记录一些破碎的,有意思的SQL片段
大都是日常工作中使用到的,但具体的业务场景也都记不清了,从有道云笔记的记录中扒拉出来,仅作记录使用
MySQL部分
MySQL 5.7版本实现分组取topN
Hive,Oracle等数据库系统都有row_number等函数,对于实现分组取topN之类的操作,都很简单,MySQL8.x也实现了row_number,rank等诸多函数,但对于5.7版本来说,并没有实现该功能,但又不会写存储过程,故鼓捣出下面的这个版本,仅供参数
-- 该功能实现的其实是 分组后,再分别去掉几个最高值,去掉几个最低值,然后再取平均数
select
prov_id,avg(data_size_all)
from (
select
a.prov_id,a.data_size_all,a.daily_date,a.type,count(b.prov_id)
from lf_zb_src_prov_d_quality_daily_anylize a
left join lf_zb_src_prov_d_quality_daily_anylize b
on a.prov_id = b.prov_id and a.type=1 and b.type=1 -- 关联条件,不用管
and a.daily_date < b.daily_date -- 该条件是不等值连接,会导致关联多次,下面用这个次数进行取topN
where a.type=1 and b.type=1 -- 筛选条件,不用管
group by a.prov_id,a.data_size_all,a.daily_date,a.type -- 分组条件
having count(b.prov_id)<7 -- 取得是关联次数小于7次的,再多加几个,即可实现掐头去尾取平均值
order by a.prov_id,a.daily_date
) c
group by c.prov_id
实现累加需求
公司建模组的小姐姐来问了个问题:要计算一个用户的一年内的话费累积额,也就是说他1月份花了100,二月份花了100,则出的结果是1月份100,2月份累计,是200,以此类推
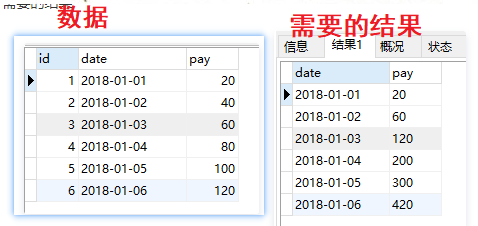
-- 以下方案是百度后实现的,不记得是哪位大佬的方案了,只有但是把方案记录在有道里,特此记录一下
实现一:
select t.*
,(select sum(price) from t_charge temp where temp.date <= t.date) as total_price
from t_charge t
group by t.id;
实现二:
select t.*, sum(temp.price) as total_price
from t_charge t,t_charge temp
where t.date <= temp.date
group by t.id;
group_concat的用法:分组后组内的全部concat起来
这一条隐约记得应该是计算所有延迟的省份数量,数据量变化在10%之上的省份列出来,其原始表结构以及忘记了,仅作为记录group_concat使用的案例
SELECT
daily_date AS "time",
sum(case when delay_data_hour>=1 then 1 else 0 end) as delay_num,
sum(case when remark is not null then 1 else 0 end) as repari_data_num,
sum(case when datasize_charge >= 0.1 then 1 else 0 end ) as charge_num,
GROUP_CONCAT(case when delay_data_hour>=1 then prov_name else null end,' ') as delay_prov_name,
GROUP_CONCAT(case when remark is not null then prov_name else null end,' ') as repair_prov_name,
GROUP_CONCAT(case when abs(datasize_charge)>=0.1 then prov_name else null end,' ') as charge_prov_name
FROM lf_zb_src_prov_d_quality_daily_anylize
WHERE
now_date = DATE_FORMAT(DATE_SUB(CURDATE(), INTERVAL 2 day),'%Y-%m-%d')
and prov_name != '全国汇总'
group BY time
----------------------------------------------------------------------------
time |delay_num |repari_data_num |charge_num |delay_prov_name |repair_prov_name |charge_prov_name |
-----------|----------|----------------|-----------|--------------------|--------------------------|--------------------|
2019-02-25 |5 |5 |4 |河南 ,广西 ,海南 ,福建 ,安徽 |黑龙江 ,辽宁 ,吉林 ,,福建 ,浙江 ,江苏 ,上 |
数据做了部分修改
一个不同的合并方式
昨晚加班到很晚,建模组的小姐姐又来难为我了
小姐姐:要实现下面的结果。
我: 为啥要有这么与众不同的需求
小姐姐:你就说能不能干吧?
我:这还不简单嘛!

select id,max(c_1) ,max(c_2) from(
select ta.id,ta.c_1 as c_1 ,null as c_2 from table_a ta
union
select tb.id ,null as c_1,tb .c_2 from table_b tb
)a
group by id
其内层结构如下

应该还有其他方法,暂时还未想到,记录一下
MySQL使用select出来的值进行更新
该需求的场景是,我们要把Hive元数据里的表,全部同步一份到我们公司的项目平台上,项目平台的表分为table_info表,column_info表,partition_info表,现在各表都已经同步完毕。但是1.0版本的检索使用的是table_info中的full_search字段(2.0版本是使用elasticsearch解决),所以现在需要先更新该字段。
-- 使用了group_concat和使用select出来的值,进行join关联后更新,表结构记不得了,只有笔记了,记录下思路,以备他日之需
SET SESSION group_concat_max_len = 102400; -- 修复concat_ws过长被截断
UPDATE unicom_advanced.ubd_table_info t4 INNER JOIN
(
select
table_id,concat(replace(a,char(13),''),replace(b,char(13),'')) as full_search
from (
select
t1.table_id,
concat(t1.table_code,'|',t1.table_name,'|',t1.desc_info,'|',t1.table_business_desc,'|') a,
group_concat(t2.column_name,t2.column_code,'|',t5.partition_code,'|',t5.partition_name) as b
from unicom_advanced.ubd_table_info t1
left join unicom_advanced.ubd_column_info t2
on t1.table_id = t2.table_id
left join unicom_advanced.ubd_partition_info t5
on t1.table_id = t5.table_id
-- where t1.table_id in (1363372844563160069,1363372844563160581,1363372844563160837,1363372844563161605,1363372844563160070,1363372844563160582)
group by t1.table_id
)c
group by table_id
) as t3
ON t4.table_id=t3.table_id
set t4.full_search=t3.full_search;