网站通过ip访问量反爬虫,对访问进行统计,单个ip访问量超过阈值,则封杀或者输验证码;
- 通过session(会话控制)访问量反爬虫,session对象存储用户会话所需属性和配置信息,用户在web页跳转,存储在session中变量不会丢失,而是在整个会话中一直存下去,如果一个session的访问量过大,就会进行封杀或者输验证码;
- 通过User-Agent反爬虫,当用requests库进行爬虫,默认的User-Agen为python-requests/(xxx),服务器判断其不是真正的浏览器会予以封杀;
(2)返回非目标网页,如返回错误页、空白页、同一页;
(3)增加获取难度,如登录及验证码、12306登陆选图片;
反反爬虫
(1) 修改请求头
如果不修改请求头,网页默认为python-requests/xxx,所以需要修改;也可以做一个User-Agen 的池,但针对User-Agen的访问量进行封锁的不多,一般设置为正常的浏览器的user-Agen就好了。
# encoding:utf-8
import requests;
link='http://www.santostang.com/';
r=requests.get(link);
print (r.request.headers);
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'};
r=requests.get(link,headers=headers);
print (r.request.headers);
headers,修改前后对比:

(2)修改爬虫的间隔时间
- 爬虫过于频密,对网站很不友好,或者导致网站的反爬虫。可以使用time 库在爬虫访问之间设置一定的间隔时间
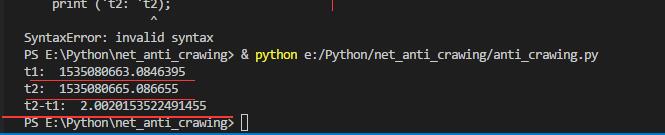
t1=time.time();
print ('t1: ',t1);
time.sleep(2);
t2=time.time();
print ('t2: ',t2);
t=t2-t1;
print ('t2-t1: ',t);
加入间隔时间:
- 加入随机的时间,使用一个固定的数字作为时间间隔,不像正常用户的行为,可以使用random库进行随机数设置;random.randint(0,2)的结果是0/1/2,andom.random()是0~1的随机数,相加获得更随意的sleep时间。
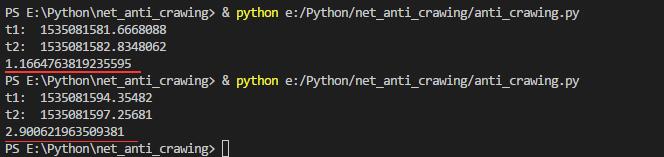
t1=time.time();
print ('t1: ',t1);
sleep_time=random.randint(0,2)+random.random();
time.sleep(sleep_time);
t2=time.time();
print ('t2: ',t2);
print (sleep_time);
运行两次,两次sleep时间不一样,如图
- 爬取网页过程中,加入sleep time,在两次爬虫中添加一定的时间间隔。例如爬取http://www.santostang.com/中多个子网页中的文章题目,考虑到进入子网页也需要爬取该子网页,所以将网页爬取部分封装成函数。
# encoding:utf-8
import requests;
from bs4 import BeautifulSoup;
import time,random;
def scarp_url(link):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'};
r=requests.get(link,headers=headers);
soup=BeautifulSoup(r.text);
return soup;
link='http://www.santostang.com/';#主网页
soup=scarp_url(link);
post_titles=soup.find_all('h1',class_='post-title');
for each in post_titles:
title_link=each.a['href'];#进入到具体的博客文章中
print ("休息一下");
sleep_time=random.randint(0,2)+random.random();
time.sleep(sleep_time);
t1=time.time();
print ("爬取子网页前时间:",t1);
print ("开始爬取具体博客子网页");
soup_title=scarp_url(title_link);
title=soup_title.find('h1',class_='view-title').text.strip();
print ("这篇博客名:",title);
t2=time.time();
print ("爬取子网页后时间:",t2);
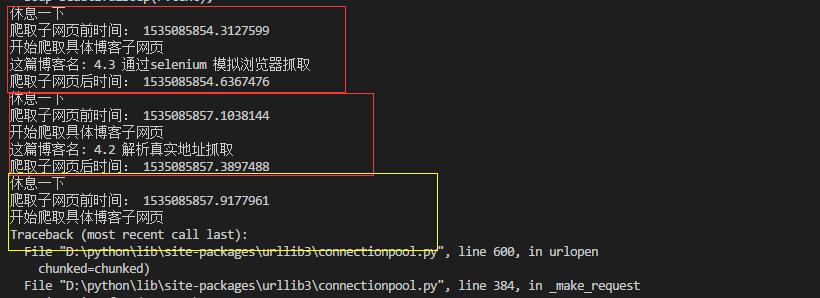
将sleep放在每一个网页更改前,红框中以爬取两个但还是出现错误ConnectionResetError: [WinError 10054] 远程主机强迫关闭了一个现有的连接。 是服务器为了维护自己的安全,对于不正常的浏览网页者做的限制。刚开始不知http://www.santostang.com/是否是网页的问题,因为该网址有网页进入不了。所以更换了一个网址(豆瓣),重新测试。
import requests;
from bs4 import BeautifulSoup;
import time,random;
def scarp_url(link):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'};
r=requests.get(link,headers=headers);
soup=BeautifulSoup(r.text);
return soup;
link='https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4';#主网页
soup=scarp_url(link);
post_titles=soup.find_all('li',class_='subject-item');
for each in post_titles:
info_url=each.find('div',class_='info');
title_link=info_url.a['href'];#子网页的地址
print (title_link);·
print ("休息一下");
sleep_time=random.randint(0,2)+random.random();
time.sleep(sleep_time);
t1=time.time();
print ("爬取子网页前时间:",t1);
print ("开始爬取具体豆瓣具体书本的子网页");
soup_title=scarp_url(title_link);
title=soup_title.find('span',property='v:itemreviewed').text.strip();
print ("这书本名:",title);
t2=time.time();
print ("爬取子网页后时间:",t2);
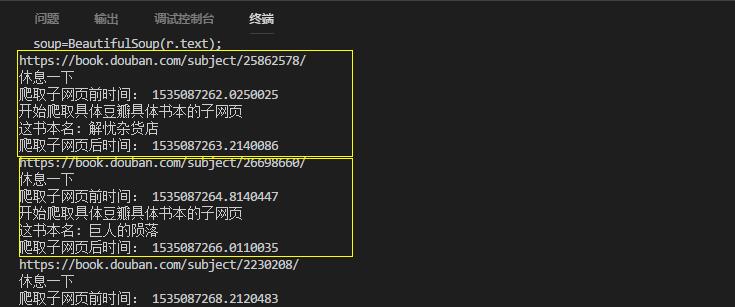
爬取结果,是ok的,所以前面一个网页自己的问题哦;但目前还不知道 遇到这种网页应该怎么办。
- 其实时间sleep 可以放在更换网页切换之间,其实很随意。当然也可以不用每次换网页就休息,可以在每次爬取间隔少点,但是多次爬取后再休息多一点时间,比较符合正常浏览的习惯;
def scarp_url(link):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'};
r=requests.get(link,headers=headers);
soup=BeautifulSoup(r.text);
return soup;
link='https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4';#主网页
soup=scarp_url(link);
post_titles=soup.find_all('li',class_='subject-item');
scrap_time=0; #计算爬取次数
for each in post_titles:
info_url=each.find('div',class_='info');
title_link=info_url.a['href'];
print (title_link);
print ("开始爬取具体豆瓣具体书本的子网页");
soup_title=scarp_url(title_link);
title=soup_title.find('span',property='v:itemreviewed').text.strip();
print ("这书本名:",title);
t2=time.time();
print ("爬取子网页后时间:",t2);
scrap_time+=1;
if scrap_time % 5==0:
sleep_time=10+random.random();
else:
sleep_time=random.randint(0,2)+random.random();
time.sleep(sleep_time);
t1=time.time();
print ("爬取子网页前时间:",t1);
增加一个scrap 次数计数。
(3)使用代理
代理是一种特殊的网络服务,允许一个网络终端(一般为客户端),通过这个服务于另一个网络终端(一般为服务器)进行非直接的连接,其实就是信息的中转站。比如,直接访问国外的网站速度很慢,就可以用国内的代理服务器中转,数据先从国外某网站到国外的代理服务器,再到计算机,反而会比较快。
因此在爬虫过程中,可以维护一个代理池,让自己的爬虫程序隐藏自己的真实ip。但是代理ip池较难维护,且不稳定。使用代理ip获取网页的方法,模板如下:
import requests;
link='http://www.santostang.com/';
proxies={'http':'http://xxx.xxxxx.xxxxx',...};#就是多个IP地址的字典
response=requests.get(link,proxies=proxies);
NOTE
- 代理池,具体没有试过。但应该就是在request.get()中,加个代理池的参数吧。后期用到再查资料吧。
- 反反爬,可以从headers和sleep中,估计可以搞定蛮多平时的练习网站了吧。
- 听说后面还有更换ip、处理登陆表单和验证码。后面入坑再说吧。