在公司第二次写spark任务的时候,跑一小时的数据,大概4000万条客户端请求,因为使用了groupby统计客户端版本分布,结果任务先后出现了time out, out of memory异常(有时候成功,有时候失败)。
学习笔记:
他们都是要经过shuffle的,groupByKey在方法shuffle之间不会合并原样进行shuffle,。reduceByKey进行shuffle之前会先做合并,这样就减少了shuffle的io传送,所以效率高一点。
我的spark任务每次跑4000万条数据,
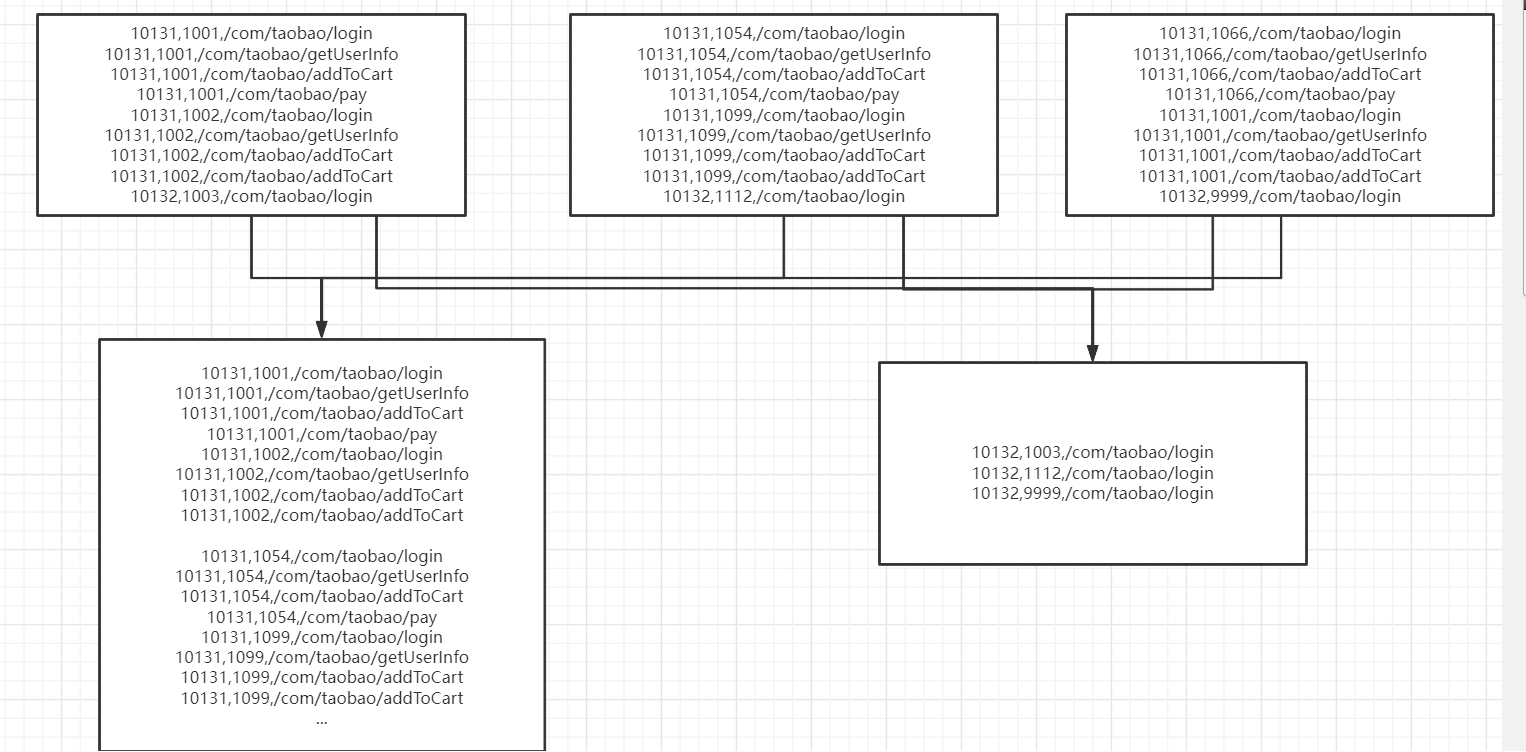
HDFS存的数据结构:
versionCode,userId,url
比如:10131,1001,/com/andy/login
下面是我的真实数据进行groupby导致的问题,10131的应用版本,有2000多万的数据,10132只有几十万数据,导致在groupby的时候,有时候传输超时,有时候内存溢出。
参考资料:
https://blog.csdn.net/qq_38799155/article/details/80178022