0.问题
-
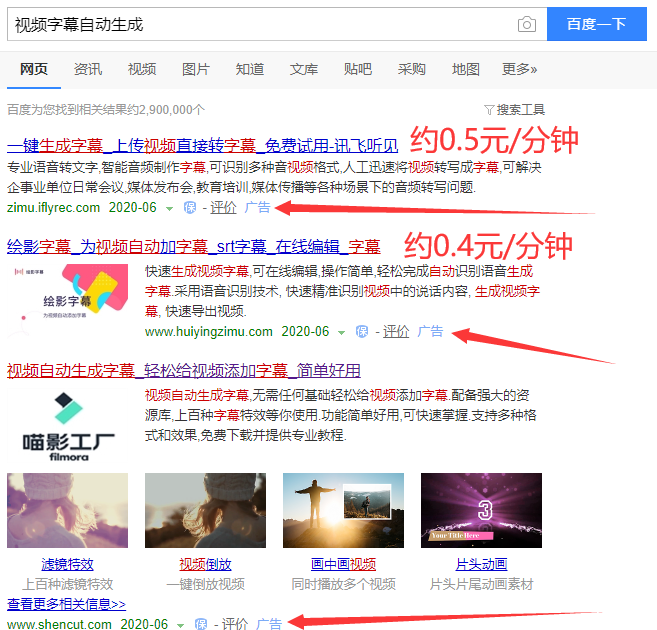
经常要剪视频,有时候自己讲的希望能加个字幕,但是网上基本都是收费的,而且对于我这种做视频没什么收入的UP主来说有点贵了。所以一直在寻找一个便捷一点的或者说省钱一点的方法。
-
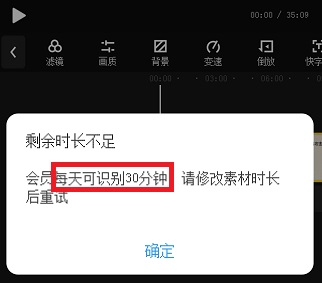
但是手机上发现有个软件效果还不错,每天免费30分钟:

显示是会员有30分钟,会员就是注册一下。
- 快剪辑快字幕功能操作流程如下
-
新建项目

-
选择要生成字幕的视频

-
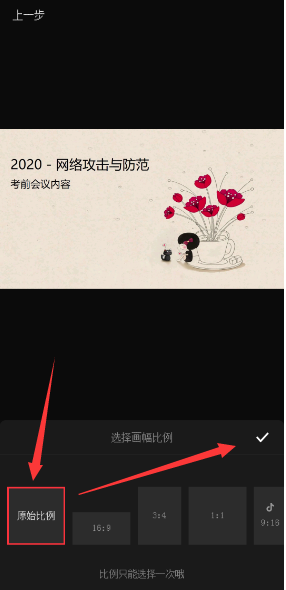
选择原始比例(可以随便)
-
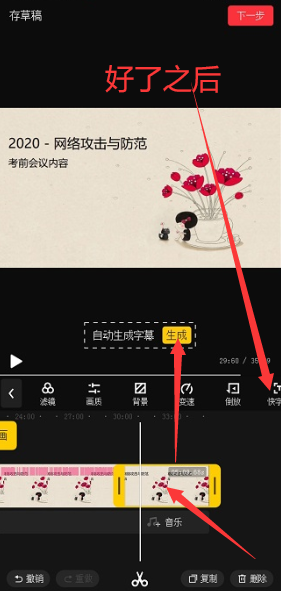
选择一段要自动生成字幕的片段点生成
-
编辑调整字幕
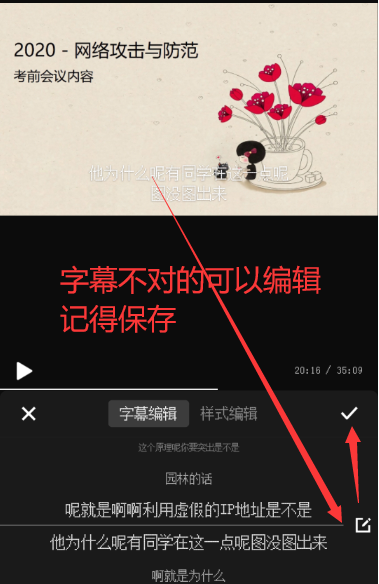
其实到这里的话已经可以生成字幕达到目的了,但是快剪辑的字幕生成慢,而且不好剪辑,想导出到srt字幕文件到电脑上一起完成剪辑。
1.解决
- 在应用存储文件夹下找到了这个文件
里面的内容,疑似json保存的项目工程文件
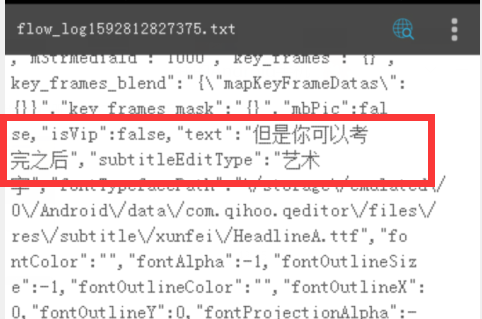
用JSON格式化工具看发现,字幕是在stickerlist属性下的text属性,开始和结束时间分别是startTime属性和endTime属性,时间是视频开始到当前的毫秒数。

- 于是我利用这个文件,用Python写了一个提取字幕的脚本
#!/usr/bin/python
# coding=UTF-8
import json
import time
import srt
from datetime import timedelta
def FlowlogToSrt(log):
#解析Json为字典
fldict = json.loads(log)
#获取字幕列表
stickerlist = fldict['stickerlist']
#取出字幕
index = 0
subs = []
for sticker in stickerlist:
#序列号
index = index + 1
#开始时间
startTime = timedelta(milliseconds = sticker["startTime"])
#结束时间
endTime = timedelta(milliseconds = sticker["endTime"])
#内容
text = sticker["text"]
#转成srt对象,并存入列表
subs.append(srt.Subtitle(index=index, start=startTime, end=endTime, content=text))
#转成srt
srtText = ""
for sub in subs:
srtText = srtText + sub.to_srt()
print(srtText)
#写入文件
filename = "KuaiJianJiSticker"+time.strftime("%Y_%m_%d_%H_%M_%S", time.localtime())+".srt"
with open(filename, 'w', encoding="utf-8") as file_object:
file_object.write(srtText)
if __name__ == "__main__":
txt = input("请输入手机快剪辑flowlog数据:(数据位于/Android/data/com.qihoo.qeditor/files/keyfiles/flowlog下)
")
FlowlogToSrt(txt)
-
把那个文件上传到电脑,输入到代码里
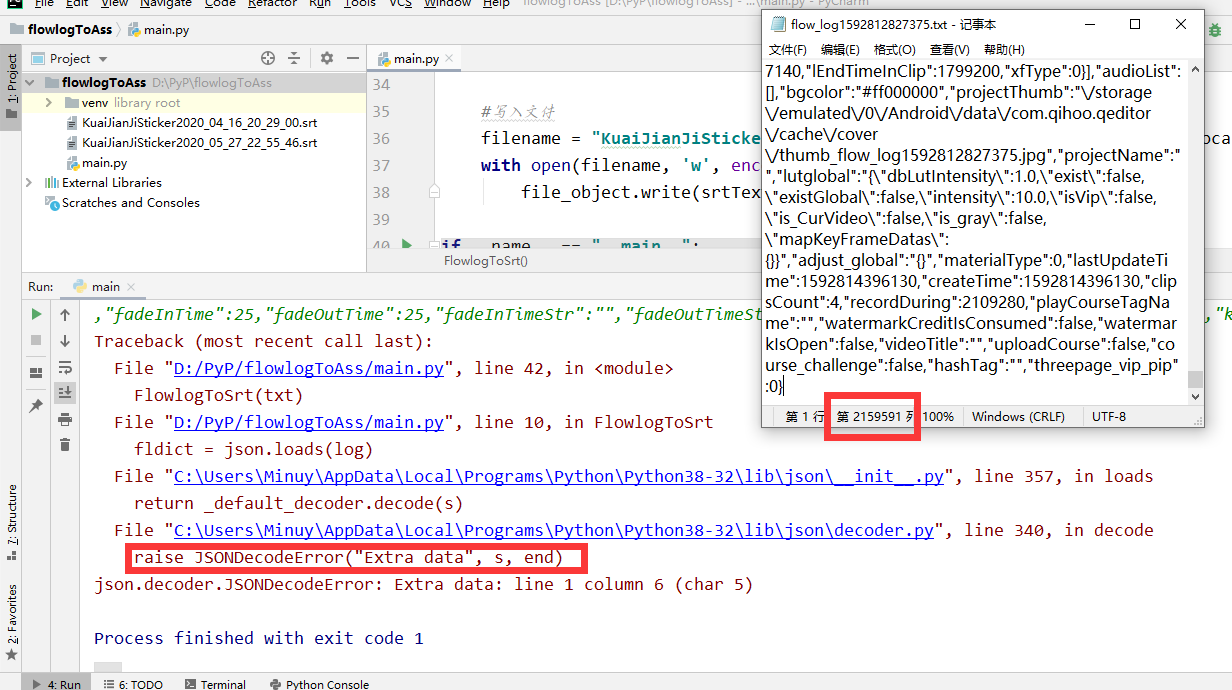
但是好像文件太大了,因为我的是35分钟的会议,基本都有人在说话。 -
那只好提取出有用的部分咯
于是在JSON在线格式化这里格式化了一下代码,把结果放到另外一个文件里。
用Java写了以下代码,用于提取出大致的JSON结构和所需要的部分属性:
package clearJSON;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
public class Main {
//文件路径
static String Path = "D:/eclipse-workspace/clearJSON/clearJSON/json.txt";
//结果缓存
static StringBuilder res = new StringBuilder();
public static void main(String[] args) throws IOException, InterruptedException {
//行数统计
int lineNumber = 0;
//读取文件
FileInputStream fis=new FileInputStream(Path);
InputStreamReader isr=new InputStreamReader(fis, "UTF-8");
BufferedReader br = new BufferedReader(isr);
String line = "";
while ((line=br.readLine())!=null) {
lineNumber++;
//结构保留
if(line.indexOf('{')!=-1 || line.indexOf('}')!=-1) {
add(line);
//保证添加的不是空对象
if((line=br.readLine())!=null) {
//结构里至少有一个属性,添加以“{”开头的下一行
add(line);
}
continue;
}
//属性保留,需要的属性可以以此类推添加到这里
if(line.indexOf(""startTime"")!=-1 || line.indexOf(""text"")!=-1 || line.indexOf(""endTime"")!=-1) {
add(line);
}
}
br.close();
fis.close();
//输出结果
System.out.println("一共处理文件行数:"+lineNumber);
//输出精简后的JSON代码
Thread.sleep(2000);
System.out.println(res.toString());
}
/**
* 添加文本到缓存里
* 完成对结构的判断,依靠‘}’在第一个字符判断是一组属性的结尾,
* 然后删除上一行行末的‘,’
* @param str 要添加的文字
*/
public static void add(String str) {
//判断是不是一组属性的结尾
if(str.trim().indexOf('}') == 0) {
//删除上一行行末的逗号
res.deleteCharAt(res.length()-1);
}
//添加到缓存
res.append(str);
}
}
-
把JSON代码精简到了原来大小的8.6%:
-
之后再输入到Python里。
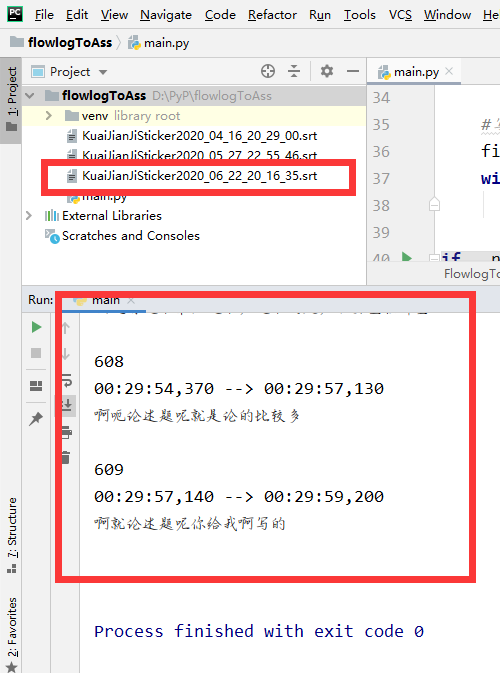
成功生成SRT文件! -
导入到ARCTIME中:
成功导入到ARCTIME中!
2.总结
- 基本完成了需求,但是步骤有些麻烦。
- 今后可以尝试合并Java和Python的部分。
- 写这篇文章的原因主要还是没钱。