之前一直觉得这个机器学习就是把一堆数据扔给机器(代码)然后它能产生出新的神奇来,不过很多事情只有做了才能了解它大概是个什么东西
首先去Kaggle上找数据,一般数据挖掘这块,基本上至少有一个训练集和一个测试集,
下载这个train和test文件,是不是觉得很熟悉,这跟KNIME做决策树,贝叶斯的数据挖掘的流程很相似
网站上还有关于数据的一个解释,显示如下:

scikit 机器学习步骤
1)问题定义:预测泰坦尼克号乘客能否存活 预测模型 分类问题
2)收集数据 泰坦尼克号乘客相关信息,一定要先搞清楚数据各个字段的意义
3)数据预处理
4)模型训练
5)预测
6)完善模型
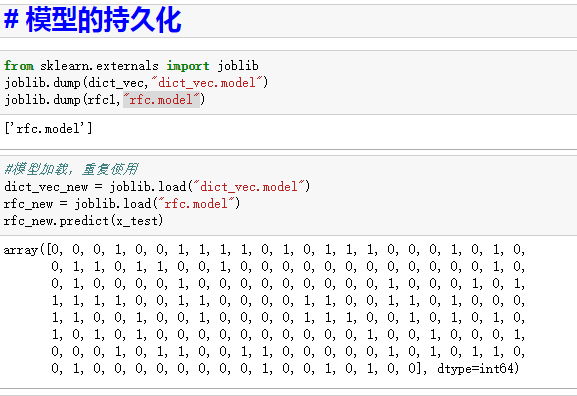
7)持久化
现在开始:
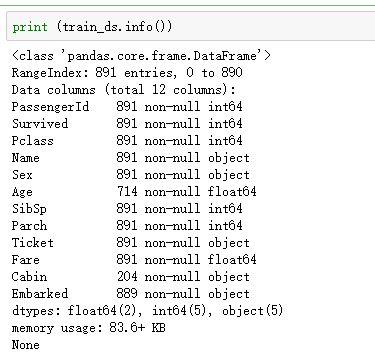
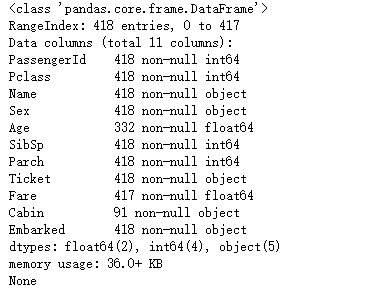
首先呢,看一下训练集和测试集的数据,主要是发现缺失值,和相关非数值变量
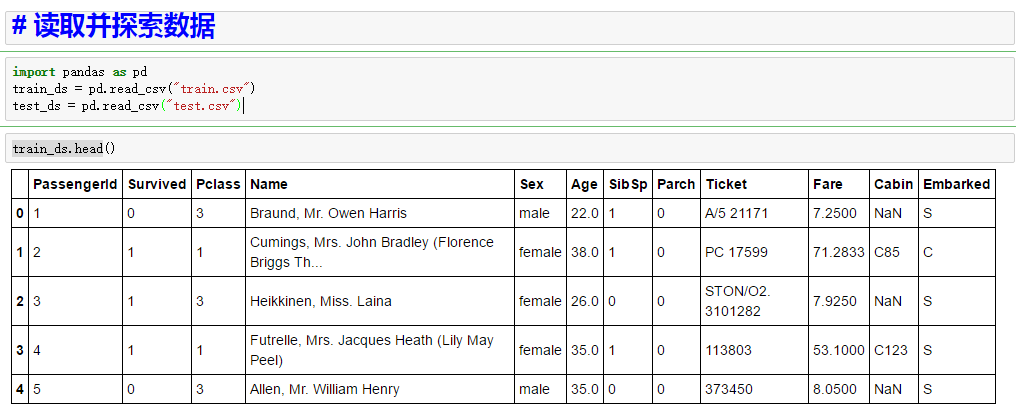
检查训练集和测试集的具体数据的情况,其实你在检查的时候就发现了,貌似在测试集,也就是下右图,没有预测所需要的Survived字段,这就没办法做比较了对吧?
请继续往下看,答案在下面:
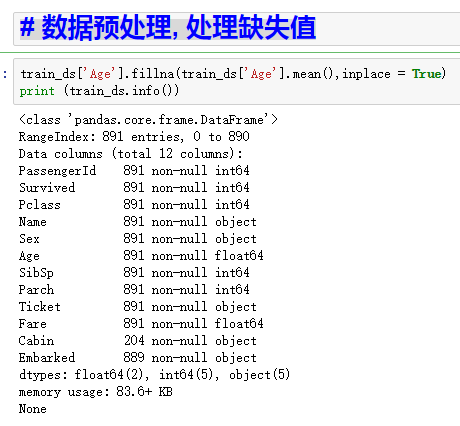
做数据预处理,可以是填充或者是舍去这些缺省值,可以跟上面对比一下,看一下哪些值发生了相关变化。

然后呢,去抽取特征, 这里呢,根据个人经验,我先假设,船舱的等级,性别和年龄与最后生存与否的可能性关系比较大
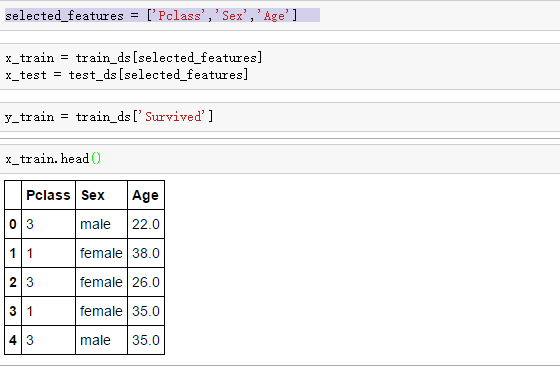
当查看x_train时候,发现有一列是非数值型的,这下面的机器算法是无法处理这个字串的,
所以,在数据预处理中也涉及到非数值型特征的转换, 这里使用是sklearn中feature_extraction这个类
把字串变成数字,可以理解为把行记录转换成特征向量,你会发现本来是三列表示一行记录,现在下图中变成了四列,这是为什么呢?

回答上面那个问题,在字串转化成数字表示的过程当中,是通过两列数值来判断一个性别的,
比如,当前这行记录是男性的话,就做如此判断'性别为女非真','性别为男真',显示为'0','1',下面的列名也可以帮助理解这一点

上面还留了个问题,就是测试集里没有预测那一列的值,也就是说即便我们模型推测出来结果,也没发作比较,所以,在原来的训练集中,我们提取80%作为训练集,20%作为测试集:
使用包做分割, 这里的0.2是个推荐值,我打算使用0.4的时候,系统提示警告,Py3的这个有限制

下面就是使用训练集训练模型,算法模型使用随机森林,可以看看下面解释

导入算法包

如果实现是想不通fit()做的是啥,就看一下help(rfc1.fit)
fit(X, y, sample_weight=None) method of sklearn.ensemble.forest.RandomForestClassifier instance
Build a forest of trees from the training set (X, y).
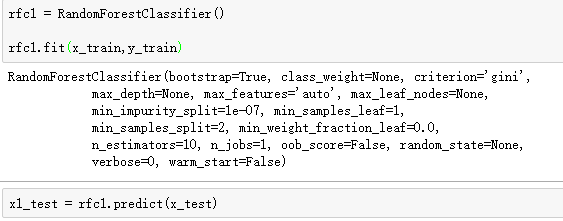
这里的x1_test是我们20%测试集的预测值,而y_test是实际值,也就是原来割裂出来的那个20%训练集的值
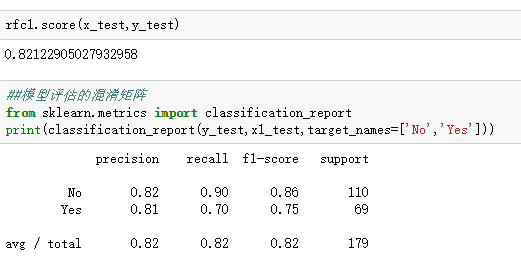
下一步,做模型评估,看看准确率,如果看更细致的评估,看看混淆模型
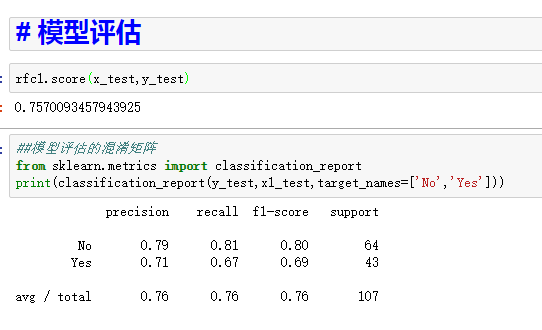

如果觉得.76的值比较低,那么我们来改进模型,比如可以加入新的特征值,
又加了三列
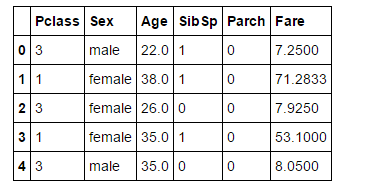
看看反应结果:大概提升了六个点