详细文章: http://www.cnblogs.com/yuanchenqi/articles/5956943.html http://www.diveintopython3.net/strings.html 需知: 1.在python2默认编码是ASCII, python3里默认是unicode 2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的
unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间 3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
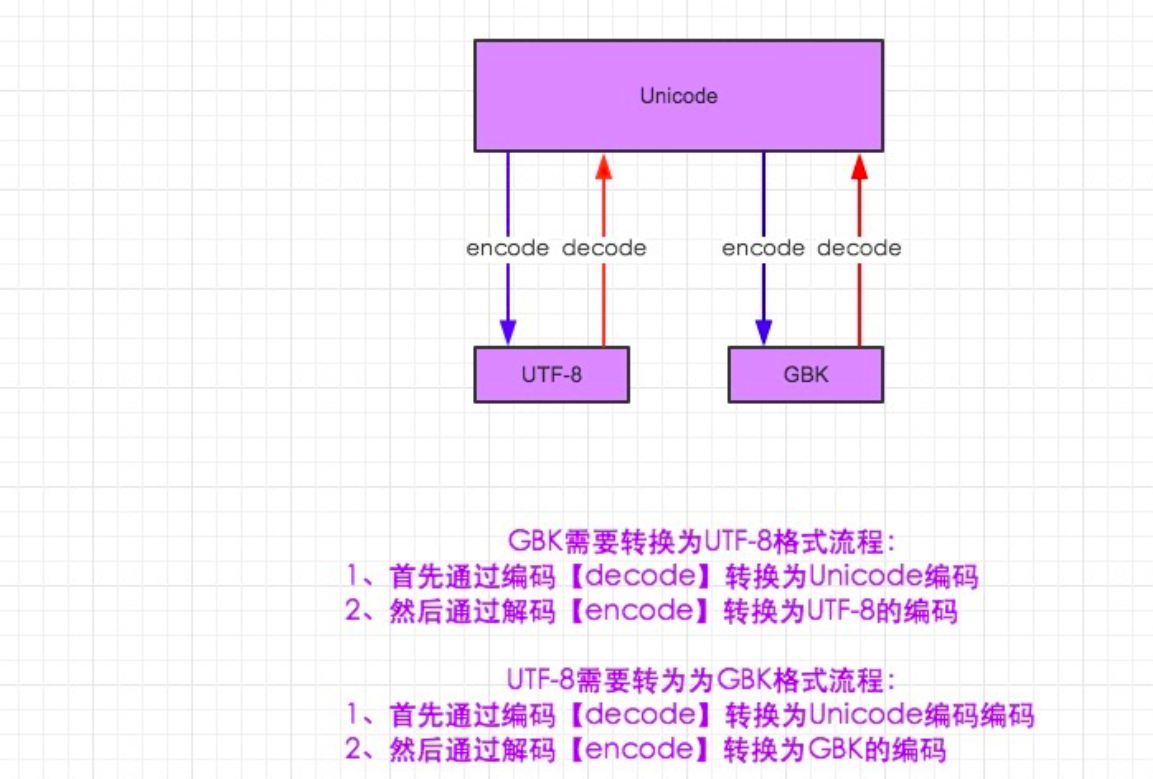
上图仅适用python2
python2:
#-*-coding:utf-8-*- __author__ = 'Alex Li' import sys print(sys.getdefaultencoding()) msg = "我爱北京" msg_gb2312 = msg.decode("utf-8").encode("gb2312") gb2312_to_gbk = msg_gb2312.decode("gbk").encode("gbk") print(msg) print(msg_gb2312) print(gb2312_to_gbk)
python 3:
#-*-coding:gb2312 -*- #这个也可以去掉 __author__ = 'Alex Li' import sys print(sys.getdefaultencoding()) msg = "我爱北京" #msg_gb2312 = msg.decode("utf-8").encode("gb2312") msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔 gb2312_to_unicode = msg_gb2312.decode("gb2312") gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8") print(msg) print(msg_gb2312) print(gb2312_to_unicode) print(gb2312_to_utf8)
4. 字符编码 先说python2 py2里默认编码是ascii 文件开头那个编码声明是告诉解释这个代码的程序 以什么编码格式 把这段代码读入到内存,因为到了内存里,这段代码其实是以
bytes二进制格式存的,不过即使是2进制流,也可以按不同的编码格式转成2进制流,你懂么? 如果在文件头声明了#_*_coding:utf-8*_,就可以写中文了, 不声明的话,python在处理这段代码时按ascii,显然会出错,
加了这个声明后,里面的代码就全是utf-8格式了 在有#_*_coding:utf-8*_的情况下,你在声明变量如果写成name=u"大保健",那这个字符就是unicode格式,不加这个u,
那你声明的字符串就是utf-8格式 utf-8 to gbk怎么转,utf8先decode成unicode,再encode成gbk 再说python3 py3里默认文件编码就是utf-8,所以可以直接写中文,也不需要文件头声明编码了,干的漂亮 你声明的变量默认是unicode编码,不是utf-8, 因为默认即是unicode了(不像在py2里,你想直接声明成unicode还得在
变量前加个u), 此时你想转成gbk的话,直接your_str.encode("gbk")即可以 但py3里,你在your_str.encode("gbk")时,感觉好像还加了一个动作,就是就是encode的数据变成了bytes里,我擦,
这是怎么个情况,因为在py3里,str and bytes做了明确的区分,你可以理解为bytes就是2进制流,你会说,我看到的不是
010101这样的2进制呀, 那是因为python为了让你能对数据进行操作而在内存级别又帮你做了一层封装,否则让你直接看到一
堆2进制,你能看出哪个字符对应哪段2进制么?什么?自己换算,得了吧,你连超过2位数的数字加减运算都费劲,还还是省省心吧。 那你说,在py2里好像也有bytes呀,是的,不过py2里的bytes只是对str做了个别名(python2里的str就是bytes, py3里的
str是unicode),没有像py3一样给你显示的多出来一层封装,但其实其内部还是封装了的。 这么讲吧, 无论是2还是三,
从硬盘到内存,数据格式都是 010101二进制到-->b'xe4xbdxa0xe5xa5xbd' bytes类型-->按照指定编码转成你
能看懂的文字 编码应用比较多的场景应该是爬虫了,互联网上很多网站用的编码格式很杂,虽然整体趋向都变成utf-8,但现在还是很杂,
所以爬网页时就需要你进行各种编码的转换。